从接触DataX起就有一个疑问,它和Sqoop到底有什么区别,昨天部署好了DataX和Sqoop,就可以对两者进行更深入的了解了。
两者从原理上看有点相似,都是解决异构环境的数据交换问题,都支持oracle,mysql,hdfs,hive的互相交换,对于不同数据库的支持都是插件式的,对于新增的数据源类型,只要新开发一个插件就好了,
但是只细看两者的架构图,很快就会发现明显的不同
DataX架构图
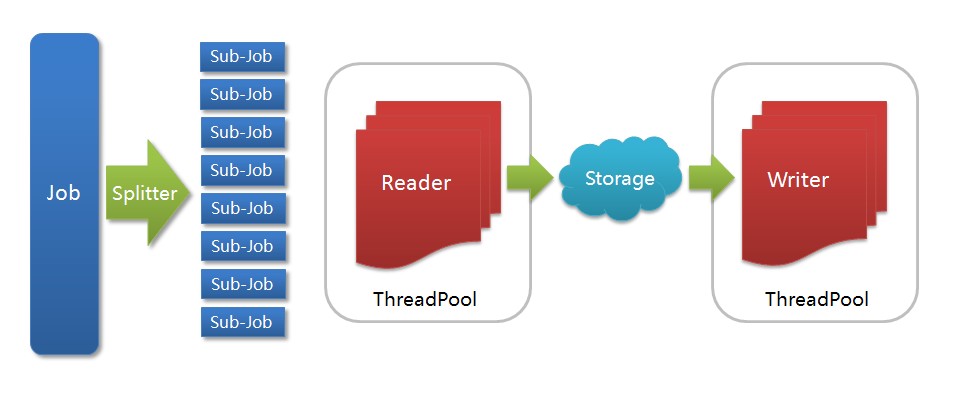
- Job: 一道数据同步作业
- Splitter: 作业切分模块,将一个大任务与分解成多个可以并发的小任务.
- Sub-job: 数据同步作业切分后的小任务
- Reader(Loader): 数据读入模块,负责运行切分后的小任务,将数据从源头装载入DataX
- Storage: Reader和Writer通过Storage交换数据
- Writer(Dumper): 数据写出模块,负责将数据从DataX导入至目的数据地
Sqoop架构图

DataX 直接在运行DataX的机器上进行数据的抽取及加载。
而Sqoop充分里面了map-reduce的计算框架。Sqoop根据输入条件,生成一个map-reduce的作业,在Hadoop的框架中运行。
从理论上讲,用map-reduce框架同时在多个节点上进行import应该会比从单节点上运行多个并行导入效率高。而实际的测试中也是如此,测试一个Oracle to hdfs的作业,DataX上只能看到运行DataX上的机器的数据库连接,而Sqoop运行时,4台task-tracker全部产生一个数据库连接。调起的Sqoop作业的机器也会产生一个数据库连接,应为需要读取数据表的一些元数据信息,数据量等,做分区。
Sqoop现在作为Apache的顶级项目,如果要我从DataX和Sqoop中间选择的话,我想我还是会选择Sqoop。而且Sqoop还有很多第三方的插件。早上使用了Quest开发的OraOop插件,确实像quest说的一样,速度有着大幅的提升,Quest在数据库方面的经验,确实比旁人深厚。
- Transfer highly clustered data more than five times faster than with Sqoop alone
- Avoid scalability issues that can occur with Sqoop when data has no primary key or is not stored in primary key order
- Reduce CPU by up to 80 percent and IO time by up to 95 percent
- Prevent disruption to concurrently running Oracle workload
- Get free use of Data Transporter for Hive, a Java command-line utility that allows you to execute a Hive query and insert the results into an Oracle table
在我的测试环境上,一台只有700m内存的,IO低下的oracle数据库,百兆的网络,使用Quest的Sqoop插件在4个并行度的情况下,导出到HDFS速度有5MB/s ,这已经让我很满意了。相比使用原生Sqoop的2.8MB/s快了将近一倍,sqoop又比DataX的760KB/s快了两倍。
另外一点Sqoop采用命令行的方式调用,比如容易与我们的现有的调度监控方案相结合,DataX采用xml 配置文件的方式,在开发运维上还是有点不方便。
附图1.Sqoop with Quest oracle connector
