之前有关于SLIC Superpixel算法的个人理解,这篇文章是对其改进算法Improved SLIC算法的理解。
改进点:
- sigma filter 用来避免错误分割;
- 聚类结束后,会基于颜色相似度将小聚类融入临近的聚类中。
改进聚类中心
原SLIC算法
使用平均值更新聚类中心
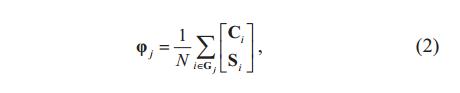
Improved SLIC算法
采用如下方法更新聚类中心,对应于改进点1:
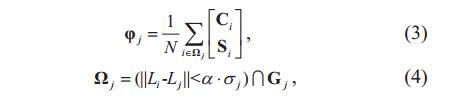
其中δ_j表示,属于该聚类的所有像素点的亮度L的标准差,α是一个常数。
改进点2
原来的SLIC算法中,在进行迭代聚类后,得到一些小的聚类,这些聚类会被融入它们的最大临近聚类中,改进后的算法,这些小的聚类也会被融入到临近的聚类中,但是不是基于原来的聚类尺寸进行选择,而是基于亮度相似性进行选择,(对应于改进点2):
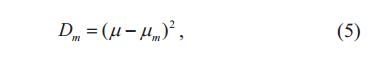
亮度相似性D_m通过上式得到,其中,μ和μ_m分别表示小聚类和它的临近聚类的亮度平均值,令D_q表示某个小聚类的所有D_m值中的最小值,设置阈值T,如果D_q< T,则这个小聚类将被融入它的第q个临近聚类中;否则,该小聚类保持独立。
时间: 2024-09-17 23:51:57