性能优化参数
针对Spark SQL 性能调优参数如下:
代码示例
import java.util.List;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.sql.api.java.JavaSQLContext;
import org.apache.spark.sql.api.java.Row;
import org.apache.spark.sql.hive.api.java.JavaHiveContext;
public class PerformanceTuneDemo {
public static void main(String[] args) {
SparkConf conf = new SparkConf().setAppName("simpledemo").setMaster("local");
conf.set("spark.sql.codegen", "false");
conf.set("spark.sql.inMemoryColumnarStorage.compressed", "false");
conf.set("spark.sql.inMemoryColumnarStorage.batchSize", "1000");
conf.set("spark.sql.parquet.compression.codec", "snappy");
JavaSparkContext sc = new JavaSparkContext(conf);
JavaSQLContext sqlCtx = new JavaSQLContext(sc);
JavaHiveContext hiveCtx = new JavaHiveContext(sc);
List<Row> result = hiveCtx.sql("SELECT foo,bar,name from pokes2 limit 10").collect();
for (Row row : result) {
System.out.println(row.getString(0) + "," + row.getString(1) + "," + row.getString(2));
}
}
}Beeline 命令行设置优化参数
beeline> set spark.sql.codegen=true;
SET spark.sql.codegen=true
spark.sql.codegen=true
Time taken: 1.196 seconds重要参数说明
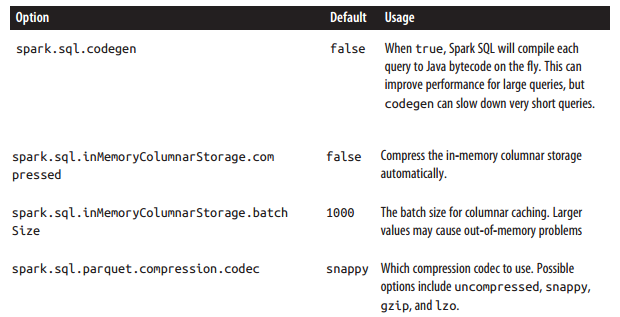
spark.sql.codegen Spark SQL在每次执行次,先把SQL查询编译JAVA字节码。针对执行时间长的SQL查询或频繁执行的SQL查询,此配置能加快查询速度,因为它产生特殊的字节码去执行。但是针对很短(1 - 2秒)的临时查询,这可能增加开销,因为它必须先编译每一个查询。
spark.sql.inMemoryColumnarStorage.batchSize:
When caching SchemaRDDs, Spark SQL groups together the records in the RDD in batches of the size given by this option (default: 1000), and compresses each batch. Very small batch sizes lead to low compression, but on the other hand very large sizes can also be problematic, as each batch might be too large to build up in memory.
时间: 2024-11-02 19:24:24