更多深度文章,请关注云计算频道:https://yq.aliyun.com/cloud
简介
去年,职业社交网站 Linkedin 报道称,近年来雇主最重视的技能就是数据技能。而推崇数据导向文化的谷歌,其首席经济学家 Hal R.Varian 博士更完整地阐述了行业真正的数据技能需要——“理解数据、处理数据、从中抽取价值、将其可视化、并表达其中的意义,这是未来十年及其重要的技能。”简而言之,就是用数据讲故事的能力。

谷歌首席经济学家 Hal R. Varian 博士
不管是朝你砸玩具的熊小孩,还是不知道如何沟通的客户,最好解决办法无非是:给你讲个故事。要让你的老板、客户或者从未谋面的听众“听话”,最好的办法,就是放弃容易引发数据恐惧症的Excel 表格,拿出可视化工具,用数据讲故事。
举个例子。如果你想说明“男性与女性在驾驶分心因素中的差异”,你可以这样说:
- 6%的男人和4.2%的女性觉得发短信聊天是驾驶中分心的原因;
- 车里有小孩是9.8%的男性和26.3%的女性驾驶分心的原因。
或者,你可以这样说: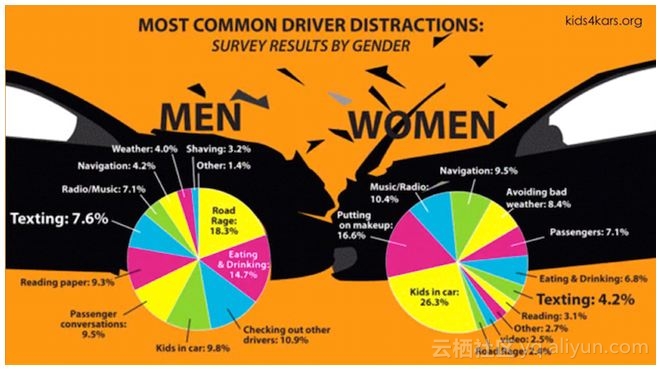
上图是儿童慈善机构 kids4kars.org 的作品。
你更喜欢哪一种叙事方式?
我们都爱听故事
讲故事很简单、也很难。在很多数据驱动的团队里,大家很容易觉得故事是肤浅的,觉得事实本身就足够说服听众了,但是讲故事可以最好的体现和解释数据的价值。
数据为什么有用?因为数据能告诉我们,如何更好的制定决策。很多企业中,分析的第一步是故事板。故事板的概念源于电影制作,安排剧情中的重要镜头,相当于一个可视化的剧本。有时候,不用做复杂的相关分析,将数据可视化就能够讲好一个故事。
安斯库姆四重奏(Anscombe’s Quartet)就是一个很好的例子,里面包含里里四个数据库,每一个的数据总结都非常相似。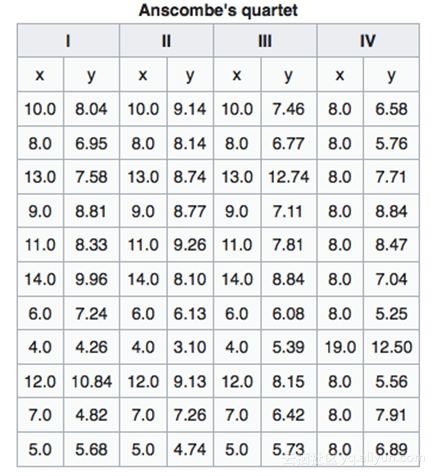
但是如果你这些数据可视化: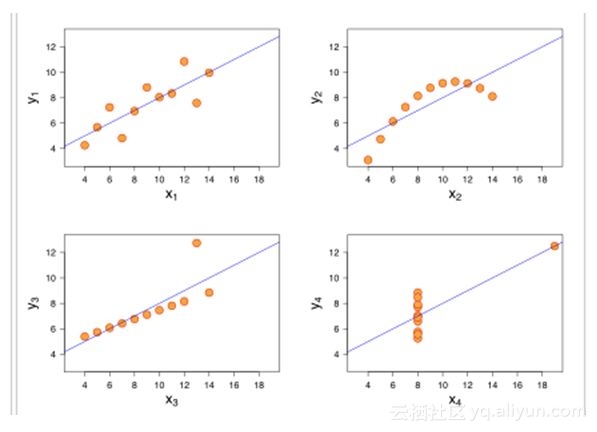
是不是听到了美妙的四重奏!
如何讲故事
第一步,故事都有情节。让我用一个包含 NASDAQ 100 科技公司新闻标题的数据库为例子,一步步来分解讲故事的步骤。项目栏包括以下部分:
- Headlines.Securities.Symbol: 依据每一个公司的代码对数据进行筛选和分组。
- Headline.Securities.CategoryorIndustry: 哪一些新闻对其行业具有相关性。市场情绪也许只针对行业内某一些公司。
- Headlines.Title:标题,理解当天市场情况最重要的因素之一。
- Headlines.Date:基于月份和日期分类新闻。
- Headlines.Source:新闻来源。
- Headlines.Url:新闻链接。
具体步骤
1. 回归复古的纸和笔。
虽然我们生活在数字化的时代,不过,有些超棒的数据故事在进入 PPT 之前,其实是在餐巾纸上画出来的。在开始制作故事结构之前,写下你的想法和故事流。
亚里士多德有一个经典的“五大要点”方法:
1)先做一个陈述,引起观众的注意。
2)提出一个需要解决的问题。
3)提出一个解决方法。
4)描述你的解决方法会带来哪些好处。
5)提出一个行动呼吁。
假设现在我要写一个报告,如何用数据更好地进行投资决策。做一个折线图可以分析出这些股价的趋势。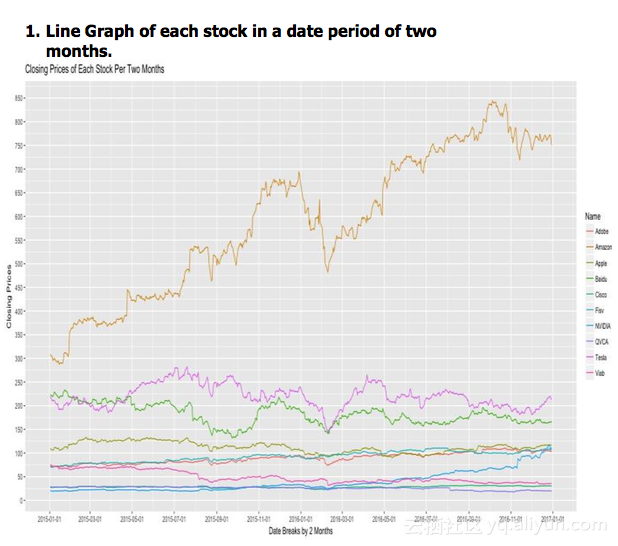
我们可以看出,2016年2月所有股价都下跌了。我们可以抓取那个时期的新闻,分析到底发生了什么。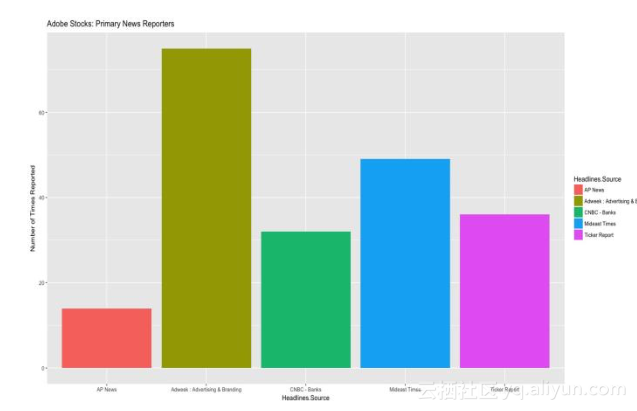
我们可以找到哪一个媒体对某一个股票的报道最多,这个媒体也许就是关于这个股票最好的消息来源。
2. 深挖故事的意义
为什么你在讲这个故事?故事本身并不重要,重要的是故事如何能让我们更好地进行决策。
用一句话,说明为什么你对你所做的这件事抱有热情。
3.取一个强大的标题
一句话概括你的故事、标题和分析。最有效的标题必须简洁、具体、并告诉读者你能从中得到什么好处。
记住,标题是给读者看的,不是给你自己看的。
4. 设计一个路线图
写下你想让观众知道的是什么,写下所有的关键点。
将你的关键点归类、合并,直到最后你手上有的不是100个关键点,而是三个大类。
这三个大类就是你的路线图。
在每一个大类下面,加上支持你论点的证据,可以包括个人故事、事实、例子、类比等等。
5. 简短总结
既然已经陈述了所有的要点,现在,就该来一个强大的收尾了。我的报告结尾,在每一个股票后面都写了三到四行,总结为什么要买这个股票。
数据类型及适合图标
常见的数据类型如下:
1. 文字数据
文字数据适合研究文字中的情绪,这种数据最适合讲故事。
WordCloud 是最适合文字数据的可视化类型,将最常见的文字放在最中心、字体最大,让读者一眼就看出文字要体现的总体思想。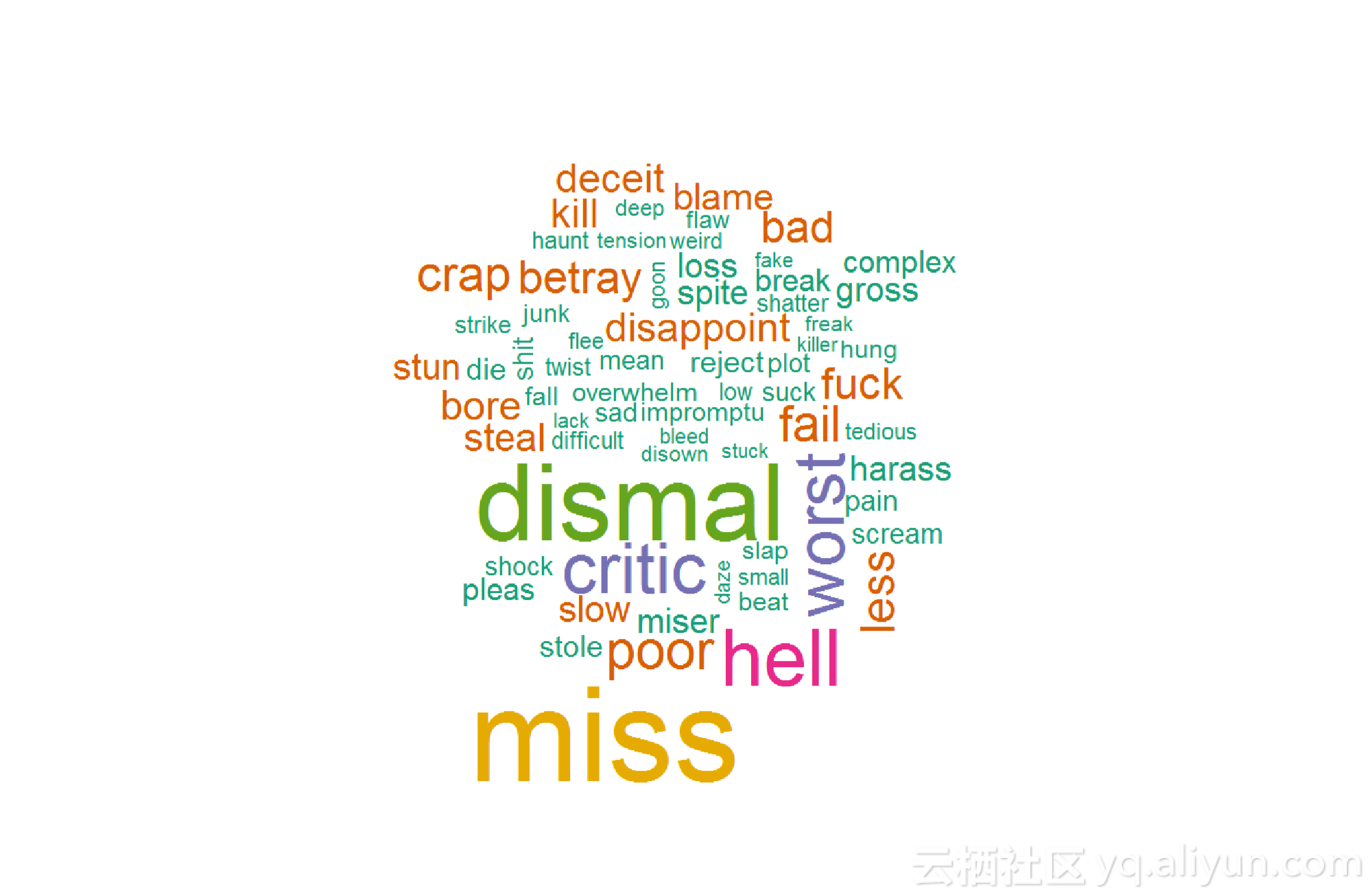
上图直观地体现了一个 Twitter 数据库的内容,一眼就能看出其中最突出的情绪:“阴沉”、“缺失”、“失望”等。
2. 混合数据
当数据中不仅有数字,还有其他的数据形式,我们需要确定哪一种形式最能体现数据中的洞见。
我先以网格分面为例,分析泰坦尼克号乘客的数据。
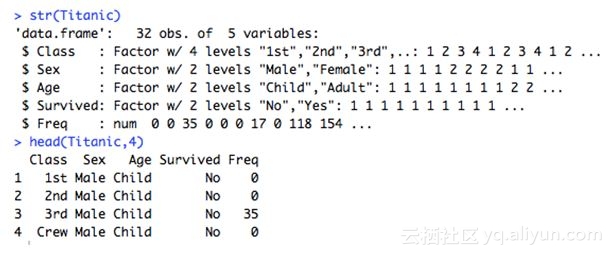
而下图直观地体现了不同性别和舱位级别的生存率。
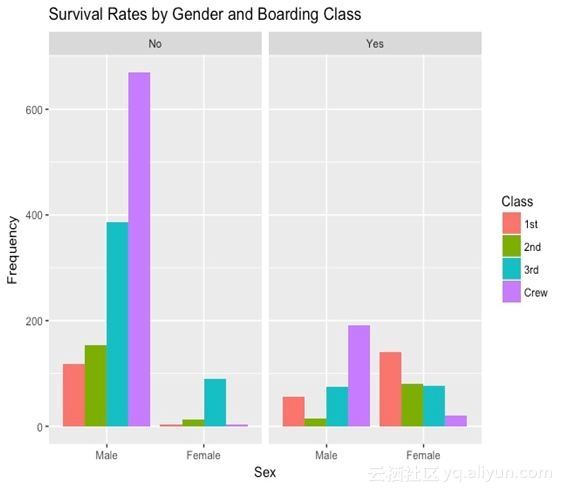
我们可以看出,女性和头等舱乘客的生存率稍高一些,而男性、低级别舱位及工作人员的生存率更低。嗯,这和我们从电影中得到的印象一致。
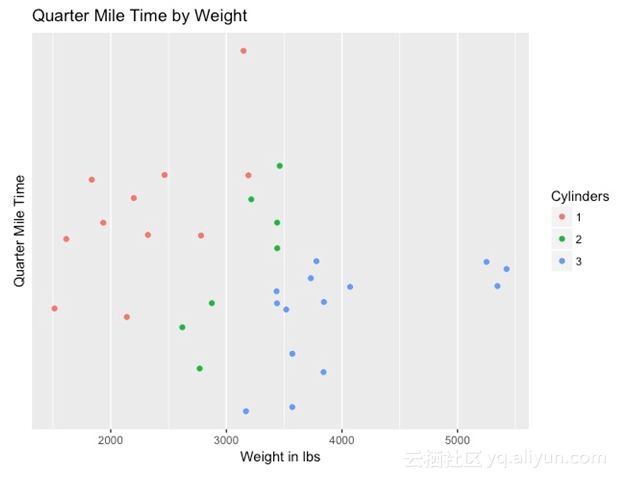
另一种可视化的方式是多元变量图。以下使用的数据库是汽车性能规格数据库。
这让人看得一百个头大。所以我们做出了下图,这样不难看出,更重的车身会让汽车跑得更慢。
3. 数字数据
通常对于数字数据我们要找的是趋势。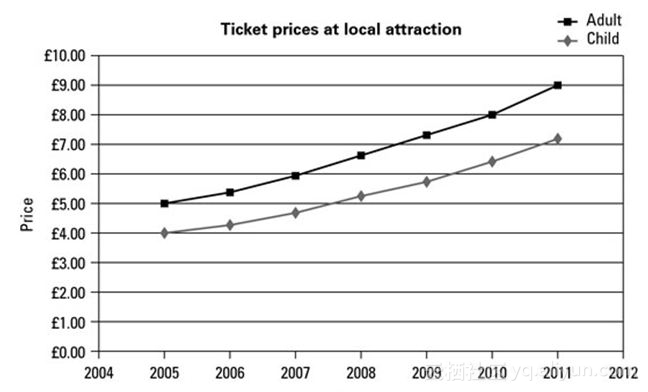
横轴是时间,纵轴是票价,黑色线是成人,灰色线是小孩。我们可以清楚看到在这个游乐园,成人和小孩的价格都上涨了,而且对每一年上涨的程度也有个直观的感觉。
4. 股票
股票市场的信息基本上就是一个时间序列数据,而投资人希望能够理解每一个时间点与价格下跌。
下图的 K 线图是一个很好的例子。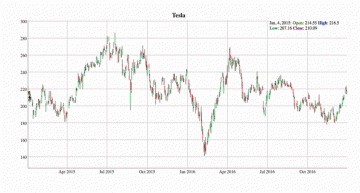
我们可以看看特斯拉的股价。2016年2月特斯拉股价出现了较大的下跌,我们可以去调查当时的市场情况和经济环境,在未来更好地进行股票投资。
5. 地理数据
把不同地区的信息标记在地图上,能让分析更加清楚和有意义。
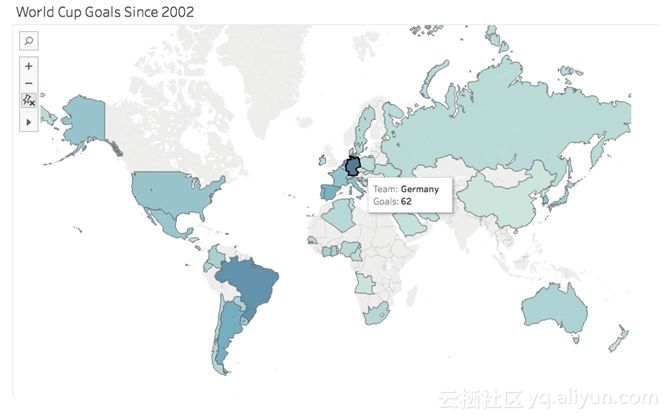
上图中,我们可以看到2002年世界杯各国到进球数,德国的进球数最高。
预测性模型如何讲故事
我们先来理解建造模型的步骤,看看故事能在其中发挥什么作用。
1. 数据探索
建立模型的第一步是理解你的数据。不一定先得进行复杂的统计计算。
我们来看看红酒质量的数据库,数据库的结构如下:
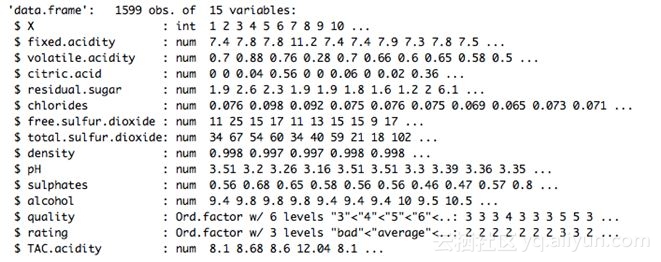
以下是数据总结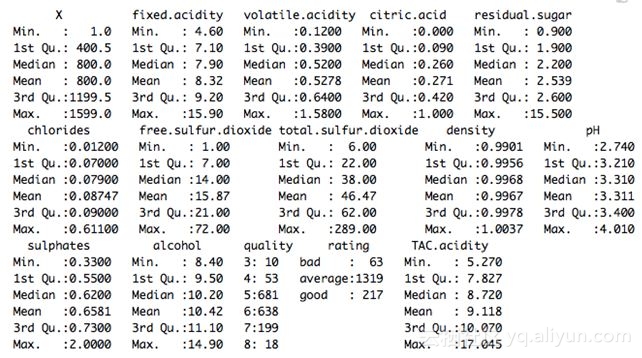
如果我们想知道酒精量和红酒质量之间的关系,该怎么办?
我们可以计算 Pearson R值,可以帮助打造一个模型。但是对于分析没有什么用。
这意味着酒精量和红酒质量之间有很强的关联。此外你还了解到了什么?并没有。
所以我们来将数据可视化一下:
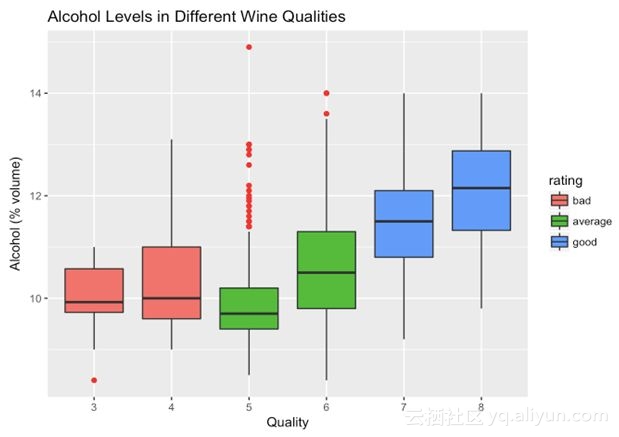
首先,我们看到更高的酒精量与更好的红酒质量相关,我们也可以更清楚地看到有一些例外存在。
然后,你觉得红酒的酸度与质量有关吗?
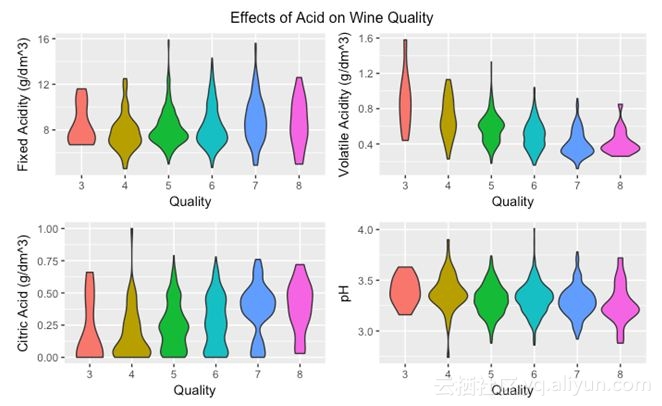
我们可以用小提琴图来体现酸度,小提琴图能体现在哪些区域内有更多的数据点。
2. 特征可视化
生成了特征之后,你如何看到预测得如何?
我们可以以主成分分析(PCA)为例。关于 PCA 更深入的内容可以看这篇文章。
这是 RStudio 中的 Iris 数据库。
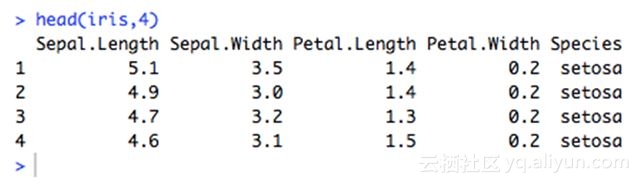
我们进行 PCA 的时候会发现这些数据:

一直盯着这张表可能也看不出什么。如果做成可视化图表,我们得到的信息会更多。
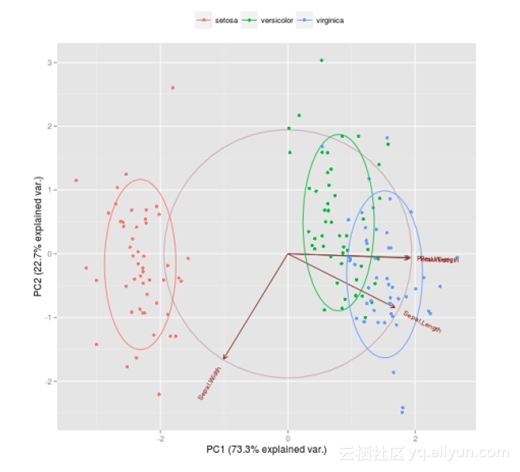
3. 创造和比较模型
这个模型能基于道路颠簸度的情况,预测车辆应该走快一点还是放慢一点。
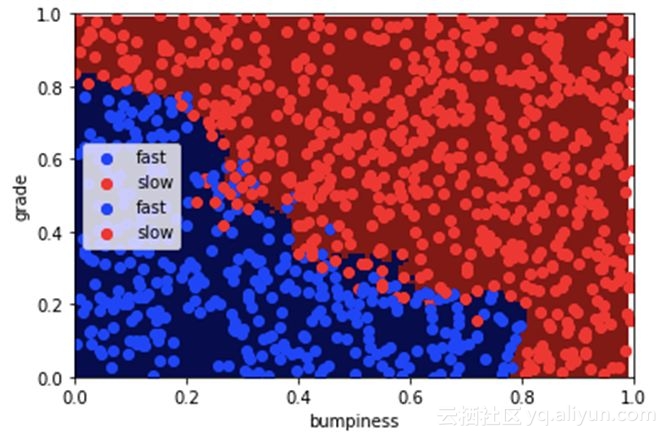
决策边界将大部分数据清楚分类了,不过,88.21%的精确度并不算一个故事。
以下是另一个使用 Iris 数据库的例子:
要推导出有价值的内容,这里的信息不够多。要更深入地了解支持向量机,可以看这篇文章。
另一方面,这张图表展示了一个清楚的分类边界。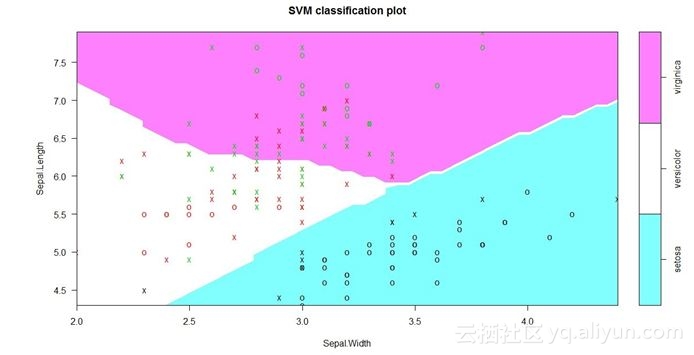
讲故事的实用贴士
- 图表一定要标记好横轴和纵轴,写好恰当的标题。
- 必要的时候使用图例。
- 使用视觉上比较柔和的颜色。
- 避免增加非必须的信息,例如过于复杂、降低可读性的背景或主题。
- 基于横纵位置信息、要同时编码两个量值的话,只能使用一个点。
- 制作时间序列编码的时候,不要用点进行可视化。
结束语
数据中特征与数据的关系,数字揭示不了的,但故事和图表可以。故事可以在各种情况下更好地解释细节。现在,你也可以开始讲述你的数据故事了。
文章原标题:《The Art of Story Telling in Data Science and how to create data stories?》文章为简译,更为详细的内容,请查看原文
译者:炫。
本文由用户为个人学习及研究之目的自行翻译发表,如发现侵犯原作者的版权,请与社区联系处理yqgroup@service.aliyun.com