文件上传格式
先来看下含有文件上传时的表单提交是怎样的格式
<form action="/upload/request" method="POST" enctype="multipart/form-data" id="requestForm">
<input type="file" name="myFile">
<input type="text" name="user">
<input type="text" name="password">
<input type="submit" value="提交">
</form>
form表单提交内容如下
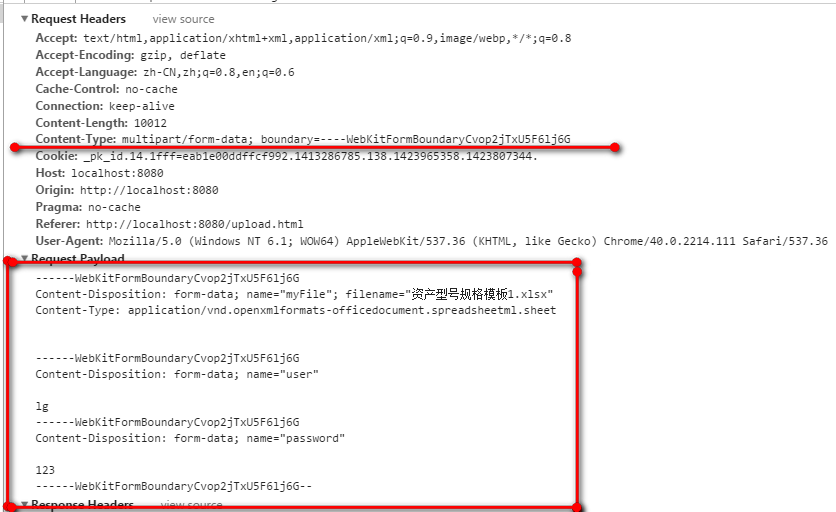
从上面可以看到,含有文件上传的格式是这样组织的。
- 文件类型字段
------WebKitFormBoundaryCvop2jTxU5F6lj6G(分隔符) Content-Disposition: form-data; name="myFile"; filename="资产型号规格模板1.xlsx" Content-Type: application/vnd.openxmlformats-officedocument.spreadsheetml.sheet (换行) (文件内容) - 其他类型字段
------WebKitFormBoundaryCvop2jTxU5F6lj6G(分隔符) Content-Disposition: form-data; name="user" (换行) lg - 结束
------WebKitFormBoundaryCvop2jTxU5F6lj6G--(分隔符加上--)
对于上面的文件内容,chrome浏览器是不显示的,换成firefox可以看到,如下图所示

同时我们还可以注意到,不同的浏览器,分隔符是不一样的,在请求头
Content-Type:multipart/form-data; boundary=----WebKitFormBoundaryCvop2jTxU5F6lj6G
中指明了分隔符的内容。
更加详细的上传格式还是参看 rfc文档
文件上传注意点:
- 一定是post提交,如果换成get提交,则浏览器默认仅仅把文件名作为属性值来上传,不会上传文件内容,如下

- form表单中一定不要忘了添加
enctype="multipart/form-data"否则的话,浏览器则不是按照上述的格式来来传递数据的。
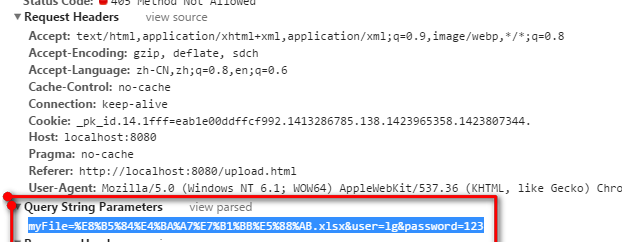
上述两点才能保证浏览器正常的进行文件上传。
apache fileupload的解析
参见官方文档: 官方文档
有了上述文件上传的组织格式,我们就需要合理的设计后台的解析方式,下面来看下apache fileupload的使用。先来看下整体的流程图 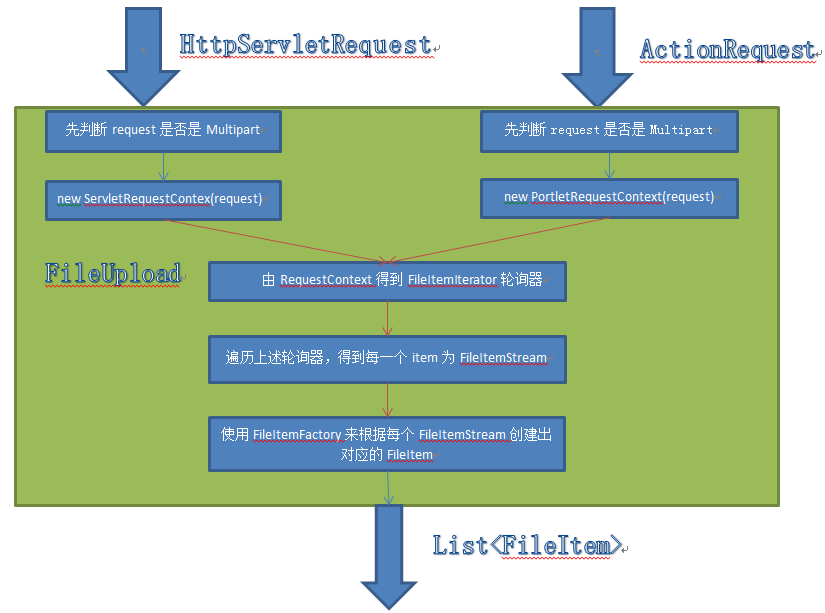
Servlets and Portlets
apache fileupload分Servlets and Portlets两种情形来处理。Servlet我们很熟悉,而Portlets我也没用过,可自行去搜索。
判断request是否是Multipart
对于HttpServletRequest来说,另一个不再说明,自行查看源码,判断规则如下:
- 是否是post请求
- contentType是否以multipart/开头
见源码:
public static final boolean isMultipartContent(
HttpServletRequest request) {
if (!POST_METHOD.equalsIgnoreCase(request.getMethod())) {
return false;
}
return FileUploadBase.isMultipartContent(new ServletRequestContext(request));
}
public static final boolean isMultipartContent(RequestContext ctx) {
String contentType = ctx.getContentType();
if (contentType == null) {
return false;
}
if (contentType.toLowerCase(Locale.ENGLISH).startsWith(MULTIPART)) {
return true;
}
return false;
}
对request封装成RequestContext
servlet的输入参数为HttpServletRequest,Portlets的输入参数为ActionRequest,数据来源不同,为了统一方便后面的数据处理,引入了RequestContext接口,来统一一下目标数据的获取。
接口RequestContext的实现类:
- ServletRequestContext
- PortletRequestContext
此时RequestContext就作为了数据源,不再与HttpServletRequest和ActionRequest打交道。
上述的实现过程是由FileUpload的子类ServletFileUpload和PortletFileUpload分别完成包装的。
父类FileUpload的子类:
- ServletFileUpload
- PortletFileUpload
源码展示如下:
- ServletFileUpload类
public List<FileItem> parseRequest(HttpServletRequest request) throws FileUploadException { return parseRequest(new ServletRequestContext(request)); } - PortletFileUpload类
public List<FileItem> parseRequest(ActionRequest request) throws FileUploadException { return parseRequest(new PortletRequestContext(request)); }
上述的parseRequest便完成了整个request的解析过程,内容如下:
public List<FileItem> parseRequest(RequestContext ctx)
throws FileUploadException {
List<FileItem> items = new ArrayList<FileItem>();
boolean successful = false;
try {
FileItemIterator iter = getItemIterator(ctx);
FileItemFactory fac = getFileItemFactory();
if (fac == null) {
throw new NullPointerException("No FileItemFactory has been set.");
}
while (iter.hasNext()) {
final FileItemStream item = iter.next();
// Don't use getName() here to prevent an InvalidFileNameException.
final String fileName = ((FileItemIteratorImpl.FileItemStreamImpl) item).name;
FileItem fileItem = fac.createItem(item.getFieldName(), item.getContentType(),
item.isFormField(), fileName);
items.add(fileItem);
try {
Streams.copy(item.openStream(), fileItem.getOutputStream(), true);
} catch (FileUploadIOException e) {
throw (FileUploadException) e.getCause();
} catch (IOException e) {
throw new IOFileUploadException(format("Processing of %s request failed. %s",
MULTIPART_FORM_DATA, e.getMessage()), e);
}
final FileItemHeaders fih = item.getHeaders();
fileItem.setHeaders(fih);
}
successful = true;
return items;
} catch (FileUploadIOException e) {
throw (FileUploadException) e.getCause();
} catch (IOException e) {
throw new FileUploadException(e.getMessage(), e);
} finally {
if (!successful) {
for (FileItem fileItem : items) {
try {
fileItem.delete();
} catch (Throwable e) {
// ignore it
}
}
}
}
}
分以下两个大步骤:
- 根据RequestContext数据源得到解析后的数据集合 FileItemIterator
- 遍历FileItemIterator中的每个item,类型为FileItemStreamImpl,使用FileItemFactory工厂类来将每个FileItemStreamImpl转化成最终的FileItem
由RequestContext数据源得到解析后的数据集合 FileItemIterator
- FileItemIterator内容如下:
public interface FileItemIterator { boolean hasNext() throws FileUploadException, IOException; FileItemStream next() throws FileUploadException, IOException; }这就是一个轮询器,可以假想成FileItemStream的集合,实际上不是,后面会进行介绍
- FileItemStream则是之前上传文件格式内容
------WebKitFormBoundary77tsMdWQBKrQOSsV Content-Disposition: form-data; name="user" lg或者
------WebKitFormBoundary77tsMdWQBKrQOSsV Content-Disposition: form-data; name="myFile"; filename="萌芽.jpg" Content-Type: image/jpeg (文件内容)的封装,代码如下
public interface FileItemStream extends FileItemHeadersSupport { /*流中包含了数值或者文件的内容*/ InputStream openStream() throws IOException; String getContentType(); /*用来存放文件名,不是文件字段则为null*/ String getName(); /*对应input标签中的name属性*/ String getFieldName(); /*标识该字段是否是一般的form字段还是文件字段*/ boolean isFormField(); }
然后我们来具体看下由RequestContext如何解析成一个FileItemIterator的:
public FileItemIterator getItemIterator(RequestContext ctx)
throws FileUploadException, IOException {
try {
return new FileItemIteratorImpl(ctx);
} catch (FileUploadIOException e) {
// unwrap encapsulated SizeException
throw (FileUploadException) e.getCause();
}
}
new了一个FileItemIteratorImpl,来看下具体的过程:
FileItemIteratorImpl(RequestContext ctx)
throws FileUploadException, IOException {
if (ctx == null) {
throw new NullPointerException("ctx parameter");
}
String contentType = ctx.getContentType();
if ((null == contentType)
|| (!contentType.toLowerCase(Locale.ENGLISH).startsWith(MULTIPART))) {
throw new InvalidContentTypeException(
format("the request doesn't contain a %s or %s stream, content type header is %s",
MULTIPART_FORM_DATA, MULTIPART_MIXED, contentType));
}
InputStream input = ctx.getInputStream();
@SuppressWarnings("deprecation") // still has to be backward compatible
final int contentLengthInt = ctx.getContentLength();
final long requestSize = UploadContext.class.isAssignableFrom(ctx.getClass())
// Inline conditional is OK here CHECKSTYLE:OFF
? ((UploadContext) ctx).contentLength()
: contentLengthInt;
// CHECKSTYLE:ON
if (sizeMax >= 0) {
if (requestSize != -1 && requestSize > sizeMax) {
throw new SizeLimitExceededException(
format("the request was rejected because its size (%s) exceeds the configured maximum (%s)",
Long.valueOf(requestSize), Long.valueOf(sizeMax)),
requestSize, sizeMax);
}
input = new LimitedInputStream(input, sizeMax) {
@Override
protected void raiseError(long pSizeMax, long pCount)
throws IOException {
FileUploadException ex = new SizeLimitExceededException(
format("the request was rejected because its size (%s) exceeds the configured maximum (%s)",
Long.valueOf(pCount), Long.valueOf(pSizeMax)),
pCount, pSizeMax);
throw new FileUploadIOException(ex);
}
};
}
String charEncoding = headerEncoding;
if (charEncoding == null) {
charEncoding = ctx.getCharacterEncoding();
}
boundary = getBoundary(contentType);
if (boundary == null) {
throw new FileUploadException("the request was rejected because no multipart boundary was found");
}
notifier = new MultipartStream.ProgressNotifier(listener, requestSize);
try {
multi = new MultipartStream(input, boundary, notifier);
} catch (IllegalArgumentException iae) {
throw new InvalidContentTypeException(
format("The boundary specified in the %s header is too long", CONTENT_TYPE), iae);
}
multi.setHeaderEncoding(charEncoding);
skipPreamble = true;
findNextItem();
}
要点:
- contentType进行判断,是否以multipart开头
- 判断整个请求流的数据大小是否超过sizeMax最大设置
- 获取重要的分隔符boundary信息
- 封装了request请求流的数据,包装为MultipartStream类型
- 也可以设置通知器,来通知流的读取进度
这里可以看到FileItemIteratorImpl并不是FileItemStreamImpl的集合,其实是FileItemIteratorImpl内部包含了一个FileItemStreamImpl属性。FileItemIteratorImpl的一些重要属性和方法如下:
/*总的数据流*/
private final MultipartStream multi;
/*通知器*/
private final MultipartStream.ProgressNotifier notifier;
/*分隔符*/
private final byte[] boundary;
/*当前已解析到的FileItemStreamImpl对象*/
private FileItemStreamImpl currentItem;
public boolean hasNext() throws FileUploadException, IOException {
if (eof) {
return false;
}
if (itemValid) {
return true;
}
try {
return findNextItem();
} catch (FileUploadIOException e) {
// unwrap encapsulated SizeException
throw (FileUploadException) e.getCause();
}
}
public FileItemStream next() throws FileUploadException, IOException {
if (eof || (!itemValid && !hasNext())) {
throw new NoSuchElementException();
}
itemValid = false;
return currentItem;
}
- findNextItem()方法就是创建新的FileItemStreamImpl来替代当前的FileItemStreamImpl,并更新起始位置。
- 每次调用FileItemIteratorImpl的hasNext()方法,会创建一个新的FileItemStreamImpl赋值给FileItemStreamImpl属性
- 每次调用FileItemIteratorImpl的next()方法,就会返回当前FileItemStreamImpl属性的值
- 创建的每个FileItemStreamImpl都会共享FileItemIteratorImpl的MultipartStream总流,仅仅更新了要读取的起始位置
遍历FileItemIterator,通过FileItemFactory工厂将每一个item转化成FileItem对象
其他应用其实就可以遍历FileItemIteratorImpl拿到每一项FileItemStreamImpl的解析数据了。只是这时候数据
- 存储在内存中的
- 每个FileItemStreamImpl都是共享一个总的流,不能被重复读取
我们想把这些文件数据存在临时文件中,就需要使用使用FileItemFactory来进行下转化成FileItem。每个FileItem才是相互独立的,而FileItemStreamImpl则不是,每个FileItem也是对应上传文件格式中的每一项,如下
InputStream getInputStream() throws IOException;
String getContentType();
String getName();
String getFieldName();
boolean isFormField();
FileItemFactory的实现类DiskFileItemFactory即将数据存储在硬盘上,代码如下:
public static final int DEFAULT_SIZE_THRESHOLD = 10240;
/*制定了临时文件的目录*/
private File repository;
/*当数据小于该阈值时存储到内存中,超过时存储到临时文件中*/
private int sizeThreshold = DEFAULT_SIZE_THRESHOLD;
public FileItem createItem(String fieldName, String contentType,
boolean isFormField, String fileName) {
DiskFileItem result = new DiskFileItem(fieldName, contentType,
isFormField, fileName, sizeThreshold, repository);
FileCleaningTracker tracker = getFileCleaningTracker();
if (tracker != null) {
tracker.track(result.getTempFile(), result);
}
return result;
}
我们从上面可以看到,其实FileItemFactory的createItem方法,并没有为FileItem的流赋值。再回顾下上文parseRequest方法的源代码,赋值发生在这里
FileItemIterator iter = getItemIterator(ctx);
FileItemFactory fac = getFileItemFactory();
if (fac == null) {
throw new NullPointerException("No FileItemFactory has been set.");
}
while (iter.hasNext()) {
final FileItemStream item = iter.next();
// Don't use getName() here to prevent an InvalidFileNameException.
final String fileName = ((FileItemIteratorImpl.FileItemStreamImpl) item).name;
FileItem fileItem = fac.createItem(item.getFieldName(), item.getContentType(),
item.isFormField(), fileName);
items.add(fileItem);
try {
/*这里才是为每一个FileItem的流赋值*/
Streams.copy(item.openStream(), fileItem.getOutputStream(), true);
} catch (FileUploadIOException e) {
throw (FileUploadException) e.getCause();
} catch (IOException e) {
throw new IOFileUploadException(format("Processing of %s request failed. %s",
MULTIPART_FORM_DATA, e.getMessage()), e);
}
final FileItemHeaders fih = item.getHeaders();
fileItem.setHeaders(fih);
}
上述FileItem的openStream()方法如下:
public OutputStream getOutputStream()
throws IOException {
if (dfos == null) {
File outputFile = getTempFile();
dfos = new DeferredFileOutputStream(sizeThreshold, outputFile);
}
return dfos;
}
protected File getTempFile() {
if (tempFile == null) {
File tempDir = repository;
if (tempDir == null) {
tempDir = new File(System.getProperty("java.io.tmpdir"));
}
String tempFileName = format("upload_%s_%s.tmp", UID, getUniqueId());
tempFile = new File(tempDir, tempFileName);
}
return tempFile;
}
getTempFile()会根据FileItemFactory的临时文件目录配置repository,创建一个临时文件,用于上传文件。
这里又用到了commons-io包中的DeferredFileOutputStream类。
- 当数据数量小于sizeThreshold阈值时,存储在内存中
- 当数据数量大于sizeThreshold阈值时,存储到传入的临时文件中
至此,FileItem都被创建出来了,整个过程就结束了。