2.1 关系型数据库缺少联系
图数据库
数十年来,开发者试图使用关系型数据库处理关联的、半结构化的数据集。关系型数据库设计之初是为了处理纸质表格以及表格化结构—有些方面关系型数据库做得非常好—它们试图对这种实际中的特殊联系进行建模。然而讽刺的是,关系型数据库在处理联系上做得却并不好。
联系确实存在于关系型数据库自身的术语中,但只是作为连接表的手段。前面章节在对关联数据的讨论中曾经提到,我们经常需要对连接实体的联系进行语义的区分,同时限制它们的使用。关联关系什么也做不了。更糟糕的是,随着离群数据(outlier data)的成倍地增加,数据集的宏观结构将愈发复杂和不规整,关系模型将造成大量表连接、稀疏行和非空检查逻辑。关系世界中连通性的增强都将转化为连接操作的增加,这会阻碍性能,并使已有的数据库难以响应变化的业务需求。
图2-1展示了一个以客户为中心的、事务型应用程序存储顾客订单的关系模式(relational schema)。
这种schema的设计对该应用程序产生了很大影响,使有些查询非常简单,而有些异常困难。
表连接增加了偶发复杂性,使得业务数据与外键元数据混杂起来。
外键约束增加了额外的开发与维护成本,而目的仅仅是为了让数据库工作。
带有空值列的稀疏表在代码中需要额外检查,尽管schema本身提供了相关 支持。
仅因为想要查看客户买了什么就需要好几个昂贵的连接。
反向查询(reciprocal query)代价更高。查询“客户买了哪些商品?”比查询“有哪些客户买了这个商品?”的代价相对要低,这就是推荐系统的基础。对于这样的需求,可以引入索引(index),然而即使引入索引,“有哪些买了那个商品的客户还买了这个商品?”随着递归程度的增加,递归问题的查询代价变得异常高昂。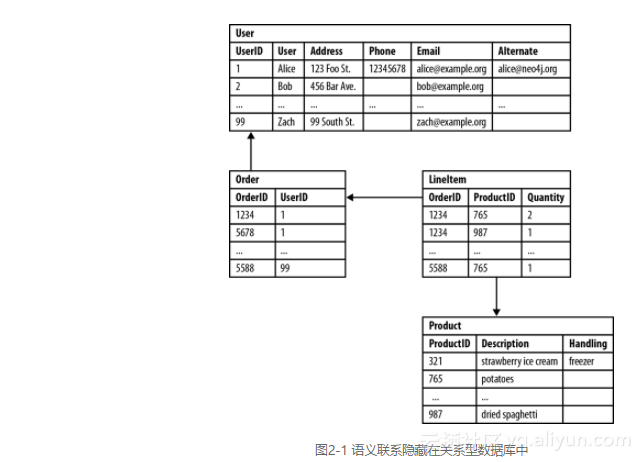
关系型数据库在强关联领域做着斗争。让我们通过社交网络领域中一些简单的和不那么简单的查询来理解关系型数据库中关联查询的成本吧。
图2-2展示了一个记录朋友关系的简单的连接表设计。
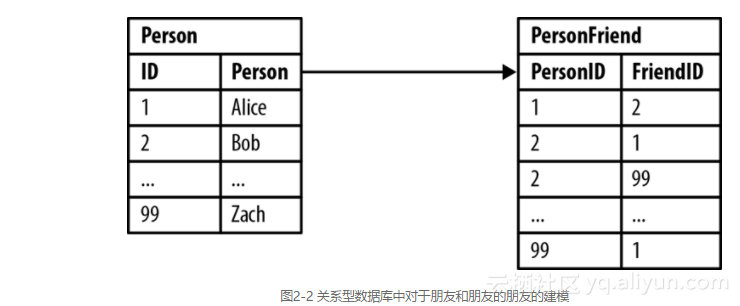
回答“谁是Bob的朋友?”这个问题很简单,如示例2-1所示。
示例2-1 Bob的朋友
SELECT p1.Person
FROM Person p1 JOIN PersonFriend
ON PersonFriend.FriendID = p1.ID
JOIN Person p2
ON PersonFriend.PersonID = p2.ID
WHERE p2.Person = 'Bob'
基于这个示例数据,答案是Alice和Zach。这不是一个代价高昂或困难的查询,因为它使用了WHERE Person.person='Bob',使得返回的行数是可预期的和有限的。
朋友关系不总是自反关系(reflexive relationship),因此在示例2-2中,需要回答示例2-1的反向查询:“谁是Bob的朋友?”
示例2-2 谁的朋友是Bob
SELECT p1.Person
FROM Person p1 JOIN PersonFriend
ON PersonFriend.PersonID = p1.ID
JOIN Person p2
ON PersonFriend.FriendID = p2.ID
WHERE p2.Person = 'Bob'
这个查询的答案是Alice,很遗憾Zach不认为Bob是他的朋友。这个反向查询在实现上也很简单,但是数据库端的花销就略微大些了,因为所有的数据行都在表PersonFreiend中。
我们可以加入索引,然而仍会涉及代价高昂的间接层。当问题是“谁是我的朋友的朋友?”时就更麻烦了。SQL的层级结构使用了递归连接,这使得查询语法和计算都更加复杂,如示例2-3所示。(有些关系型数据库提供这种查询的语法糖—比如Oracle提供了函数CONNECT BY,它可以简化查询语句,但并不能降低底层的计算复杂度。)
示例2-3 Alice的朋友的朋友们
SELECT p1.Person AS PERSON, p2.Person AS FRIEND_OF_FRIEND
FROM PersonFriend pf1 JOIN Person p1
ON pf1.PersonID = p1.ID
JOIN PersonFriend pf2
ON pf2.PersonID = pf1.FriendID
JOIN Person p2
ON pf2.FriendID = p2.ID
WHERE p1.Person = 'Alice' AND pf2.FriendID <> p1.ID
即使只是处理Alice的朋友的朋友们,而不是深入Alice的整个社交网络,这个查询计算也很复杂。当我们试图探究社交网络时,问题则更复杂,代价也更高。虽然“谁是我的朋友的朋友们?”这样的问题还是可能在合理的时间内通过查询得到答案,但是当查询延伸到第4度、第5度或第6度的朋友关系时,由于递归的连表查询使此时的时间空间复杂度非常高,从而使查询的效率严重恶化。
无论试图在关系型数据库中对关联建模还是查询关联,结果都与我们的愿望完全不同。除了之前指出的查询和计算复杂度以外,我们还得去处理schema这个双刃剑。很多时候,schema被证明是死板和脆弱的。死板表现在:我们需要在创建稀疏表的同时在代码中处理异常情况—一切只是因为没有一个能够容纳我们所用到的各类数据的通用的schema。这在增加了耦合的同时也摧毁了其貌似存在的凝聚力。脆弱表现在:当应用程序发生变化时,需要增加额外的工作从一个schema迁移到另一个schema。
本文仅用于学习和交流目的,不代表异步社区观点。非商业转载请注明作译者、出处,并保留本文的原始链接。