DeepMind与来自普林斯顿、NYU、达特茅斯学院、UCL和哈佛大学的研究人员合作,探索了人类行为中的强化学习,为开发智能体强化学习提供了新的策略。研究人员具体探讨了一种存在于无模型和基于模型的学习算法之间的方法,基于后继表示(successor representation,SR),将长期状态预测存入缓存中。作者预计,这些发现将为计算科学、电生理学和神经影像学研究开辟新的途径去研究评估机制的神经基础。相关论文《The successor representation in human reinforcement learning》日前在Nature子刊《自然-人类行为》上发表。
人类和其他动物在不断变化的环境中适时适机进行决策,这底层的算法是什么?发现其中的机制对于完成序列决策(比如国际象棋和迷宫导航)尤其重要。
过去20年,大部分致力于解决多步骤问题的研究,都关注强化学习(RL)的两类算法,即无模型(MF)和基于模型的(MB)算法。
MF和BM都将决策形式化为长期奖励预期与不同的候选行动之间的关系,但在表示(representation)和计算方面却不尽相同。
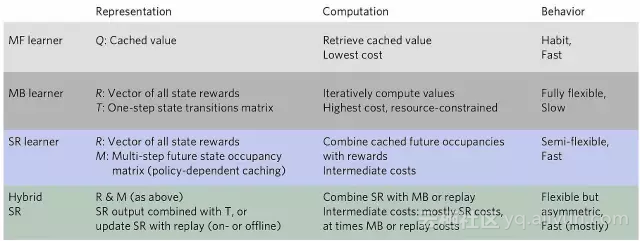
突1:无模型、基于模型和基于后继表示的学习算法在表示、计算和行为上的特点对比。来源:论文
MF vs. MB两者的对立使人产生了这样一种观点,那就是在决策的速度和准确性之间有明显的tradeoff:MF将预计算长期行动值直接存储起来,而MB算法则更加灵活,会通过对短期环境的建模来重估行动值,但这样对计算力有更大需求。
长期以来,由于这种速度和精度之间的tradeoff,人们一直以为要实现自主化、仔细思考(deliberation)和控制,需要消耗很多计算资源。同时,MF也被视为适应不良习惯和强迫行为(比如吸毒)的原因。
尽管有实验证明人类和其他动物在某些情况下的决策能够彻底打败MF选择,但极少有证据表明人类大脑是如何进行MB重计算的,甚至人类大脑究竟有没有进行MB重计算。
实际上,在MF和MB之间完全可以有其他的计算路径(shotcut)来合理解释很多现有的实验结果。
为此,普林斯顿、NYU、达特茅斯学院、DeepMind兼UCL以及哈佛大学的研究人员,设计了两项实验,探索了大脑决策时是否使用了存在于MF和MB之间的算法,以及这种算法与MF、MB之间的异同。相关论文《The successor representation in human reinforcement learning》日前在Nature子刊《自然-人类行为》上发表。
研究人员发现,人类决策时确实会用到MF和MB之间的中间算法。他们在论文中具体研究了其中的一类重要算法,基于后继表示(successor representation,SR),将长期状态预测存入缓存中。作者预计,这些发现将为计算科学、电生理学和神经影像学研究开辟新的途径去研究评估机制的神经基础。
具体说,研究人员通过实验设计,区分使用SR和MB的计算,重点关注人类是否存储了有关未来状态的长期预期。结果发现,MF策略不存储状态的任何表示,并且在决策时也不计算状态表示(参见图1和图2)。另一方面,MB策略存储并且会检索一步表示(one-step representations),因此决策时间的计算需求会更高。然而,SR缓存了一个多步骤转换的“粗略映射”到智能体以后期望访问的状态。在决策时使用这些缓存的表示,SR在奖励重估中做出了比MF更好的决策,但不能解决转移重估,而MB在所有重新估值方面都做得一样好。另一种可能性是将SR与其他策略相结合,也即论文中所说的“混合SR策略”。混合SR策略可以将半计算的轨迹粗略表示与MB表示或重放相结合。
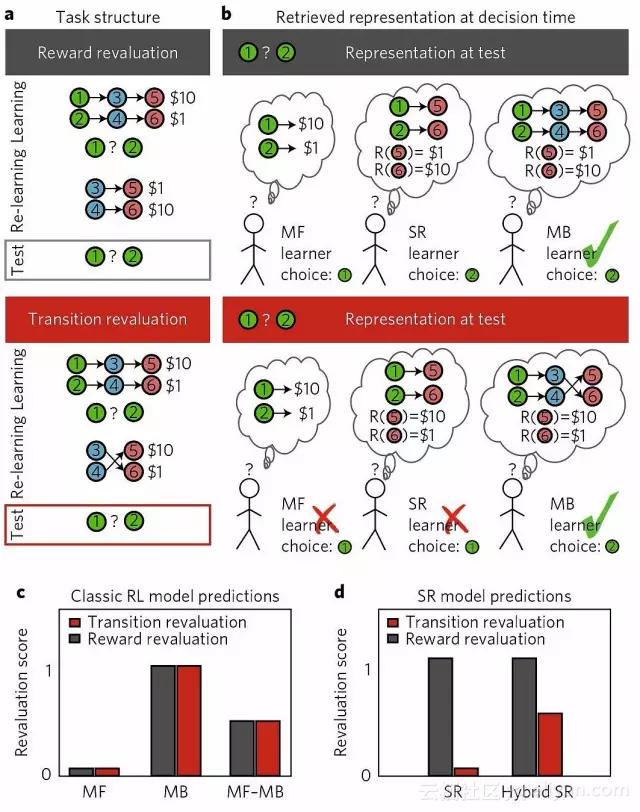
图2.在奖励和转换重估测试中,模型预测和检索到表示的原理图
所有混合SR策略将比转换重估的纯SR策略更好(但比MB差)。具体来说,相比预测过渡重估,混合SR策略在预测奖励重估时准确性更高,反应时间更快。MF或MB都的预测性能都没有展现出这样的不对称性。
作者通过两项研究实验测试并确认了他们的猜测,为人类行为中的强化学习里的SR提供了第一个直接证据。

摘要
神经科学中强化学习的理论侧重于两个算法族。无模型算法将行动值存入缓存,这样做虽然便宜但不灵活:因此,无模型算法是自适应习惯和适应不良习惯的候选机制。另一方面,基于模型的算法通过从环境模型中重建行动值来实现计算成本的灵活性。我们研究了一类中间算法,后继表示(successor representation,SR),缓存长期状态预期,将无模型的效率和基于模型的灵活性相结合。虽然以前关于奖励重估的研究将无模型算法与基于模型的学习算法区分开来,但这种设计不能区分基于模型和基于SR的算法,后两种都预测了奖励重估的敏感度。然而,改变过渡结构(“过渡重估”)应该有选择性地损害SR的重估。在两项研究中,我们提供的证据表明,人类对奖励重估与过渡重估的差异敏感度与SR预测一致。这些结果为一种新的灵活选择神经计算(neuro-computational)机制提供了支撑,同时为习惯引入了更细微,更认知的看法。
很学术的论文,但推荐阅读:
Nature 论文地址(非公开发表):https://www.nature.com/articles/s41562-017-0180-8
Bio-arXiv 地址:http://www.biorxiv.org/content/biorxiv/early/2016/10/27/083824.full.pdf