
曾令军
云和恩墨技术专家,8年数据库运维经验。思维敏捷,擅长于数据库开发、解决棘手的数据库故障和性能问题,在数据库故障诊断、运维监控、性能优化方面积累了丰富的经验。
本文由一个表分区统计信息没有按预期更新的问题,逐步深入设疑、探因、求实,解开关于表分区统计信息收集的秘密。曲径通幽处,禅房花木深。让我们打开数据库知识的那扇窗,去看到花木浓茂幽静自然的美好。
案例背景
客户的业务系统中,做了AB表设计。A代表日间业务表,只存放一天的交易数据;B代表历史数据表,每天一个分区。每天晚上A表的所有数据会转入B表的最大分区中,然后B表的最大分区分裂成当天分区和新的最大分区。
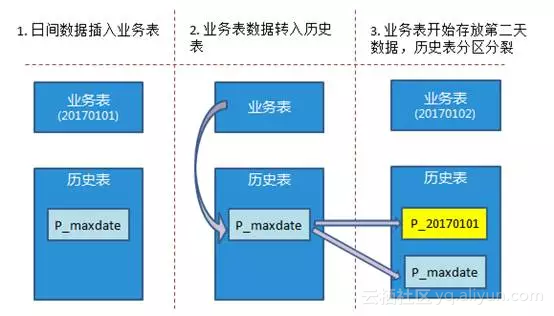
在做完上述数据转换及分区拆分之后,虽然此时P_20170101这个分区有大量的数据,虽然自动收集统计信息的任务每天都会运行,但这个分区的统计信息始终为0。
【问题】:在数据库自动收集统计信息任务运行后,分区P_20170101的统计信息错误,导致执行计划选择错误,与历史数据有关联的查询运行特别缓慢。
场景模拟
创建历史数据表,按交易日期做范围分区:

插入10000行数据后提交,模拟业务表数据转入历史表:
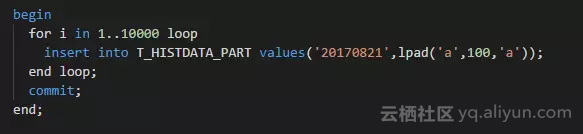
检查分区的统计信息:

此时虽然插入了数据,但没有手动或自动收集过,因此统计信息仍然为空。
且让它保持为空,并在这个前提下,继续往下做。
接下来拆分分区,然后再次检查分区的统计信息:
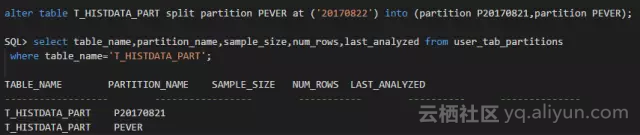
拆分完成之后,原分区PEVER和新分区P20170821此时的num_rows均为空。
调用自动收集统计信息任务的过程,然后检查分区的统计信息:
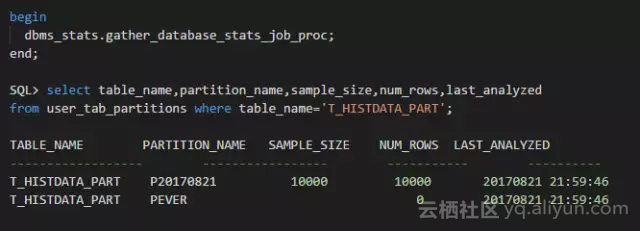
小贴士:dbms_stats.gather_database_stats_job_proc过程就是自动收集统计信息任务执行的程序,此处手工调用,模拟客户数据库每天自动收集任务的运行。该过程相当于使用gather auto选项调用了dbms_stats.gather_database_stats过程
注意此时统计的P20170821记录数为10000行,统计信息完全正确!并没有模拟出与客户问题相符的现象。
继续插入20000行数据,但日期换成20170822,模拟第二天的交易:
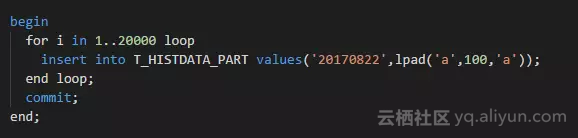
拆分分区,然后检查分区的统计信息:
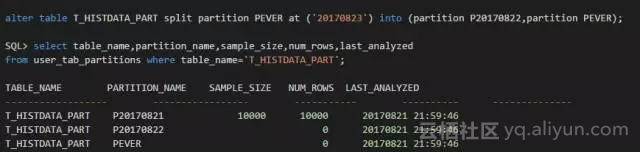
注意这里的差异,新分区P20170822的num_rows并不是空,而是0。
调用自动收集统计信息任务的过程,然后检查分区的统计信息:
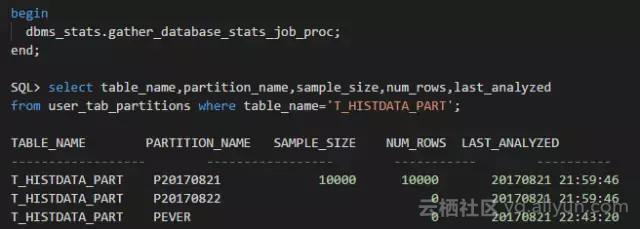
问题模拟出来了。新分区P20170822实际上有20000行数据,但自动收集的任务运行后,该分区的行数仍然是0。
模拟过程中引出来的问题:
1) 为什么拆分分区的初始化统计信息开始是空,而后面又变成 0?
2) 为什么分区的统计信息为空时,自动收集任务运行后,统计信息更新了?
3) 为什么分区的统计信息为0时,这个分区有大量数据,而统计信息始终不更新?
4) PEVER分区一开始是空,先插入了20000行,然后数据又分裂出去,重新变回一个空分区,为什么它的统计信息又更新了?
后三个问题,都指向了同一个问题:自动收集任务运行时,哪些对象被收集?
拨开迷雾
问:为什么拆分分区的初始化统计信息开始是空,而后面又变成0?
答:分区分裂时,新分区的统计信息继承了原分区的统计信息值
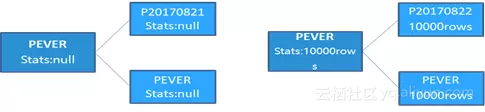
第一次分裂的时候,由于PEVER分区的统计信息为空,因此分裂出来的P20170821和新的PEVER分区初始的统计信息也为空;第二次分裂的时候,由于此时PEVER分区的统计信息被收集过,变成了 0行,那么分裂出来的P20170821和新的PEVER分区的初始统计信息就是0行。那假如PEVER分区是10000行,新分区也会是10000行,依此类推。
问:自动收集任务运行时,哪些对象被收集?
答:存在缺失和陈旧的统计信息的表、索引、分区
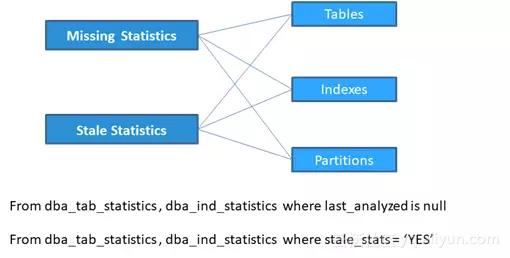
自动收集任务运行时,优先收集缺失统计信息的对象,然后再收集陈旧统计信息的对象。缺失或陈旧统计信息的对象,可以从dba_tab_statistics和dba_ind_statistics这两个视图中查询。
问:如何判断对象的统计信息为陈旧?
答:表或分区的数据变化量超过10%
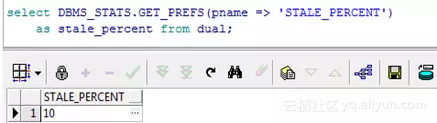
控制统计信息是否陈旧的数据变化量的比例默认为10%,可通过dbms_stats.get_prefs这个函数查询,这个值也可通过DBMS_STATS.SET_GLOBAL_PREFS修改,但一般不建议这样做。
问题分析到这里,之前提出来的四个问题的答案就已经全部解开了。
为什么拆分分区的初始化统计信息开始是空,而后面又变成 0 ?
----分裂出来的分区继承原分区的统计信息
为什么分区的统计信息为空时,自动收集任务运行后,统计信息更新了?
----缺失统计信息的对象,会被收集
为什么分区的统计信息为0时,这个分区有大量数据,而统计信息始终不更新?
----不满足缺失或陈旧的条件,不被收集
PEVER分区一开始是空,先插入了20000行,然后数据又分裂出去,重新变回一个空分区,为什么它的统计信息又更新了?
----陈旧统计信息的对象,会被收集
那么这个案例如何优化呢?有两种选择都可以解决问题:
a) 修改程序逻辑顺序:先插入数据再SPLIT分区 修改为 先SPLIT分区再插入数据
b) 手动补充收集一次:原业务逻辑不变,但操作完之后,对split出来的分区单独收集
知识扩展
莎士比亚说:大海有崖岸,热烈的爱却没有边界。虽然问题已经解决,仔细思考,还有更多细致的问题在等着我们去探索:
1、如何查询对象的数据变化量?
2、对象的数据变化是如何刷新的?
3、分区表统计信息的更新机制?如果整个分区表的数据更新,会不会扫描那些没有发生数据变化的分区呢?
如何查询对象的数据变化量?
oracle提供了一个名为USER_TAB_MODIFICATIONS的视图,可以查询到分区以及分区表的DML操作次数,例如:
select * from dba_tab_modifications wheretable_name='T_HISTDATA_PART';

这个视图还能查询到对象被truncate的次数。但是存在一个问题:数据修改之后,并不能马上在视图中查询到,需要手工刷新:
begin
dbms_stats.flush_database_monitoring_info();
end;
数据修改不能立即刷新的原因,就是下面要讨论的问题。
对象的数据变化是如何刷新的?
USER_TAB_MODIFICATIONS的刷新机制
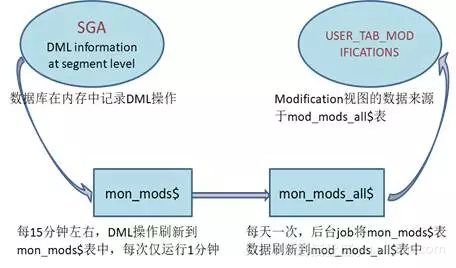
在10G之后,USER_TAB_MODIFICATIONS视图的数据并不能立即更新,而是每天只更新一次,因此需要通过这个视图准确查询到数据变化时,需要先手工刷新。
分区表统计信息的更新机制?
当分区的数据变化达到10%,自动收集统计信息任务运行时,会更新该分区的统计信息。
当分区表中所有分区中数据变化量的总和达到分区表总数据量的10%,会更新该分区表的统计信息。
分区表的统计信息收集更新时,以前必须要扫描该表所有的分区或整个表的数据,在10.2.0.5版本之后,可以设置分区表按增量变化统计,只收集有数据变化的分区。
要设置分区表按增量变化统计,可以设置表统计信息的incremental属性。

【学以致用】:对于一些数据量特别大的分区表,可以考虑设置INCREMENTAL=TRUE属性,能够显著提升分区表统计信息收集的速度。
不闻不若闻之,闻之不若见之,见之不若知之,知之不若行之。通过一个问题的深入剖析,逐层推进,我们看见了、理解了、实践了,最终也收获了。以上这些知识要点,在运维实战中,具备非常有价值的指导意义。
原文发布时间为:2017-09-19
作者:曾令军
本文来自合作伙伴“数据和云”,了解相关信息可以关注“数据和云”微信公众号