MaxCompute Studio已经发布好久,一直没能好好体验,近期MaxCompute Studio 陆续推出很多好用的功能,今天开始给大家分享使用心得。
用过大数据开发套件的同学,对于本地数据上传下载,都会遇到这样的问题:
- ‘导入本地数据’功能,限制本地数据文件大小最大为10MB;
- 查询结果导出本地时,由于select语句返回结果最大为10000行的限制,最多只能导出1W数据;
- 数据导出本地文件的功能只有‘查询结果导出本地’。
要解决以上问题,通常都是需要自己安装console客户端,通过tunnel命令进行导入导出。
现在来分享使用MaxCompute Studio工具界面,可以更轻松完成tunnel命令能完成的本地数据导入导出工作。
MaxCompute Studio工具安装请参考文档安装 IntelliJ IDEA、安装MaxCompute Studio.
本地数据导入
前提条件:表、分区已经存在,操作人有权限对表进行数据写入。
进入MaxCompute Studio的Project Explorer窗口,展开Data Preview,鼠标对需要导入数据的表右键,选择 Import data into table
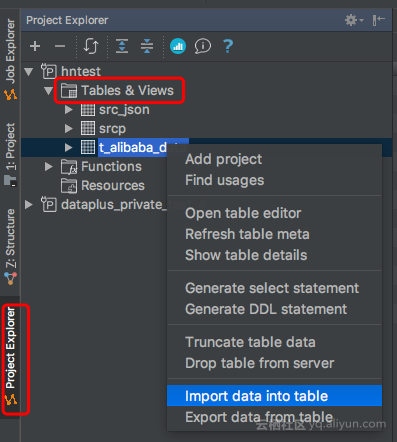
弹出的框里选择上传的本地数据文件路径、分区(非分区表无需填)、分隔符、行数限制、大小限制等:
注意:大小限制(Size Limit)不限于10MB。
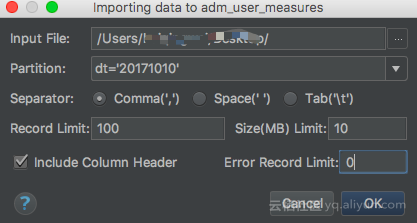
点击OK后可以看右下角进度条,最终成功与否会在Event Log里可查看相关日志。导入成功日志中会给出写入成功的行数和写入失败的行数。如:
上午10:35 Success: Import to table tablename from file /Users/.../Documents/.../t_data.txt finished, success [ 220977 ], failed [ 0 ].
数据导出本地
前提条件:操作人有权限对表进行数据导出。
进入MaxCompute Studio的Project Explorer窗口,展开Data Preview,鼠标对需要导入数据的表右键,选择 Export data from table
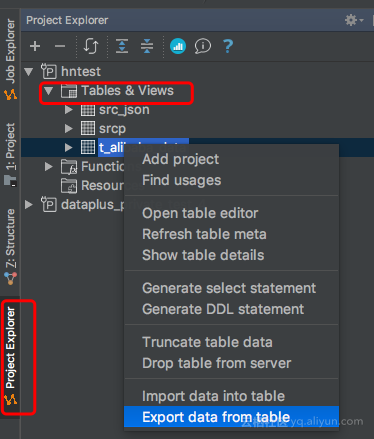
弹出框输入导出文件地址包括文件名文件类型(CSV或TXT)、选择需要下载的分区(非分区表直接下载整张表)、导出行数限制、大小限制等。
注意:行数不限于10000行,大小不限于10MB,可以下载整张非分区表或分区表的整个分区。
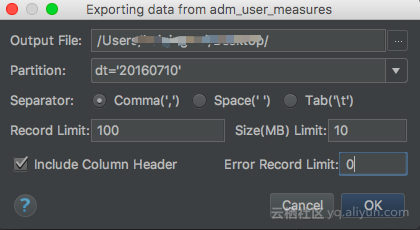
点击OK后可以看右下角进度条,最终成功与否会在Event Log里可查看相关日志。导出成功日志中会给出导出成功的行数和导出失败的行数。如:
上午10:47 Success: Export from table tablename to file /Users/..../Desktop/... finished, success [ 220977 ], failed [ 0 ].
结束语:MaxCompute Studio中上述的本地数据导入导出功能实际上就是采用 MaxCompute Tunnel 服务,功能与Tunnel命令一样。