TableStore
TableStore(表格存储),是阿里云2013年推出的一款分布式数据库,具体可以看看官网的介绍:
表格存储(Table Store)是构建在阿里云飞天分布式系统之上的NoSQL数据存储服务,提供海量结构化数据的存储和实时访问。表格存储以实例和表的形式组织数据,通过数据分片和负载均衡技术,实现规模上的无缝扩展。应用通过调用表格存储 API / SDK 或者操作管理控制台来使用表格存储服务。
从上面可以看到有下面这些特点:
- 是NoSQL数据库,通过API或SDK访问,不支持SQL
- 用户无感知的无缝规模扩展
- 实时存储和访问
- 组织形式两层:实例和表
除了上面这些特点外,还有没有其他吸引人的地方?深挖一下,肯定是有的:
- 对写入性能做过特别优化,特别适合写入多的场景
- 读性能也不差,比如某个用户读取聊天信息的请求中,90%请求的Latency都小于2ms
- 由于是云服务,QPS理论上无上限
- 支持过滤,主键和属性列都支持条件过滤
- 支持行和列的条件更新
- 预留和按量等多种收费模式
- 支持单行读,单行写,范围读,批量读,批量写和迭代读
- 价格便宜,且每月有大量的免费额度
- 稀疏表结构,灵活性更大
- 服务可靠性和数据安全性高,多重冗余备份
由于以上特点,表格存储比较适合于超大规模的结构化,半结构化数据的存储和访问,比如:搜索系统中的爬虫和离线数据处理系统每天都要处理亿级的网页数据,大型系统的日志存储,各种数据的元数据存储,物流跟踪数据,订单存储等等,这里的每一个都可以通过单独文章来介绍。更详细的TableStore介绍可以看看:TableStore文档
ElasticSearch
ElasticSearch是2010年开源的一款搜索系统,核心使用Lucene,在其外做了一个分布式解决方案,组合后就是一个分布式的搜索系统,用户只需要从官网下载后,甚至不用配置任何文件,只需执行一个命令即可启动,接着就可以使用RESTful API推送文档和各种查询了。
ElasticSearch自从诞生以来,就以接近指数型的增长速度快速超过了Lucene,现在已经成了不少公司用来搜索和分析数据的强大工具,各地也自发产生了不少ElasticSearch分享会议。下图是Google trends展示的热度,红色是Lucene,蓝色是ElasticSearch: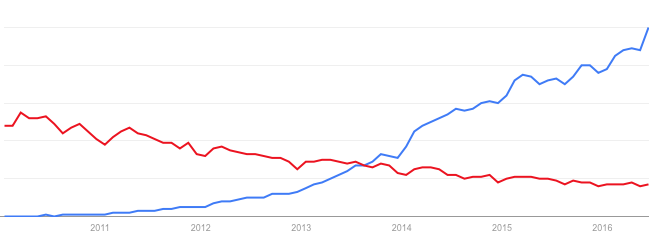
我们具体来看看官网的介绍:
Elasticsearch | Search & Analyze Data in Real Time
从上面可以看到两大特点:
- 搜索
- 分析
- 实时性
所以,ElasticSearch不仅是一款搜索引擎,也是一款强大的分析引擎。
ElasticSearch基于Lucene。Lucene是一个搜索库,提供了搜索的基础功能,包括建索引,查索引,算分相关的库,但是并没有提供如何做failover、如何分partition做分布式、如何调用服务(API)等,Lucene是一个强大的搜索库,但离最后使用还差最后一步,ElasticSearch就是将这最后一步做完了:
- API:ES提供了基于HTTP协议,以JSON为数据交互格式的RESTful API,简化了用户的使用难度。
- 分布式:要支持分布式,一般做法就是将数据横向分成多个shard(或叫partition),要么是物理方式,要么是逻辑方式,目标都是一样,将大量数据和操作分到不同机器上去,分而治之,最后查询的时候需要将一个请求分发到相应的机器上去,这里也有两种做法,一是将请求发给特定的下游机器,另一种是将请求发给所有下游机器,第一种性能好点。这里需要将请求分发,最后查询完成后需要将请求的结果合并,这里一般也有两种做法,一种是有一个独立的proxy角色,分发请求到不同的下游机器上去,另一种是将这个proxy合并到每个下游机器,这要每个下游机器就会既可以分发请求,也可以做查询操作,ES选择的是第二种方式,这样最大好处就是ES只有一个角色的binary,只要启动一个binary就能使用了,大大简化了搜索的准入门槛。
- 隔离性:ES天然支持多租户,不用做改动就可以拿来提供云服务,一个ES进程可以支持多个用户的不同索引,但是是半物理隔离,半逻辑隔离,数据层面是物理隔离,操作层面是逻辑隔离。如果某个用户的索引数据损坏,并不会影响其他用户的数据,但是某一个用户的大量操作可能会占尽系统资源,导致其他用户无资源可用,延迟增大,甚至超时等。
接下来可以大概看看他的功能:
- 支持全文检索,基础功能
- 支持模糊搜索,指的是两个词之间的编辑距离,比如搜索good,可以搜索出goods。
- 支持通配符搜索,做法是先在内存中找出匹配的term,然后再用匹配到的term去搜索,性能不高。
- 支持父子文档,嵌套文档等,覆盖了多种文档之间的关系。
- 支持近似搜索(more like this)
- 支持反向搜索,通过doc查关键词,适用于自动给文档打标签
- 支持多版本
- span查询,比如查询某个字段值的前几个term等。
- Geo地理位置查询,特别适用于外卖,附近的人等场景。
- 最小值,最大值,和,标准差,方差,平方和,直方图等统计
- 每种值的个数统计
- 数值的分布统计
- 空值过滤和搜索
- 范围查询和统计
- 支持script,可以支持在建索引时或者查询时使用表达式计算某个字段的值。
从上面可以看出,ElasticSearch不仅搜索功能强大,而且统计功能也很强大,甚至有一些黑科技感的功能,只是对于相关性支持稍差些。现在有不少公司,已经将除财务外的所有数据都导入ElasticSearch做搜索和分析了。ElasticSearch就先介绍这些,如果想了解更多可以后面再分文章讲或者可以看看:ElasticSearch文档
TableStore与ElasticSearch
前面大概介绍了TableStore和ElasticSearch,虽然两者都可以用来存储和查询数据,但是他们的侧重点不同:
- TableStore侧重于数据的大规模存储,相当于是一个无存储上限的数据仓库,存在上面的数据可以基本认为是永久安全的,而且性能很关键,读写的延迟都非常低,一般查询性能都在毫秒级别。
- ElasticSearch侧重于数据的搜索和分析,重点是多种类型的查询,各种分析和聚合等,侧重于功能的全面性,对性能的敏感度稍低,一般平均查询性能在百毫秒级别,比TableStre低两个数量级。
所以,两者其实是相铺相成的,可以互相配合使用,比如在功能层面
- TableStore做数据存储
- ElasticSearch做数据搜索和分析。
数据持久层面:
- TableStore会保证数据的安全性,ElasticSearch可以不用关心数据安全,只需要做好搜索和高级分析即可,如果ElasticSearch中的数据损坏了,可以从TableStore再导入一次就可以了。
一般的做法就是数据写入的时候写两份,一份给TableStore,一份给ES。后续如果TableStore提供自动写数据给ES等第三方系统,到时候结合使用TableStore和ES会更简单。
示例
前面讲了TableStore和ElasticSearch的功能,现在我们看几个简单的使用场景:
地图信息
小明是个顶级程序员,也是个高级吃货社区的管理员,他们的团体每天都会发现不少新饭店,苦于没地方记录。小明就想搞一个吃货地图,就叫吃图,拥有手机端App和Web端,但是数据怎么存把他难住了,他思考了半天,总结出需要满足的功能:
- 可靠性必须高,不能好不容易发现的美食店就弄丢了。
- 读写性能都要好,卡是不能容忍的。
- 每种店的特点都不一样,最好可以支持很多列名,也就是宽行
- 可以搜索自己附近的店铺
- 这个系统的理想是以后要开放给全世界的网友,存储要无上限
- 数据量会比较大,价格要便宜
- 网友水平参差不齐,可能会拼错某个字,需要支持模糊搜索
- 需要有按范围搜索
- 小明作为管理员,偶尔需要看看每个城市的店铺总数,价格区间分布等的统计数据
综合上面的特点,小明明白,自己需要的是一个存储系统和搜索系统。
存储系统需要具有以下特点:
- 数据可靠性高
- 读写性能好
- 支持宽行
- 扩容容易
- 价格便宜
搜索系统需要具有以下特点:
- 支持模糊搜索
- 支持距离范围搜索
- 支持按某个值统计总数和分布统计等
小明综合分析了下,阿里云的表格存储 + ElasticSearch支持上述所有功能。而且表格存储还有10GB的免费额度,ElasticSearch可以买几台ECS搭建。
周五下班后就开始动手干,先开通表格存储,接着买了几台ECS,每个ECS上下载好ES,不用任何配置,执行binary就启动了一个ES集群,然后利用表格存储的SDK和ES的RESTFul API很快写完了程序:当用户注册一个表格的时候,先给ES上传一个文档,成功后,再给TableStore插入这条数据。查询的时候先去查询ES,拿到PK后再去TableStore查询具体店铺信息。天还未亮,小明就已经做完了。
日志
很多系统都会产生不少日志文件,这些日志文件不能丢弃,后面可能还会使用到,而且会有以下一些特点:
- 每个系统都会产生多个日志文件
- 日志文件的特点是写多读少,写性能要好
- 每个系统产生的日志文件名称可能不一样,比如A系统的日志叫:stdout.txt,stderr.txt,a.log,B系统的日志叫:stdout.txt,stderr.txt,b.log。
- 这些日志文件偶尔需要搜索,用来调查问题
- 为了问题调查的准确性,这些日志文件不能丢失,要保证可靠性
- 价格要便宜
- 搜索要支持通配符,正则表达式搜索
- 搜索不太关心性能,延迟大点也没关系,关键是要省钱
综合上面的特点,我们需要一个东西,要有强大的写能力,数据的持久性要高,要支持宽行,扩容容易,不能丢数据,且要能支持搜索,价格便宜,除了支持搜索外,TableStore具有以上所有功能,而ElasticSearch具有上述所有搜索功能,既然这样,可以使用TableStore + ElasticSearch的组合。
- TableStore做存储系统,提供强大的写能力,数据高持久性,宽行,易扩容等
- ElasticSearch做附加的搜索系统,提供偶尔的搜索功能,而且搜索系统的数据容忍丢失,丢失后从TableStore再导入就可以了。
其他
其他的实践操作可以看看这篇TableStore与ElasticSearch实践
