一个复杂的分布式爬虫系统由很多的模块组成,每个模块是一个独立的服务(SOA架构),所有的服务都注册到Zookeeper来统一管理和便于线上扩展。模块之间通过thrift(或是protobuf,或是soup,或是json,等)协议来交互和通讯。
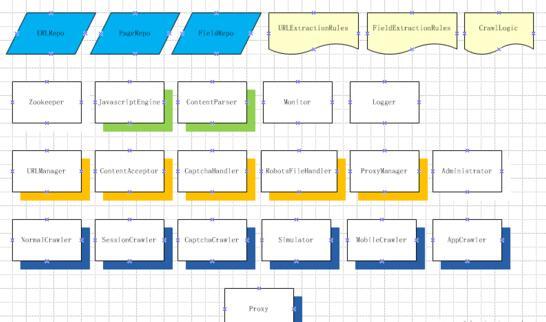
Zookeeper负责管理系统中的所有服务,简单的配置信息的同步,同一服务的不同拷贝之间的负载均衡。它还有一个好处是可以实现服务模块的热插拔。
URLManager是爬虫系统的核心。负责URL的重要性排序,分发,调度,任务分配。单个的爬虫完成一批URL的爬取任务之后,会找
URLManager要一批新的URL。一般来说,一个爬取任务中包含几千到一万个URL,这些URL最好是来自不同的host,这样,不会给一个
host在很短一段时间内造成高峰值。
ContentAcceptor负责收集来自爬虫爬到的页面或是其它内容。爬虫一般将爬取的一批页面,比如,一百个页面,压缩打包成一个文件,发送给ContentAcceptor。ContentAcceptor收到后,解压,存储到分布式文件系统或是分布式数据库,或是直接交给
ContentParser去分析。
CaptchaHandler负责处理爬虫传过来的captcha,通过自动的captcha识别器,或是之前识别过的captcha的缓存,或是通过人工打码服务,等等,识别出正确的码,回传给爬虫,爬虫按照定义好的爬取逻辑去爬取。
RobotsFileHandler负责处理和分析robots.txt文件,然后缓存下来,给ContentParser和
URLManager提供禁止爬取的信息。一个行为端正的爬虫,原则上是应该遵守robots协议。但是,现在大数据公司,为了得到更多的数据,基本上遵守这个协议的不多。robots文件的爬取,也是通过URLManager作为一种爬取类型让分布式爬虫去爬取的。
ProxyManager负责管理系统用到的所有Proxy,说白了,负责管理可以用来爬取的IP。爬虫询问ProxyManager,得到一批
Proxy
IP,然后每次访问的时候,会采用不同的IP。如果遇到IP被屏蔽,即时反馈给ProxyManager,ProxyManager会根据哪个host屏蔽了哪个IP做实时的聪明的调度。
Administor负责管理整个分布式爬虫系统。管理者通过这个界面来配置系统,启动和停止某个服务,删除错误的结果,了解系统的运行情况,等等。
各种不同类型的爬取任务,比如,像给一个URL爬取一个页面( NormalCrawler),像需要用户名和密码注册然后才能爬取(
SessionCrawler ),像爬取时先要输入验证码( CaptchaCrawler ),像需要模拟用户的行为来爬取( Simulator
),像移动页面和内容爬取( MobileCrawler ),和像App内内容的爬取(
AppCrawler),需要不同类型的爬虫来爬取。当然,也可以开发一个通用的爬虫,然后根据不同的类型实施不同的策略,但这样一个程序内的代码复杂,可扩展性和可维护性不强。
一个爬虫内部的爬取逻辑,通过解释从配置文件 CrawlLogic 来的命令来实现,而不是将爬取逻辑硬编码在爬虫程序里面。对于复杂的爬取逻辑,甚至可以通过用代码写的插件来实现。
ContentParser根据URLExtractionRules来抽取需要继续爬取的URL,因为focus的爬虫只需要爬取需要的数据,不是网站上的每个URL都需要爬取。ContentParser还会根据FieldExtractionRules来抽取感兴趣的数据,然后将原始数据结构化。由于动态生成的页面很多,很多数据是通过Javascript显示出来的,需要JavascriptEngine来帮助分析页面。这儿需要提及下,有些页面大量使用AJAX来实时获取和展示数据,那么,需要一个能解释Javascript的爬虫类型来处理这些有AJAX的情形。
为了监控整个系统的运行情况和性能,需要 Monitor 系统。为了调试系统,保障系统安全有据可循,需要 Logger 系统。有了这些,系统才算比较完备。
所有的数据会存在分布式文件系统或是数据库中,这些数据包括URL( URLRepo),Page( PageRepo )和Field( FieldRepo ),至于选择什么样的存储系统,可以根据自己现有的基础设施和熟悉程度而定。
为了扩大爬虫系统的吞吐量,每个服务都可以横向扩展,包括横向复制,或是按URL来分片(sharding)。由于使用了Zookeeper,给某个服务增加一个copy,只用启动这个服务就可以了,剩下的Zookeeper会自动处理。
这里只是给出了复杂分布式爬虫系统的大框架,具体实现的时候,还有很多的细节需要处理,这时,之前做过爬虫系统,踩过坑的经验就很重要了。
作者:佚名
来源:51CTO