2.4 Buffer Cache
2.4.1 Buffer(Cache)Pool
1. Buffer(Cache)Pool组成结构
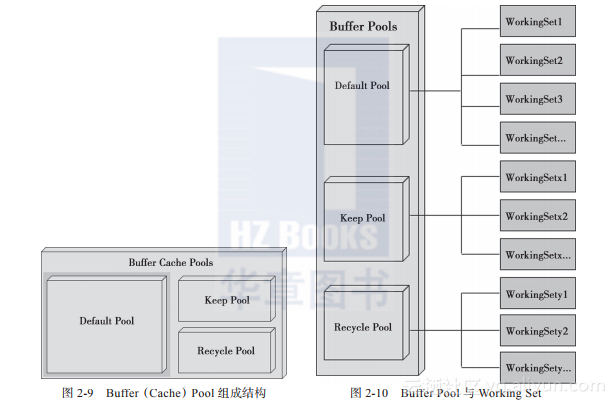
Oracle Buffer Cache由3个Buffer Pool组成,如图2-9所示。
其中:
Default Pool:默认池,用于缓存常规数据;
Keep Pool:保留池,主要用于缓存频繁更新的小表;
Recycle Pool:回收池,用于缓存随机使用的大表。
2. Buffer Pool与Working Set
Buffer Pool与Working Set的关系如图2-10所示。
可以看到:
Default Pool包含了多个Working Set;
Keep Pool包含了多个Working Set;
Recycle Pool包含了多个Working Set。
我们可以通过查询x$kcbwbpd(Buffer Pool)与x$kcbwds(Working Set)来获取Buffer Pool中Working Set的分布情况,如下所示: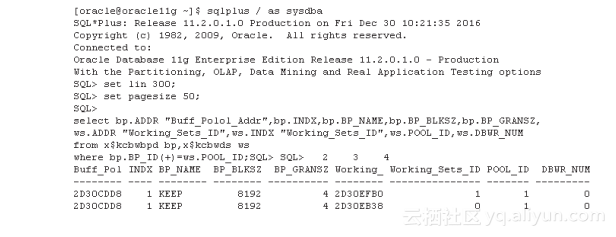

上面查询验证了图2-10的内容:
Default Pool包含12个Working Set;
Keep Pool包含2个Working Set;
Recycle Pool包含2个Working Set。
3. DBWR与Working Set
(1)Working Set组成结构
Working Set由功能独特的List组成,如表2-4所示。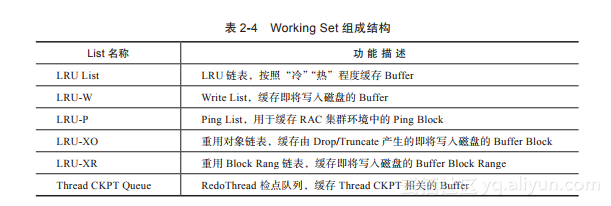
(2)DBWR与Working Set的关系
DBWR与Working Set的关系如图2-11所示。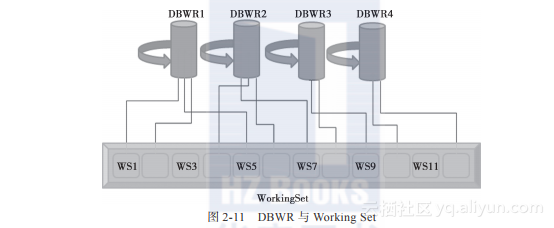
图2-11 DBWR与Working Set
可以看到:
一个DBWR进程负责多个Working Set;
DBWR进程与特定的Working Set相对应,以轮询(类似CPU时间片分片)的方式进行写数据操作。
(3)DBWR相关参数
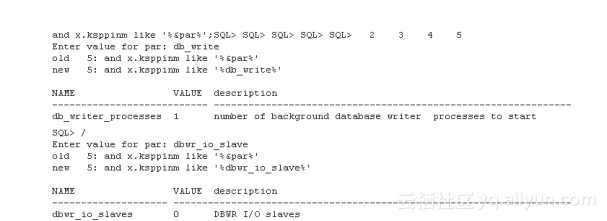
参数db_writer_processes/ dbwr_io_slaves决定了DBWR进程启动数量以及DBWR子进程的数量。在特定的场景下,可以通过适当增加这些参数值来达到数据库优化的目的,如下所示:
(4)DBWR写触发条件
DBWR写进程触发条件主要有:
写“脏”块;
回收LRU List空间;
检点(Checkpoint);
RAC Ping Writes。
(5)DBWR写优先级
DBWR进程写磁盘的优先级如表2-5所示。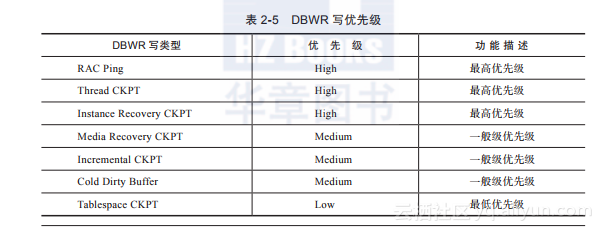
DBWR写优先级是系统内部预定义的,按照内部优先级顺序排序固定。
2.4.2 Cache Buffer Chain(Latch)
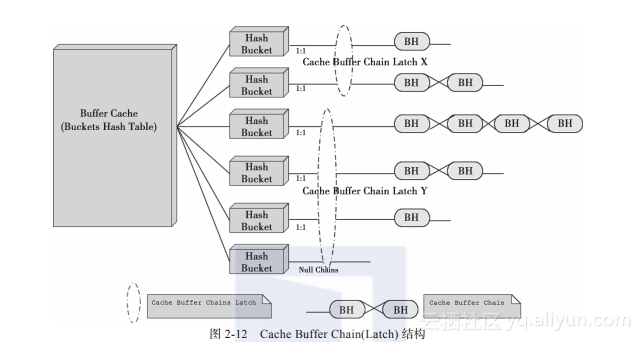
1. Cache Buffer Chain(Latch)结构
Cache Buffer Chain(Latch)结构如图2-12所示。
接下来对Cache Buffer Chain结构进行验证。
1)查询并获取Cache Buffer Chain(Latch)相关参数,如下所示:
2)Dump Buffers获取Cache Buffer Chains信息: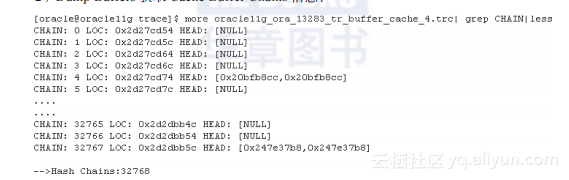
3)结合前面内容,可以获取如表2-6所示的信息。
不难看出:
Buffer Cache中的Buckets Hash Table包含了大量的Hash Bucket(32768);
Hash Bucket的数量(32768)与Cache Buffer Chain的数量(32768)一一对应,与参数_db_block_hash_buckets(32768)一致;
Cache Buffer Chain Latche的数量(1024)与参数_db_block_hash_latches保持一致;
一个Cache Buffer Chain Latch负责管理多个Cache Buffer Chain。
Cache Buffer Chain可能存在空(Null)Chain。在这种情况下,Chain上没有挂载BH(Buffer Header)。
2. Cache Buffer Chain(Latch)相关查询
可以通过v$latch/v$latch_children来查询Cache Buffer Chain(Latch)相关信息,如下所示: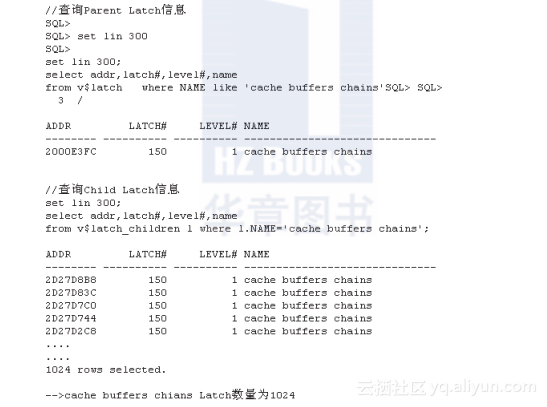
可以看到有1024个Cache Buffer Chain(Latch),与初始化参数_db_block_hash_latches完全吻合。
2.4.3 Cache Buffer Pin
一般而言,Cache Buffer Chain(Latch)与Cache Buffer Pin的主要用途有:
Cache Buffer Chain(Latch):用于保护Chains完整性;
Cache Buffer Pin:保护Buffer Block内容(Content)的完整性。
1. Cache Buffer Pin与(User)Wait List
Cache Buffer Pin结构中包含了Pin相关的信息,当被阻塞的会话没有请求到Pin时,就可以将自己地址信息等提交到Wait list的末端进行等待。等待事件为“buffer busy wait”,由参数_buffer_busy_wait_timeout决定,默认为1秒钟。如下所示:
当Session以Exclusive(X)模式Pin住Buffer Header后,请求Pin住该Buffer Header的Session都会加入到Wait List的末端,同时触发“buffer busy wait”等待;
当等待时间超过_buffer_busy_wait_timeout阈值后,等待Session将被唤醒,同时Pin持有者和等待者之间将会产生死锁。解决死锁的主要方式是释放该Buffer Header上的所有Pin,同时再次尝试获取该Buffer Header Pin。
2. Cache Buffer Pin工作模式
当获取了Cache Buffer Chain(Latch)后,可以进行以下操作:
从该Chain中添加或者删除Buffer Header;
从Pin List中添加或者删除Pin;
更改Pin的模式(S/X)。
只有在X模式下的Pin才能修改Buffer内容 。一般来说,当将Pin加在Buffer上后,没有必要立即就释放该Pin。在某些情况下,查询优化器“预测”在不久的将来需要再次访问该Buffer,那么就会将Pin延迟到下一次User Call。从某种意义上讲,Oracle Pin住Buffer直到下一次User Call,是访问Buffer成本最低的方式。
3. Cache Buffer Pin与参数_db_block_max_cr_dba
当需要更改Buffer Block的内容时,必须使用Cache Buffer Pin进行保护。如果这时对该Buffer Block进行查询,那么系统就会以当前Pin住的Buffer Block为基础块,重构CR镜像。
参数_db_block_max_cr_dba限定了单个Block Buffer的最大CR镜像数量,同时从侧面限制了Chain的长度,提高了Chain扫描的速度,默认为6。如下所示:
以下步骤演示了Cache Buffer Chain(Pin)与参数_db_block_max_cr_dba的关系。
1)Dump特定Buffer Block,语法如下:
alter session set events 'immediate trace name set_tsn_p1 level ts#';
alter session set events 'immediate trace name buffers level level#'
其中:
ts# = relative_fille# + 1
level# = 4194304×relative_fille# + block#
2)创建基表,并获取表相关信息,如下所示:
在这里:
relative_fille# = 4
ts# = relative_fille# + 1 = 5
level# = 4194304×relative_fille# + block# = 16777551
3)Dump特定Buffer(Level2):
使用命令:
alter session set events 'immediate trace name set_tsn_p1 level 5';
alter session set events 'immediate trace name buffer level 16777551'
进行Dump,Dump结果如下所示:

4)整理Dump结果,如表2-7所示。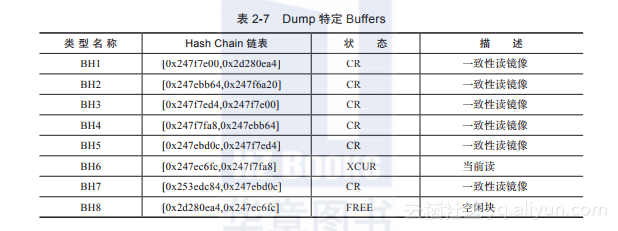
5)Buffer Header的Hash链表关系如图2-13所示。
图2-13 BH与Chain
从上面的关系中不难看出:
BH间以哈希键值对组成双向链表,从逻辑上组成Cache Buffer Chain;
单个DBA最大CR为6,与参数_db_block_max_cr_dba完全吻合;
为了提高Cache Buffer Chain的检索速度,当单个Chain超过一定长度后,系统会将原有的Chain断链,分裂组合成新的Chains。在这里,单个DBA的CR镜像分裂形成2条新Chain(Chain1、Chain2)。
2.4.4 Buffer Cache等待与优化
1. Buffer Cache等待事件
Buffer Cache等待事件主要分为3个级别:
用户级等待;
后台进程级(DBWR)等待;
RAC集群级等待。
其中,DBWR后台进程等待事件产生于DBWR进程将Buffer写入磁盘以及扫描LRU List的等待,包含DBWR写操作超时、请求释放空间时扫描LRU List的时间消耗、Check-point检查点。
Buffer Cache常见等待事件有:
buffer busy waits;
free buffer waits;
write complete waits。
2. Buffer Cache IO和DBWR优化
Buffer Cache的IO以及 DBWR优化主要集在以下几个方面:
维持好的Buffer Cache 命中率,一般要求大于90%,如下所示:
考虑采用高性能IO硬盘,如SSD硬盘灯,可以提升iops、tps等;
将物理存储条带化,使得物理IO均衡到多个磁盘,减少IO争用;
使用直接IO加载、直接插入操作,跳过Buferr Cache缓冲区,直接写入物理存储文件;
考虑适当调节参数_sort_multiblock_read_count/db_file_multiblock_read_count来提高IO性能,如下所示:

在特定场景中,考虑增加DBWR并行度,通过参数dbwr_io_slaves/db_writer_processes进行设置,如下所示:
- Buffer Busy Waits(Free Buffer Waits)优化
(1)Buffer Busy Waits优化
Buffer Busy Waits产生的主要原因:
多个Session访问同一个Buffer Block;
多个Session等待同一个Buffer Block(Pin X)的更改提交(与事务相关)。
Buffer Busy Waits的解决办法如下:
考虑将热块数据分离到不同Block,例如,增加pctfree百分比;
对于索引热块的争用,可以考虑使用Reverse Index将热块分裂到不同的块;
优化数据存储方式,采用非顺序的方式随机将同一个块中的记录分散到不同数据库块中。
(2)Free Buffer Waits优化
Free Buffer Waits产生的主要原因:
LRUW过满;
DBWR进程不能及时快速清理LRUW List。
Free Buffer Watis的解决办法如下:
增加DBWR批量写大小,通过参数_db_large_dirty_queue进行设置,如下所示:

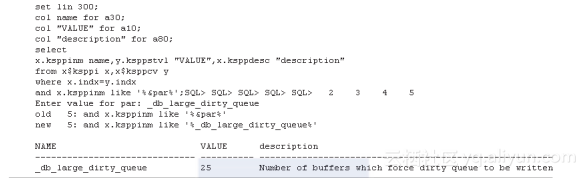
参数_db_large_dirty_queue在10g中默认为30,在11g中默认为25。
采用SSD条带化磁盘,使得DBWR能够更快的写到磁盘;
使用异步IO,使用参数_dbwr_async_io进行设置,如下所示:
可以考虑适当减少LRU List的数量 ;
在使用多个LRUW List的时候使用多个DBWR进程;
确保“cache buffers lru chain latch”命中率高于99%,如下所示:
使用直接IO加载、直接插入操作,跳过Buffer Cache,提升DBWR写磁盘速度。