一、MySQL的Hadoop Applier
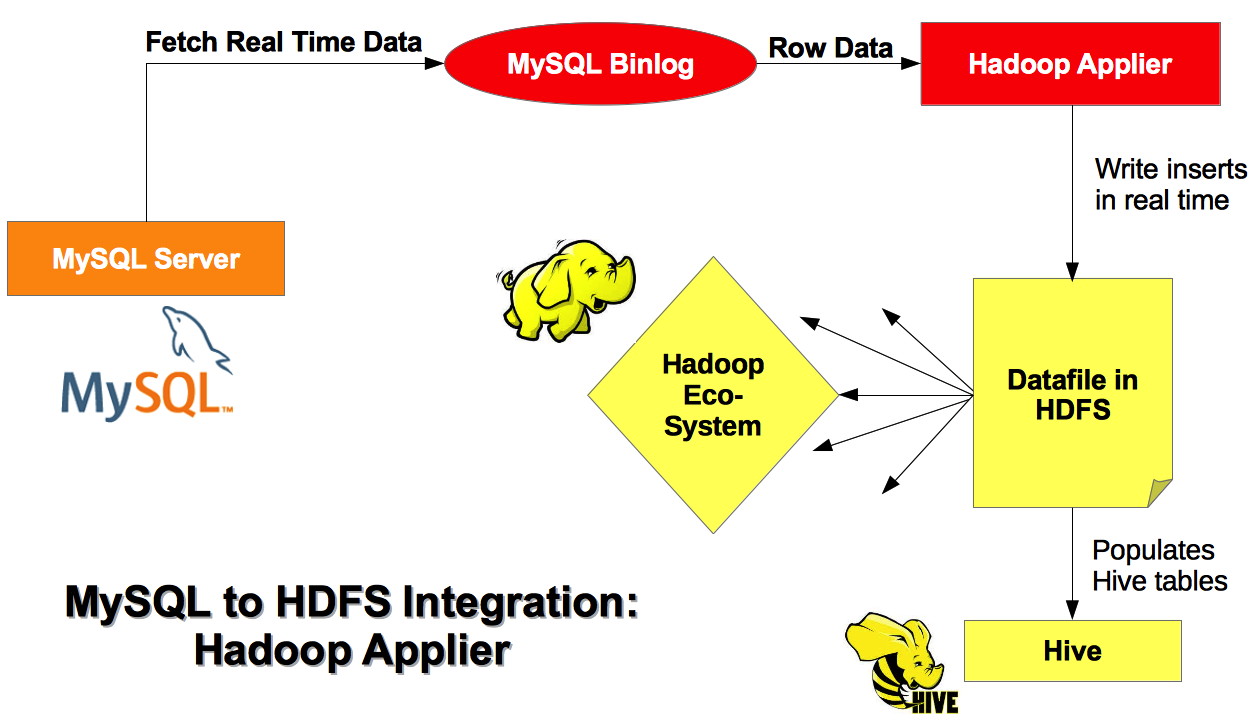
实现原理是:把hadoop作为MYSQL 的slave,实时把数据同步到hadoop,支持apache hadoop
通过分析MYSQL的binlog日志,在hdfs产生一个目录(同表名),所有的表记录都存储在一个文件中,用户的操作如插入,更新,删除都会产生一笔记录追加到文件末尾.
但如何利用hdfs上的这个数据,需要用户自己定义逻辑,把表中的数据插入到hbase表
详见:http://dev.mysql.com/tech-resources/articles/mysql-hadoop-applier.html
二、GoldenGate的HDFS Adapter
Oracle GoldGate's 也有类似的工具,通过分析Trails File把数据实时同步到hadoop
ORACLE官方网站提供了Hdfs Adapter,但不提供服务支持
详见:https://blogs.oracle.com/dataintegration/entry/streaming_relational_transactions_to_hadoop

时间: 2024-09-30 10:06:38