场景引入
菜鸟不断又猛又持久的给老鸟惊喜以后,老鸟开始不断的折腾菜鸟:“鸟,你研究下有没有一款可以测试MSSQL Server的工具吧?”。
“这还不简单,用Red Gate的SQLTest呗”,于是菜鸟开始了工具的研究之旅:“要不,今天就分享下SQLTest之Insert语句测试吧”。
SQLTest简介
领了任务的菜鸟,由于之前对这个工具有所了解,所以还是比较轻车熟路的。让我们先来看看SQLTest是干什么的吧。
SQLTest是一款简单易用,非常容易上手的SQL Server性能、压力和单元测试工具。它既可以测试本地环境的SQL Server工作负载,也可以测试云环境的SQL Server服务。
SQLTest一键安装
SQLTest就是一个简单的SQL Server测试工具,所以,它的安装过程也简单。官方推荐一键安装,简单到令人发指的地步。
下载地址:
http://www.sqltest.org/Download
测试环境
在测试之前,菜鸟汇总自己的测试环境信息:
CPU:4 cores
Memory:4 GB
Disk: SSD
SQL Server: SQL Server 2008R2 SP2
SQLTest INSERT语句测试
老实讲,上面都不重要,看好了,这里才是本文的重点:如何使用SQLTest来测试INSERT的效率呢?如何测试INSERT语句在不同线程数量下的效率?不同的数据类型选择对INSERT效率的影响如何?
这里虚拟一个场景,假设我们有一张名为Orders的订单表,我们会根据Orders的主键数据类型的不同来测试INSERT的效率。
INT IDENTITY
创建测试数据库和Orders表
use master;
IF DB_ID('SQLTestDemo') IS NULL
CREATE DATABASE SQLTestDemo
go
use SQLTestDemo
go
IF OBJECT_ID('Orders','U') IS NOT NULL
BEGIN
TRUNCATE TABLE Orders
DROP TABLE Orders
END
GO
CREATE TABLE Orders (
OrderID INT NOT NULL IDENTITY(1,1) PRIMARY KEY CLUSTERED
, OrderDate datetime
, CustomerID int
, SourceID int
, StatusID int
, Amount decimal (18, 2)
, OrderDetails char(7000)
)
GO
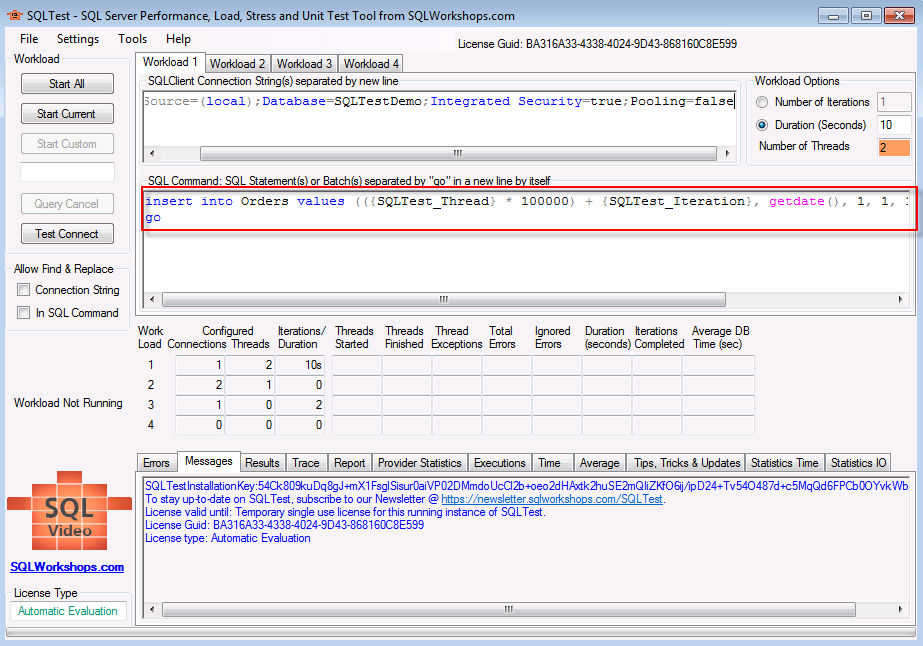
所有准备工作就绪,菜鸟迫不及待的开始测试了,开启SQLTest,设置SQLClient Connection String
Data Source=(local);Database=SQLTestDemo;Integrated Security=true;Pooling=false
SQL Command
insert into Orders values (getdate (), 1, 1, 1, 1, replicate ('a', 7000))
go
Number of Threads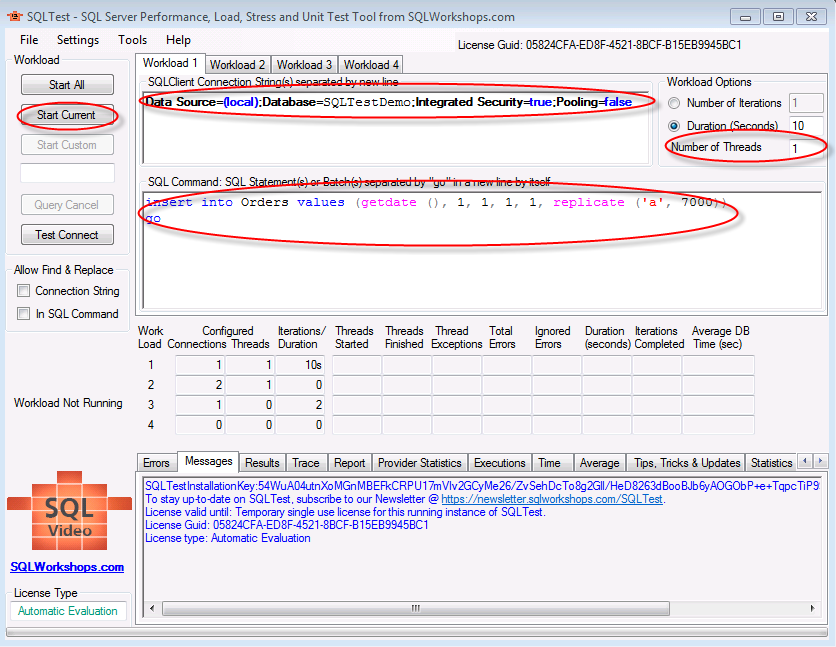
点击Start Current按钮,测试时间10秒后,得到如下截图:
1个线程运行10秒钟,迭代了12471次,每次迭代消耗数据库时间0.000秒。(由于这里精确到千分之一秒,也就是一毫秒,说明每次迭代耗时少于1毫秒)。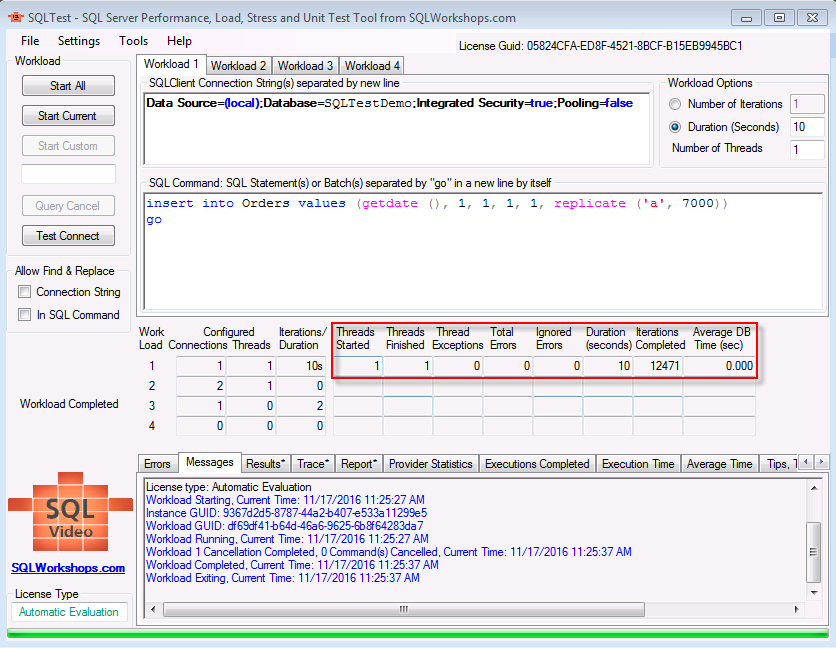
现在我们分别将线程数调整为2,4,8,16,32,64,128,256来测试,为了测试的相对准确性,请在测试之前执行“创建测试数据库和Orders表”中的代码,重新创建Orders表。SQLTest返回结果的设置方法如下:Settings => Workload Settings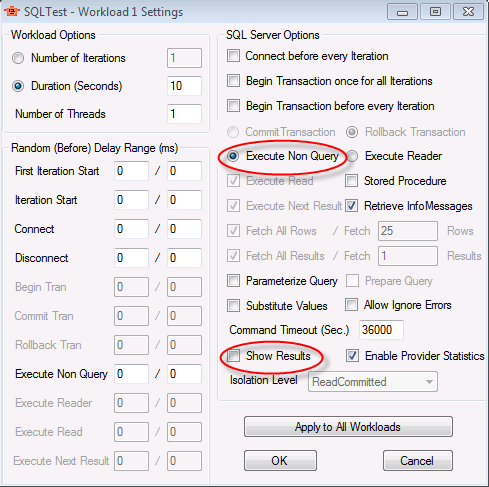
测试完毕后,我们可以得到如下表格数据:
将这些数据绘制成直方图和折线图: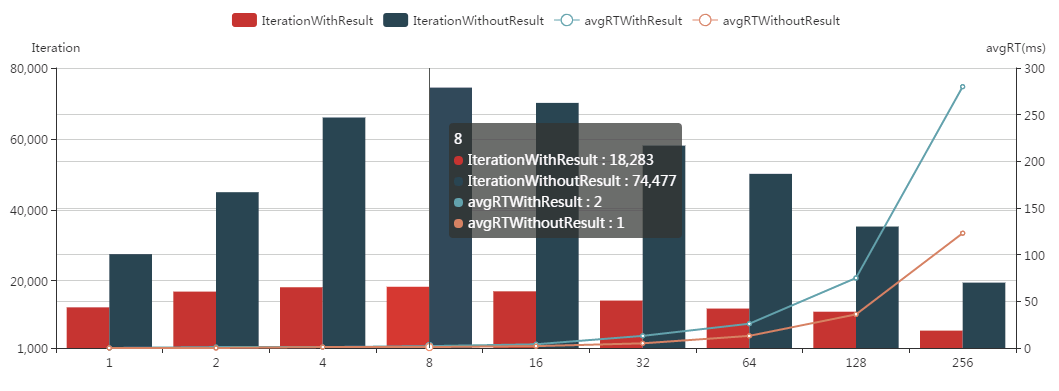
从这个图中,可以很直观的得出如下结论:
- 从吞吐量来看:无输出结果方式远远大于有输出结果方式,前者是后者的两倍还多;
- 从数据库平均耗时来看:无输出结果效率也远远高于有输出结果方式,后者是前者的两倍;
- 从线程数量来看:并不是线程数开得越多,SQL Server吞吐量越大,效率越高;无论是有输出结果方式还是无输出结果方式,并发8到16个线程SQL Server的吞吐量达到最大,效率最高;
注意:
最后一个结论不一定适用于所有的SQL Server,因为这个和SQL Server的版本,机器的CPU,Memory,磁盘等有密切的关系,用户在得到这个值之前需要自己严格测试。
提供INT值
完成了主键值INT IDENTITY的测试后,菜鸟陷入了疑惑:每个线程如何插入不同的值呢?于是有了这个测试方法:
use SQLTestDemo
go
IF OBJECT_ID('Orders','U') IS NOT NULL
begin
truncate table Orders
drop table Orders
end
go
create table Orders (OrderID int primary key clustered
, OrderDate datetime
, CustomerID int
, SourceID int
, StatusID int
, Amount decimal (18, 2)
, OrderDetails char (7000)
)
go
让每个线程生成不同的OrderID,我们可以使用SQLTest_Thread来代替线程数,SQLTest_Iteration代替迭代次数,最终将SQL Command修改为:
insert into Orders values (({SQLTest_Thread} * 100000) + {SQLTest_Iteration}, getdate(), 1, 1, 1, 1, replicate ('a', 7000))
go
UNIQUEIDENTIFIER with NEWID()
测试方法类似于“INT IDENTITY”章节,只是Orders表结构和SQL Command不一致。
use SQLTestDemo
go
IF OBJECT_ID('Orders','U') IS NOT NULL
begin
truncate table Orders
drop table Orders
end
go
create table Orders (
OrderID uniqueidentifier not null default newid () primary key clustered
, OrderDate datetime
, CustomerID int
, SourceID int
, StatusID int
, Amount decimal (18, 2)
, OrderDetails char (7000))
go
SQL Command
insert into Orders values (NEWID(),getdate (), 1, 1, 1, 1, replicate ('a', 7000))
go
UNIQUEIDENTIFIER with NEWSEQUENTIALID()
同上,测试方法类似于“INT IDENTITY”章节,只是Orders表结构和SQL Command不一致。
use SQLTestDemo
go
IF OBJECT_ID('Orders','U') IS NOT NULL
BEGIN
TRUNCATE TABLE Orders
DROP TABLE Orders
END
GO
CREATE TABLE Orders (
OrderID uniqueidentifier default newsequentialid () primary key clustered
, OrderDate datetime
, CustomerID int
, SourceID int
, StatusID int
, Amount decimal (18, 2)
, OrderDetails char (7000))
GO
SQL Command
insert into Orders(OrderDate,CustomerID,SourceID,StatusID,Amount,OrderDetails) values (getdate (), 1, 1, 1, 1, replicate ('a', 7000))
go
总结
将四种数据类型在No Result输出情况汇总统计如下表: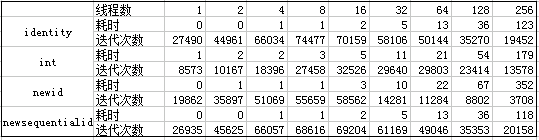
做一个漂亮炫酷的图表出来对比下: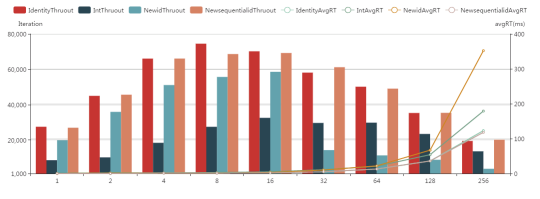
从这个图标,我们可以发现如下规律:
- 从吞吐量角度来看:所有数据类型,并发量聚集在8到16时,INSERT操作吞吐量达到最大值;
- 吞吐量表现最好的是int identity数据类型和uniqueidentifier + newsequentialid做为主键的表;
- 从数据库平均耗时角度:所有数据类型,并发量在8到16时,INSERT操作的平均时间消耗最小,接近64个线程时,平均耗时会急剧上升;
- 平均耗时表现最好的是int identity和Newsequentialid类型。
从结果来看,UNIQUEIDENTIFIER + NEWSEQUENTIALID和INT IDENTITY性能和吞吐量表现都非常好,我们到底该选择哪一个更好一些呢? 我的结论是选择IDENTITY属性的数字类型字段做为主键,因为它占的空间更小,INT为4个字节,BIGINT为8个字节而UNIQUEIDENTIFIER 占了36个字节。
写在最后
老鸟看完菜鸟的研究报告,赞不绝口:“不错啊,今天的最好表现就是明天对你的最低要求,SQLTest INSERT如何做参数化测试啊?”。
菜鸟卖起了关子:“鸟哥,预知后事如何,且听下回分解”。