1.1短文本理解
短文本广泛地存在于互联网的各个角落,如搜索查询、广告关键字、锚文本、标签、网页标题、在线问题、微博等,都属于短文本。一般而言,短文本字数少,没有足够的信息量来进行统计推断,因此机器很难在有限的语境中进行准确的语义理解。此外,由于短文本常常不遵循语法,自然语言处理技术如词性标注和句法解析等,难以直接应用于短文本分析。正是由于这些特性,使得让机器正确理解短文本十分困难。然而,短文本理解又是一项对于机器最终实现人工智能至关重要的任务,其在知识挖掘领域有很多潜在应用,如网页搜索、在线广告、智能问答等。那么,如何才能够破解其中的挑战呢?
我们不妨首先跳出机器的范畴,看看人类是如何理解短文本的。对于人类而言,理解这些短文本是十分简单的。即使是一个10岁左右的儿童,当他们看到短文本(如搜索查询)时,都可以正确地理解这些短文本的含义。究其原因,是由于人类具有“思维”,能够积累知识并做出推断。例如,给出两个查询语句“band for wedding”和“wedding band”,人类可以清楚地判断前者指的是一项“婚礼乐队服务”,而后者是“结婚戒指”。而这种知识的积累,是人们通过不断学习而获得的。
为了使机器也具有类似的能力,先前的研究往往也会构造出一些知识库系统,如Freebase、Yago等为机器“装备”知识。这些知识库大多包含大量实体以及与之相关的事实。以搜索引擎或问答系统为例,基于这些事实,机器可以通过查询的方式获取输入问题的答案。然而,如图11所示,在机器回答问题前,首先需要解决的是“理解”问题,这也是这一过程中的最大挑战。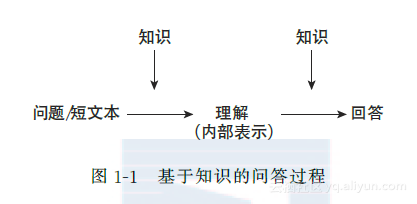
通过深入研究,我们发现理解短文本所需要的知识与回答短文本所需要的知识并不相同。例如,针对短文本“世界上第三大瀑布”,10岁的儿童可以正确理解其含义,但是却不一定能够正确回答这个问题。这是因为,理解短文本更需要的是常识性知识(注重广度),而回答短文本更需要的是专业性知识(注重深度)。因此,传统的知识库系统并不能很好地解决短文本理解问题。
为了克服机器理解短文本的障碍,先前基于短文本的应用常通过枚举和关键词匹配的方式避免“理解”这一任务。以自动问答系统为例,可事先构建关于问题和答案匹配的列表,这样在线查询时只需对列表中的条目进行匹配即可。近年来随着自然语言处理技术的发展,主流的搜索引擎正逐渐从基于关键词的搜索向文本理解过渡。例如,给出“apple ipad”这个短文本,机器需要明白“apple”所指为品牌名而不是水果。
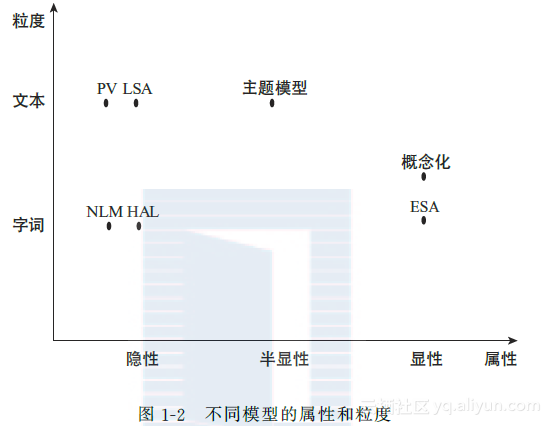
为了实现自动化的短文本理解,许多相关工作[54,153,172]证明,这一过程相当依赖额外的知识。这些知识可以帮助机器充分挖掘短文本中词与词之间的联系,如语义相关性。例如,在英文查询“premiere Lincoln”中,“premiere”是一个重要的信息,表明“Lincoln”在这里指的是movie(电影);同样,在“watch harry potter”中,正因为“watch” (观看)的出现,“harry potter”的含义可被判定为movie(电影)或DVD,而不是book(图书)。但是,这些关于词汇的知识(例如“watch”的对象通常是movie)并没有在短文本中明确表示出来,因而需要通过额外的知识源获取。图12展示了所有短文本理解方法在知识源属性和粒度的二维坐标轴中对应的位置。这些方法将在下一节逐一讨论。