1.1 从迭代到流的操作
在处理集合时,我们通常会迭代遍历它的元素,并在每个元素上执行某项操作。例如,假设我们想要对某本书中的所有长单词进行计数。首先,将所有单词放到一个列表中:
现在,我们可以迭代它了:
在使用流时,相同的操作看起来像下面这样: 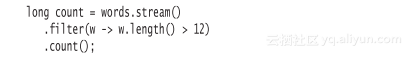
流的版本比循环版本要更易于阅读,因为我们不必扫描整个代码去查找过滤和计数操作,方法名就可以直接告诉我们其代码意欲何为。而且,循环需要非常详细地指定操作的顺序,而流却能够以其想要的任何方式来调度这些操作,只要结果是正确的即可。
仅将stream修改为parallelStream就可以让流库以并行方式来执行过滤和计数。
流遵循了“做什么而非怎么做”的原则。在流的示例中,我们描述了需要做什么:获取长单词,并对它们计数。我们没有指定该操作应该以什么顺序或者在哪个线程中执行。相比之下,本节开头处的循环要确切地指定计算应该如何工作,因此也就丧失了进行优化的
机会。
流表面上看起来和集合很类似,都可以让我们转换和获取数据。但是,它们之间存在着显著的差异:
1. 流并不存储其元素。这些元素可能存储在底层的集合中,或者是按需生成的。
2. 流的操作不会修改其数据源。例如,f?ilter方法不会从新的流中移除元素,而是会生成一个新的流,其中不包含被过滤掉的元素。
3. 流的操作是尽可能惰性执行的。这意味着直至需要其结果时,操作才会执行。例如,如果我们只想查找前5个长单词而不是所有长单词,那么f?ilter方法就会在匹配到第5个单词后停止过滤。因此,我们甚至可以操作无限流。
让我们再来看看这个示例。stream和parallelStream方法会产生一个用于words列表的stream。f?ilter方法会返回另一个流,其中只包含长度大于12的单词。count方法会将这个流化简为一个结果。
这个工作流是操作流时的典型流程。我们建立了一个包含三个阶段的操作管道:
1.?创建一个流。
2.?指定将初始流转换为其他流的中间操作,可能包含多个步骤。
3.?应用终止操作,从而产生结果。这个操作会强制执行之前的惰性操作。从此之后,这个流就再也不能用了。
在程序清单1-1中的示例中,流是用stream或parallelStream方法创建的。f?ilter方法对其进行转换,而count方法是终止操作。
程序清单1-1 streams/CountLongWords.java

在下一节中,你将会看到如何创建流。后续的三个小节将处理流的转换。再后面的五个小节将讨论终止操作。
java.util.stream.Stream 8
- Stream filter(Predicate<?super T> p)
产生一个流,其中包含当前流中满足P的所有元素。 - long count()
产生当前流中元素的数量。这是一个终止操作。
java.util.Collection 1.2 - default Stream stream()
- default Stream parallelStream()
产生当前集合中所有元素的顺序流或并行流。