引言
在上一篇文章中人工智能PK金牌速记员之实战录,我们讲述了阿里云年会人机大战背后的故事。技术Geek们可能就好奇了?现场的实时转录系统是怎么回事? 其中核心的语音识别系统到底是什么,工作原理是什么? 阿里云iDST的语音识别系统准确率为什么可以做到这么高,有什么独得之秘?本文将会将这些问题的答案一一揭晓。
人机大战之现场

阿里云年会现场,图中左边屏幕显示的是语音识别,右边屏幕显示的是人工速记
上图是视频的截图,展示的就是阿里云年会人机大战的现场情形, 阿里云的掌门人孙权在台上演讲,自动语音系统和速记员分别给出演讲的文本内容,同时投屏,现场PK正确率。其中,左边的屏幕展示语音识别的结果,作为字幕显示在实时图像上;另一边则是全球速记亚军姜毅先生将演讲内容速记下来,以白屏黑字的方式显示给观众。
现在问题来了,阿里云iDST的系统是如何做到实时转录并将语音识别的结果作为字幕展示给观众的呢?
实时转录系统架构
这里给出了演示系统的软硬件架构如下图所示。
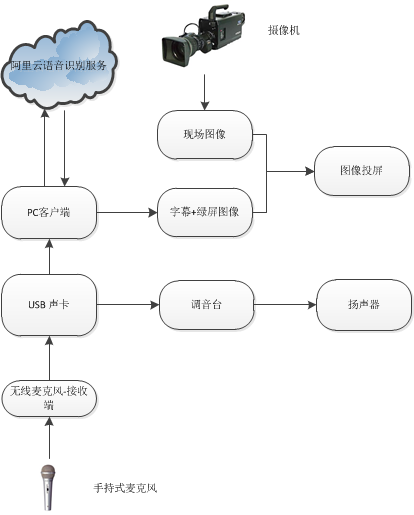
- 音频方案
在音频方面,现场嘉宾的讲话内容通过无线麦克风传递到USB声卡。为了实现同时语音识别和现场放音的效果,USB声卡的输出中一路送到调音台然后到现场的扬声器播放给观众,另一路则通过PC软件进行音频采集,将采集到的音频数据发送到阿里云语音服务器上运行语音识别,并将语音识别的文本结果实时返回,为实时产生字幕做准备。
- 视频方案
在视频方面,现场也会产生两路视频输入: 一方面摄影师通过摄像机拍摄嘉宾演讲的画面传回到中控台;另一方面,流式返回的语音识别结果文本通过渲染产生滚动的字幕效果,并展示在一个纯绿屏图像上。最后,在中控台处,通过抠屏软件将滚动的字幕叠加在嘉宾演讲画面上,产生实时字幕的效果。
在整个系统中,最为核心的算法部分就是一个是语音识别服务部分,它的作用就是将嘉宾的演讲内容实时转换为文本内容。那么现在问题又来了,语音识别是怎么工作的呢?
语音识别技术概览
语音识别就是把语音转换为文字的技术。经过几十年的发展,它已经成为目前人工智能领域发展的较为成熟的一个应用方向。那么看似神秘的语音识别技术背后的基本原理到底是怎么回事呢?鉴于篇幅原因,这里只简单的解释一下语音识别的基本原理。

目前,主流的语音识别系统多采用统计机器学习方法完成。一个典型的语音识别系统由以下几个模块所组成:
- 语音采集模块。在此模块中,麦克风录入的语音通过采集之后得到一个数字化的语音信号表示,比如一个16k采样率16bit的数字化语音表示,就是将每秒的语音表示为1,6000个16-bit的整数;
特征提取模块。该模块的主要任务是把采集的数字语音信号转换为特征向量,供声学模型处理; - 声学模型。声学模型用来表征人的语音跟语音识别产生的文本在声音上的相似程度。传统上通常使用隐含马尔科夫模型-混合高斯模型(HMM-GMM),近些年多使用隐含模型科夫模型-深度神经网模型(HMM-DNN)或者其他改进模型表示。
- 发音词典。发音词典包含语音识别系统所能处理的所有的词汇及其发音,发音词典实际提供了声学模型建模单元与语言模型建模单元间的映射关系。
- 语言模型。语言模型对系统所针对的语言进行建模,用来评估识别出的文本的“流畅程度”。目前应用最广的一种是基于统计的N元文法(Ngram)及其变体。
- 解码器。解码器是语音识别系统的核心之一,其任务是对输入的特征矢量,根据声学模型和语言模型,寻找能够以最大概率输出该特征矢量的词串,通常使用基于束搜索(beam search)的维特比算法完成这个搜索过程。
上面所述就是一般的语音识别系统的背后基本原理,在很多科普性的介绍中都有所涉及。实际上iDST的语音识别系统也落在上述介绍的基本框架中,但是iDST的语音识别系统为什么有这么高的准确率,有什么独得之秘呢?
IDST语音识别系统
台上一分钟,台下十年功。在阿里云年会上iDST语音识别系统所展示的超高准确率是建立在iDST语音团队同学丰富的业界经验和过去一年辛勤工作所产生的深厚积累上的。这里就简单介绍一下iDST语音识别系统所有的独到特点。
- 业内领先的声学模型建模技术BLSTM
在语音识别的声学模型方面,iDST团队拥有业内最领先的BLSTM (bi-directional long-short-term-memory) 建模技术,可以通过序列建模的方式,同时使用语音时序序列中的历史信息和“未来”序列信息;保证了声学模型建模的最佳准确性,有效地提升语音识别的准确率,相比于上一代的基于深度神经网(DNN)的声学模型建模方法,相对性能提升可以达到15%-20%。为了实现BLSTM技术,iDST语音组的同学还原创性的解决了BLSTM在训练效率和实际部署中的延迟问题, 成为世界上第一个在工业实时系统中部署BLSTM技术的团队, 关于该技术的介绍请参考云栖文社区的文章。
- 业内领先的超大规模的语言模型建模技术
正如上一章所说,语言模型在语音识别系统中的作用就是用来评估句子的通顺程度。语言模型的一个核心指标是模型对测试文本的匹配程度(使用困惑度来表示)。在实际应用中,语言模型对领域的相关性越强,对语料的覆盖度越高,识别效果就越好。为了增加语言模型的覆盖度,保证对各个领域的识别性能。iDST借助阿里云的计算优势,使用了全网语料作为训练数据,自主开发了基于Max-Compute的并行语言模型训练工具, 训练产生了规模高达百亿 ngram 条目的超大语言模型(模型文件大小高达数百G字节)。正是有了这样大规模的语言模型,使得iDST的语音识别系统可以很好的识别很多生僻的词,比如“芈月传中的葵姑扮演者”这种新潮词,比如古诗词的识别,比如各种学科术语等等,都不在话下。
- 业内领先的语音识别解码技术
语音识别解码器是语音识别在工业界部署的核心问题。虽然解码器的基本原理为人所知(维特比搜索),并且一个玩具的解码器原型只需要200行左右的代码就可以工作,但是一个真正工业级的解码器确是目前语音识别中真正最具挑战性的问题。
语音识别解码是一个真正的计算密集型和内存密集型的计算流程。解码器的第一个挑战是,声学模型(深度神经网)打分是一个典型的计算密集型过程(矩阵乘法),为了保证这一部分的效率,iDST的同学做了各种算法优化(量化解码,模型压缩等)和指令优化(针对各种硬件平台),降低了这一部分的计算量。
解码器中面临的一个更大的挑战是如何在语音识别中使用超大规模语言模型,因为巨大的模型可能使得解码过程中内存成为瓶颈,而且解码中对语言模型的反复查找会使计算成为瓶颈。 为了达到在解码过程中使用超大语言模型的目的, iDST的同学对语言模型的存贮表示以及和解码器的核心算法以及跟语言模型的交互方式进行了深度的定制。既节省了解码时的语言模型内存耗费,又充分利用了解码过程中的信息,减少了语言模型部分的计算量,使得在线使用成为可能。实际上,即使在整个世界上范围内,能够使用这种规模的语言模型用于单遍解码的语音识别系统也屈指可数。
对应这部分,iDST的同学会写相应的文章来阐述这一部分的奥秘。
- 模型的快速迭代和训练
另外一个取得这么优秀性能的原因是模型的快速迭代和训练。语音识别中的声学模型和语言模型技术需要基于海量数据进行学习的,那么如何完成在海量数据上的快速迭代就变得尤为重要。在上面提到的大规模语言模型训练工具之外, iDST还基于阿里云的基础架构,构建了GPU集群的多机并行深度学习系统用来完成声学模型的训练(详情请参考GPU训练的文章 。这样系统的快速迭代就变成了可能。
- 高性能计算支持
正如上面所述,语音识别本身是个计算密集型系统。为了保证演示当天达到最佳的效果,在年会当天,使用的HPC是阿里云带GPU加速的新一代高性能计算平台,单节点计算性能高达16TFLOPS,加上算法优化,保证了语音识别的实时响应速度。