
MapReduce处理过程总览
对于MP的处理过程我想大部分人都已经知道了其原理,思路不难,这是肯定的,但是整个过程中需要考虑的细枝末节的点还挺多的,MP的输入输出格式就是其中的一点,那本文就带领大家看看MP中的格式设置问题。
map函数,起到了如下的转换作用:map:(k1,v1)—>list(k2,v2)
reduce 函数,则起到了这样的格式转换作用:reduce:(k2,list(v2))—>list(k3,v3)
怎么,你说你看不懂?那看来你还是没有对mapreduce的过程有所理解,看看这幅图,不需要解释,你就明白上面的格式转化是什么意思了:
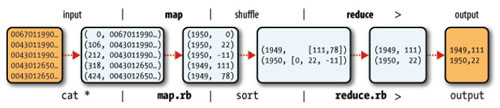
上面这幅图出自我的另外一篇博文:编写自己的第一个Hadoop实例,如果你设置了combiner函数,那么中间的格式转化将会是这个样子:
- map:(k1,v1)—>list(k2,v2)
- combiner:(k2,list(v2))—>list(k2,v2)
- reduce:(k2,list(v2))—>list(k3,v3)
是的,没错,combiner从功能上来讲就是一个reducer,它的存在大大减小了reducer的压力。
partition函数对中间结果(k2,v2)进行处理,返回一个索引值,即分区号
- partition:(k2,v2)—>integer
在前面的文章中,也就是我的博客:MapReduce输入分片详解中,我提到了分片是与map函数数量相等,同时它不是咱们想的那样是一个实物分片,在程序上输入分片在java中表现为InputSplit接口
- public abstract class InputSpilt{
- public abstract long getLength();
- public abstract String[] getLoacations();
- }
存储位置供mapreduce使用,以便使map任务尽量在分片附近。分片大小是用来对分片进行排序,以便优先处理最大的最大分片,从而最小化时间。InputSplit不需要MR开发人直接处理,而是由InputFormat创建。
客户端通过调用InputFormat的getSplits()计算分片,然后将他们送到application master(或jobtracker),am使用存储位置信息调度map任务在tasktracker上处理这些分片数据。map任务把输入分片传递给InputFormat的getRecordReader()方法来获得这个分片的RecordReader。RecordReader类似迭代器,对map任务进行迭代,来生成键/值对,然后传递给map函数。也就是说InputFormat不仅仅可以计算分片,进行数据分割,还可以对分片进行迭代,也就是说获得分片的迭代器,所有有关分片的操作都由InputFormat来支持,可见其强大性。
输入格式
那既然InputFormat这么牛逼,那我们就来看看这个接口到底包含了什么,先来看看下面这张图:
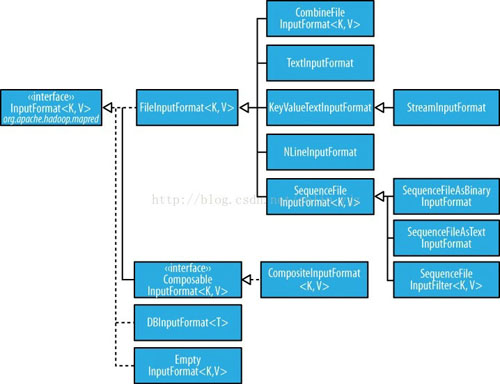
FileInputFormat类
FileInputFormat是所有文件作为数据源的InputFormat的实现类,主要有两个功能:指定输入文件位置和输入文件生成分片的实现代码段。换句话说,它并不生成分片,只是返回文件位置,并且实现了分片算法。
FileInputFormat指定输入路径
- addInputPath(Job job,Path path);
- addInputPaths(Job job,String paths);
- setInputPaths(Job job,Path ...inputPaths);
可以添加一个路径或者多个路径,其中setInputPaths是以此设定完成的路径列表。其中路径可以是一个文件、一个目录、或者一个glob(通配,通过通配符来获取路径),当路径是一个目录的时候表示包含目录下的所有文件。当目录中包含目录的时候,这个目录也会被解释称文件,所以会报错。可以通过使用一个文件glob或者一个过滤器根据命名模式限定选择目录中的文件。还可以通过设置属性mapred.input.dir.recursive为true强制对目录进行递归读取。如果需要排除目录中的个别文件,可以通过setInputPathFileter()设置一个过滤器来进行过滤,如果不设置过滤器,也会有默认的过滤器排除隐藏文件(以.和_开头的)。路径和过滤器业可以使用配置文件进行配置:mapred.input.dir和mapred.input.path.Fileter.class
小文件处理
(小文件是指比HDFS块小很多)在Hadoop中使用小文件的弊端:
(1)、增加map开销,因为每个分片都要执行一次map任务,map操作会造成额外的开销
(2)、MapReduce处理数据的最佳速度就是和集群中的传输速度相同,而处理小文件将增加作业的寻址次数
(3)、浪费namenode的内存
解决方法:
使用SequenceFile将这些小文件合并成一个大文件或多个大文件:将文件名作为键,文本内容作为值。
但是如果HDFS中已经存在的大批小文件,可以使用CombinerFileInputFormat。
CombinerFileInputFormat把多个文件打包成一个文件以便每个mapper能够处理更过的数据
避免切分
有时候不需要将文件进行切分,mapper完整处理每个输入文件。例如检查一个文件的所有记录是否有序。
可以通过设置最小分片大小大于要处理的文件。第二种就是使用FileInputFormat的具体子类,并且重载isSplitable()方法,把返回值设置为false。
mapper中的信息
通过调用Mapper中的Context的getInputSolit()返回一个InputSplit,如果使用的是FileInputFormat,则可以强转为FileSplit,然后用此访问正在输入文件的路径getPath(),分片开始处的字节偏移量,getLength()分片的长度。
TextInputFormat
文本输入是默认的InputFormat,每条记录是一行输入,键是LongWritable类型,存储该记录在整个文件的字节偏移量。值是该行的内容,不包括终止符(回车、换行等),它被打包成Text对象。
KeyValueTextInputFormat
当文件中的每一行是一个键/值对,使用某个分界符进行分割,如制表符。可以通过mapreduce.input.keyvaluelinerecordreader.key.value.seperator属性来指定分隔符。默认是一个制表符。其中这个键是分隔符前的文本,值是分隔符后的文本,其类型都是Text类型。如:
- line1:this is line1 text
- line2:this is line2 text
则被分为两条记录,分别是:
- (line1,this is line1 text)
- (line2,this is line2 text)
NLineInputFormat
在TextInputFormat和KeyValueTextInputFormat中,每个mapper收到的输入行数并不确定,行数取决于输入分片的大小和行的长度。如果希望mapper收到固定行数的输入,可以使用NLineInputFormat作为InputFormat。与TextInputFormat奕扬,键是文件中行的字节偏移量,值是行的内容。
N是每个mapper收到的输入行数,默认是1。可以通过mapreduce.input.lineinputformat.linespermap属性设置。如:
On the top of the Crumetty Tree
The Quangle Wangle sat,
But his face you could not see,
On account of his Beaver Hat.
当N为2的时候,每个输入分片包含两行。
(0,On the top of the Crumetty Tree)
(33,The Quangle Wangle sat,)
另一个mapper则收到后两行
(57,But his face you could not see,)
(89,On account of his Beaver Hat.)
StreamInputFormat
当解析XMl文件的时候可以使用StreamInputFormat,将stream.recordreader.class属性设置为org.apache.Hadoop.Streaming.StreamXmlRecordReader使用StreamXmlRecordReader类。具体实现(没用过)可以查看该类官方文档
SequenceFileInputFormat
Hadoop顺序文件格式存储二进制的键/值对的序列。当需要使用顺序文件作为MapReduce的输入时,应该使用SequenceFileInputFormat。键和值由顺序文件指定,只需要保证map输入的类型匹配。
SequenceFileAsTextInputFormat
SequenceFileAsTextInputFormat是SequenceFileInputFormat的变体,将顺序文件的键和值转化为Text对象。
SequenceFileAsBinaryInputFormat
SequenceFileAsBinaryInputFormat是SequenceFileInputFormat的一种变体,获取顺序文件的键和值作为二进制对象。
MutipleInputs
一个MapReduce作业可能由多个输入文件,但所有文件都由同一个InputFormat和同一个mapper来处理。但是数据格式却有所不同,需要对不同的数据集进行连接操作。可以使用MutipleInputs类处理
DBInputFormat
DBInputFormat用于使用JDBC从关系数据库中读取数据。需要注意在数据库中运行太多mapper读取数据,可能会使数据库受不了,所以一般使用DBInputFormat加载少量数据。可以现将数据导入到HDFS中,一般将关系性数据库中数据导入到HDFS中可以使用Sqoop
输出格式
TextOutputFormat
默认的输出模式TextOutputFormat,每条记录写为一行。键和值是任意的,因为TextOutputFormat都要将其toString()转换为字符串。键值默认使用制表符分割,可以使用mapreduce.output.textoutputformat.separator属性改变分割符
SequenceFileOutputFormat
将输出写为一个顺序文件,当输出需要作为后续的MapReduce输入的时候,这种输出非常合适,因为它格式紧凑,容易被压缩。
SequenceFileAsBinaryOutputFormat
SequenceFileAsBinaryOutputForamt与SequenceFileAsBinaryInputFormat对应,将输出的键和值作为二进制格式写到SequenceFile容器中。
MultipleOutputFormat
有时候可能需要将每个reduce输出多个文件,可以使用MutltipleOutputFormat。
LazyOutputFormat
延迟输出,他是封装输出格式,可以保证指定分区第一条记录输出时才真正创建文件。
本文作者:牧师-Panda
来源:51CTO