你在前一章闭包/对象的兔子洞中玩儿的开心吗?欢迎回来!
如果你能做很赞的事情,那就反复做。
我们在本书先前的部分已经看到了对一些工具的简要引用,现在我们要非常仔细地看看它们,它们是 map(..)、filter(..)、和 reduce(..)。在 JavaScript 中,这些工具经常作为数组(也就是“列表”)原型上的方法使用,所以我们很自然地称它们为数组或列表操作。
在我们讨论具体的数组方法之前,我们要在概念上检视一下这些操作是用来做什么的。在这一章中有两件同等重要的事情:理解列表操作 为什么 重要以及理解列表操作是 如何 工作的。确保你在头脑中带着这些细节来阅读这一章。
在这本书之外的世界以及这一章中,展示这些操作的最广泛、最常见方式是,描述一些在值的列表中实施的微不足道的任务(比如将一个数组中的每个数字翻倍);这是一种讲清要点的简单廉价的方式。
但是不要仅仅将这些简单的例子一带而过却忽略了深层次的意义。理解列表操作对于 FP 来说最重要的价值来源于能够将一个任务的序列 —— 一系列 看起来 不太像一个列表的语句 —— 模型化为一个操作的列表,而非分别独立地执行它们。
这不只是一个编写更简洁代码的技巧。我们追求的是从指令式转向声明式,使代码模式可以轻而易举地识别从而可读性更高。
但是这里还有 更重要的东西需要把握住。使用指令式代码,一组计算中的每一个中间结果都通过赋值存储在变量中。你的代码越依赖这样的指令式模式,验证它在逻辑上没有错误就越困难 —— 对值的意外改变,或者埋藏下侧因/副作用。
通过将列表操作链接和/或组合在一起,中间结果会被隐含地追踪,并极大程度地防止这些灾难的发生。
注意: 与前面的章节相比,为了尽可能地保持后述代码段的简洁,我们将重度应用 ES6 的 => 形式。但是,我在第二章中关于 => 的建议依然在一般性的编码中适用。
非 FP 列表处理
作为我们在本章中的讨论的序言,我要指出几个看起来与 JavaScript 数组和 FP 列表操作相关,但其实无关的操作。这些操作将不会在这里讲解,因为它们不符合一般的 FP 最佳实践:
forEach(..)some(..)every(..)
forEach(..) 是一个迭代帮助函数,但它被设计为对每一个执行的函数调用都带有副作用;你可能猜到了为什么我们的讨论不赞同它是一个 FP 列表操作。
some(..) 和 every(..) 确实鼓励使用纯函数(具体地讲,是像 filter(..) 这样的检测函数),但它们实质上像一个检索或匹配一样,不可避免地将一个列表递减为一个 true / false 的结果。这两个工具不是很适合作为我们想要对代码进行 FP 建模的模具,所以这里我们跳过它们不讲。
Map
我们将从最基本而且最基础的 FP 列表操作之一开始我们的探索:map(..)。
一个映射是从一个值到另一个值的变形。例如,如果你有一个数字 2 而你将它乘以 3,那么你就将它映射到了 6。值得注意的是,我们所说的映射变形暗示着 原地 修改或者重新赋值;而不是映射变形将一个新的值从一个地方投射到另一个地方。
换句话说:
var x = 2, y;
// 变形/投射
y = x * 3;
// 改变/重新赋值
x = x * 3;
如果我们将这个乘以 3 定义为一个函数,这个函数作为一个映射(变形)函数动作的话:
var multipleBy3 = v => v * 3;
var x = 2, y;
// 变形/投射
y = multiplyBy3( x );
我们可以很自然地将映射从一个单独值的变形扩展到一个值的集合。map(..) 操作将列表中的所有值变形并将它们投射到一个新的列表中:

要实现 map(..) 的话:
function map(mapperFn,arr) {
var newList = [];
for (let idx = 0; i < arr.length; i++) {
newList.push(
mapperFn( arr[i], idx, arr )
);
}
return newList;
}
注意: 形式参数的顺序 mapperFn, arr 一开始可能感觉是弄反了,但是在 FP 库中这种惯例非常常见,因为它使这些工具更容易(使用柯里化)组合。
mapperFn(..) 自然地将项目列表传递给映射/变形,同时还有 idx 和 arr。我们这样做是为了与内建的 map(..) 保持一致。在某些情况下这些额外的信息可能十分有用。
但是在其他情况下,你可能想使用一个仅有列表项目应当被传入的 mapperFn(..),因为额外的参数有可能会改变它的行为。在第三章中的 “皆归为一” 中介绍了 unary(..),它限制一个函数仅接收一个实际参数(不论有多少被传递)。
回忆一下第三章中将 parseInt(..) 限制为一个参数的例子,它可以安全地用于 mapperFn(..):
map( ["1","2","3"], unary( parseInt ) );
// [1,2,3]
JavaScript 在数组上提供了内建的 map(..) 工具,使得它很容易地用做一个列表操作链条上的一部分。
注意: JavaScript 原型操作(map(..)、filter(..)、和 reduce(..))都接收一个最后的可选参数,它用于函数的 this 绑定。在我们第二章的 “This 是什么” 的讨论中,从为了符合 FP 的最佳实践的角度讲,基于 this 的编码一般来说应当尽可能避免。因此,我们在这一章例子的实现中不支持这样的 this 绑定特性。
除了你可以分别对数字和字符串列表实施的各种显而易见的操作之外,还有一些其他的映射操作的例子。我们可以使用 map(..) 来把一个函数的列表变形为一个它们返回值的列表:
var one = () => 1;
var two = () => 2;
var three = () => 3;
[one,two,three].map( fn => fn() );
// [1,2,3]
或者我们可以首先将列表中的每一个函数都与另一个函数组合,然后再执行它们:
var increment = v => ++v;
var decrement = v => --v;
var square = v => v * v;
var double = v => v * 2;
[increment,decrement,square]
.map( fn => compose( fn, double ) )
.map( fn => fn( 3 ) );
// [7,5,36]
关于 map(..) 的一件有趣的事情:我们通常会臆测列表是从左到右处理的,但是 map(..) 的概念中对此没有任何要求。每一个变形对于其他的变形来说都应该是独立的。
从一般的意义上说,在一个支持并行的环境中映射甚至可以是并行化的,这对很大的列表来说可以极大地提升性能。我们没有看到 JavaScript 实际上在这样做,因为没有任何东西要求你传入一个像 mapperFn(..) 这样的纯函数,即使你 本应这样做。如果你传入一个非纯函数而且 JS 以不同的顺序运行不同的调用,那么这很快就会引起灾难。
虽然在理论上每一个映射操作都是独立的,但 JS 不得不假定它们不是。这很扫兴。
同步 vs 异步
我们在这一章中要讨论的列表操作都是在一个所有值都已存在的列表上同步地操作;map(..) 在这里被认为是一种迫切的操作。但另一种考虑映射函数的方法是将它作为一个事件处理器,为在列表中出现的每一个新的值而被调用。
想象一个如下虚构的东西:
var newArr = arr.map();
arr.addEventListener( "value", multiplyBy3 );
现在,无论什么时候一个值被添加到 arr 种,事件处理器 multiplyBy3(..) —— 映射函数 —— 都会用这个值被调用,它变形出的值被添加到 newArr。
我们在暗示的是,数组以及我们在它们之上施加的数组操作,都是迫切的同步版本,而这些相同的操作也可以在一个经过一段时间后才收到值的 “懒惰列表” (也就是流)上建模。
映射 vs 迭代
一些人鼓吹将 map(..) 作为一个一般形式的 forEach(..) 迭代使用,让它收到的值原封不动地通过,但之后可能实施一些副作用:
[1,2,3,4,5]
.map( function mapperFn(v){
console.log( v ); // 副作用!
return v;
} )
..
这种技术看起来好像有用是因为 map(..) 返回这个数组,于是你就可以继续在它后面链接更多操作;而 forEach(..) 的返回值是 undefined。然而,我认为你应当避免以这种方式使用 map(..),因为以一种明确的非 FP 方式使用一种 FP 核心操作除了困惑不会造成其他任何东西。
你听说过用正确的工具做正确的事这句谚语,对吧?锤子对钉子,改锥对螺丝,等等。这里有点儿不同:它是 用正确的方式 使用正确的工具。
一把锤子本应在你的手中挥动;但如果你用嘴叼住它来砸钉子,那你就不会非常高效。map(..) 的本意是映射值,不是造成副作用。
一个词:函子
在这本书中我们绝大多数时候都尽可能地与人工发明的 FP 术语保持距离。我们有时候用一些官方术语,但这多数是在我们可以从中衍生出一些对普通日常对话有意义的东西的时候。
我将要非常简要地打破这种模式,而使用一个可能有点儿吓人的词:函子。我想谈一下函子的原因是因为我们现在已经知道它们是做什么的了,也因为这个词在其他的 FP 文献中被频繁使用;至少你熟悉它而不会被它吓到是有好处的。
一个函子是一个值,它有一个工具可以使一个操作函数作用于这个值。
如果这个值是复合的,也就是它由一些独立的值组成 —— 例如像数组一样!—— 那么函子会在每一个独立的值上应用操作函数。另外,函子工具会创建一个新的复合值来持有所有独立操作函数调用的结果。
这只是对我们刚刚看到的 map(..) 的一种炫酷的描述。map(..) 函数拿着与它关联的值(一个数组)和一个映射函数(操作函数),并对数组中每一个独立的值执行这个映射函数。最终,它返回一个带有所有被映射好的值的数组。
另一个例子:一个字符串函子将是一个字符串外加一个工具,这个工具对字符串中的每一个字符执行一些操作函数,返回一个带有被处理过的字符的新字符串。考虑这个高度造作的例子:
function uppercaseLetter(c) {
var code = c.charCodeAt( 0 );
// 小写字符?
if (code >= 97 && code <= 122) {
// 将它大写!
code = code - 32;
}
return String.fromCharCode( code );
}
function stringMap(mapperFn,str) {
return [...str].map( mapperFn ).join( "" );
}
stringMap( uppercaseLetter, "Hello World!" );
// HELLO WORLD!
stringMap(..) 允许一个字符串是一个函子。你可以为任意数据结构定义一个映射函数;只要这个工具符合这些规则,那么这种数据结构就是一个函子。
Filter
想象我在百货商店里拿着一个空篮子来到了水果卖场;这里有一大堆水果货架(苹果、橘子、和香蕉)。我真的很饿,所以要尽可能多地拿水果,但我非常喜欢圆形的水果(苹果和橘子)。于是我一个一个地筛选,然后带着仅装有苹果和橘子的篮子离开了。
假定我们称这种处理为 过滤。你将如何更自然地描述我的购物过程?是以一个空篮子为起点并仅仅 滤入(选择,包含)苹果和橘子,还是以整个水果货架为起点并 滤除(跳过,排除)香蕉,直到我的篮子装满水果?
如果你在一锅水中煮意大利面,然后把它倒进水槽上的笊篱(也就是过滤器)中,你是在滤入意大利面还是在滤除水?如果你将咖啡粉末放进滤纸中泡一杯咖啡,你是在自己的杯子中滤入了咖啡,还是滤除了咖啡粉末?
你对过滤的视角是不是有赖于你想要的东西是否 “保留” 在过滤器中或者通过了过滤器?
那么当你在航空公司/酒店的网站上制定一些选项来 “过滤你的结果” 呢?你是在滤入符合你标准的结果,还是在滤除所有不符合标准的东西?仔细考虑一下:这个例子与前一个比起来可能有不同的语义。
根据你的视角不同,过滤不是排除性的就是包含性的。这种概念上的冲突非常不幸。
我认为对过滤的最常见的解释 —— 在编程的世界之外 —— 是你在滤除不想要的东西。不幸的是,在编程中,我们实质上更像是将这种语义反转为滤入想要的东西。
filter(..) 列表操作用一个函数来决定原来数组中的每一个值是否应该保留在新的数组中。如果一个值应当被保留,那么这个函数需要返回 true,如果它应当被跳过则返回 false。一个为做决定而返回 true / false 的函数有一个特殊的名字:判定函数。
如果你将 true 作为一个正面的信号,那么 filter(..) 的定义就是你想要 “保留”(滤入)一个值而非 “丢弃”(滤除)一个值。
为了将 filter(..) 作为一种排除性操作使用,你不得不把思维拧过来,通过返回 false 将正面信号考虑为一种排除,并通过返回 true 被动地让一个值通过。
这种语义错位很重要的原因,是因为它会影响你如何命名那个用作 predicateFn(..) 的函数,以及它对代码可读性的意义。我们马上就会谈到这一点。
这是 filter(..) 操作在一个值的列表中的可视化表达:

要实现 filter(..):
function filter(predicateFn,arr) {
var newList = [];
for (let idx = 0; idx < arr.length; idx++) {
if (predicateFn( arr[idx], idx, arr )) {
newList.push( arr[idx] );
}
}
return newList;
}
注意,正如之前的 mapperFn(..) 一样,predicateFn(..) 不仅被传入一个值,而且还被传入了 idx 和 arr。可以根据需要使用 unary(..) 来限制它的参数。
和 map(..) 一样,filter(..) 作为一种 JS 数组上的内建工具被提供。
让我们考虑一个这样的判定函数:
var whatToCallIt = v => v % 2 == 1;
这个函数使用 v % 2 == 1 来返回 true 或 false。这里的效果是一个奇数将会返回 true,而一个偶数将会返回 false。那么,我们应该管这个函数叫什么?一个自然的名字可能是:
var isOdd = v => v % 2 == 1;
考虑一下在你代码中的某处你将如何使用 isOdd(..) 进行简单的值校验:
var midIdx;
if (isOdd( list.length )) {
midIdx = (list.length + 1) / 2;
}
else {
midIdx = list.length / 2;
}
有些道理,对吧?让我们再考虑一下将它与数组内建的 filter(..) 一起使用来过滤一组值:
[1,2,3,4,5].filter( isOdd );
// [1,3,5]
如果要你描述一下 [1,3,5] 这个结果,你会说 “我滤除了偶数” 还是 “我滤入了奇数”?我觉得前者是描述它的更自然的方式。但是代码读起来却相反。代码读起来几乎就是,我们 “过滤(入)了每一个是奇数的数字”。
我个人觉得这种语义令人糊涂。对于有经验的开发者来说无疑有许多先例可循。但是如果你刚刚起步,这种逻辑表达式看起来有点儿像不用双否定就不会说话 —— 也就是,用双否定说话。
我们可以通过把函数 isOdd(..) 重命名为 isEven(..) 让事情容易一些:
var isEven = v => v % 2 == 1;
[1,2,3,4,5].filter( isEven );
// [1,3,5]
呀!但这个函数用这个名字根本讲不通,因为当数字为偶数时它返回 false:
isEven( 2 ); // false
讨厌。
回忆一下第三章中的 “无点”,我们定义了一个对判定函数取反的 not(..) 操作符。考虑:
var isEven = not( isOdd );
isEven( 2 ); // true
但是我们将 这个 isEven(..) 按照它当前定义的方式与 filter(..) 一起使用,因为逻辑将是相反的;我们将会得到偶数,不是奇数。我们需要这样做:
[1,2,3,4,5].filter( not( isEven ) );
// [1,3,5]
这违背了我们的初衷,所以不要这样做。我们只是在绕圈子。
滤除与滤入
为了扫清这一切困惑,让我们定义一个通过在内部对判定检查取反来真正 滤除 一些值的 filterOut(..)。同时我们将 filterIn(..) 作为既存的 filter(..) 的别名:
var filterIn = filter;
function filterOut(predicateFn,arr) {
return filterIn( not( predicateFn ), arr );
}
现在我们可以在代码的任何地方使用最合理的那一种过滤了:
isOdd( 3 ); // true
isEven( 2 ); // true
filterIn( isOdd, [1,2,3,4,5] ); // [1,3,5]
filterOut( isEven, [1,2,3,4,5] ); // [1,3,5]
与仅使用 filter(..) 并将语义上的混淆和困惑留给读者相比,我觉得使用 filterIn(..) 和 filterOut(..)(在 Ramda 中称为 reject(..))将会使你代码的可读性好得多。
Reduce
map(..) 和 filter(..) 产生一个新的列表,但这第三种操作(reduce(..))经常将一个列表的值结合(也就是“递减”)为一个单独的有限(非列表)值,比如数字或字符串。但是在本章稍后,我们将会看到如何以更高级的方式使用 reduce(..)。reduce(..) 是最重要的 FP 工具之一;它就像瑞士军刀一样多才多艺。
组合/递减被抽象地定义为将两个值变成一个值。一些 FP 语境中将之称为 “折叠(folding)”,就好像你把两个值折叠成为一个值一样。我觉得这种视觉化很有助于理解。
正如映射与过滤那样,结合的行为完全由你来决定,而且这一般要看列表中值的种类而定。例如,数字通常将通过算数方式来结合,字符串通过连接,而函数通过组合。
有时递减将会指定一个 initialValue 并用它与列表中的第一个值结合的结果做为起点,穿过列表中剩余的其他每一个值。看起来就像这样:
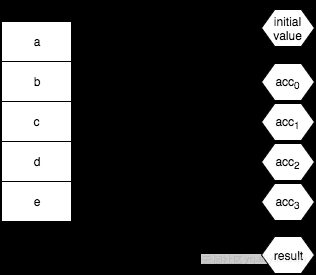
另一种方式是你可以忽略 initialValue,这时列表中的第一个值将作为 initialValue,而结合将始于它与列表中的第二个值,就像这样:
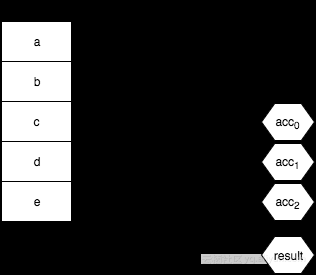
注意: 在 JavaScript 中,递减至少需要一个值(要么在数组中,要么作为 initialValue 指定),否则就会抛出一个错误。如果用来递减的列表在某些环境下可能为空,那么就要小心不要忽略 initialValue。
你传递给 reduce(..) 来执行递减的函数通常称为一个递减函数(reducer)。递减函数的签名与我们早先看到的映射和判定函数不同。递减函数主要接收当前的递减结果以及下一个用于与之递减的值。在递减每一步中的结果经常被称为聚集器(accumulator)。
例如,考虑将 3 作为 initialValue 对数字 5、10、和 15 进行乘法递减时的步骤:
3*5=1515*10=150150*15=2250
在 JavaScript 中使用内建在数组上的 reduce(..) 来表达的话:
[5,10,15].reduce( (product,v) => product * v, 3 );
// 2250
一个独立的 reduce(..) 的实现可能像是这样:
function reduce(reducerFn,initialValue,arr) {
var acc, startIdx;
if (arguments.length == 3) {
acc = initialValue;
startIdx = 0;
}
else if (arr.length > 0) {
acc = arr[0];
startIdx = 1;
}
else {
throw new Error( "Must provide at least one value." );
}
for (let idx = startIdx; idx < arr.length; idx++) {
acc = reducerFn( acc, arr[idx], idx, arr );
}
return acc;
}
和 map(..) 与 filter(..) 一样,递减函数也会被传入不太常用的 idx 和 arr 参数以备递减中的不时之需。我不常用这些东西,但我猜它们可以随时取用是一件不错的事情。
回忆一下第四章,我们讨论了 compose(..) 工具而且展示了一种使用 reduce(..) 的实现:
function compose(...fns) {
return function composed(result){
return fns.reverse().reduce( function reducer(result,fn){
return fn( result );
}, result );
};
}
为了以一种不同的方式展示基于 reduce(..) 的组合,考虑一个从左到右(像 pipe(..) 那样)组合函数的递减函数,将它用于一个数组中:
var pipeReducer = (composedFn,fn) => pipe( composedFn, fn );
var fn =
[3,17,6,4]
.map( v => n => v * n )
.reduce( pipeReducer );
fn( 9 ); // 11016 (9 3 17 6 4)
fn( 10 ); // 12240 (10 3 17 6 4)
不幸的是 pipeReducer(..) 不是无点的(参见第三章的 “无点”),但我们不能简单地将 pipe(..) 作为递减函数本身传递,因为它是参数可变的;reduce(..) 传递给递减函数的额外参数(idx 和 arr)可能会引起问题。
早先我们谈到过使用 unary(..) 来将 mapperFn(..) 和 predicateFn(..) 限定为一个参数。对于一个 reducerFn(..) 来说,要是有一个与之相似但限定为两个参数的 binary(..) 可能会很方便:
var binary =
fn =>
(arg1,arg2) =>
fn( arg1, arg2 );
使用 binary(..),我们的前一个例子会干净一些:
var pipeReducer = binary( pipe );
var fn =
[3,17,6,4]
.map( v => n => v * n )
.reduce( pipeReducer );
fn( 9 ); // 11016 (9 3 17 6 4)
fn( 10 ); // 12240 (10 3 17 6 4)
对 map(..) 和 filter(..) 来说遍历数组的顺序实际上不重要,与此不同的是,reduce(..) 绝对是按照从左到右的顺序处理。如果你想要从右到左地递减,JavaScript 提供了一个 reduceRight(..),它除了顺序以外其他一切行为都与 reduce(..) 相同:
var hyphenate = (str,char) => str + "-" + char;
["a","b","c"].reduce( hyphenate );
// "a-b-c"
["a","b","c"].reduceRight( hyphenate );
// "c-b-a"
reduce(..) 从左到右地工作,因此在组合函数时很自然地像 pipe(..) 一样动作,而 reduceRight(..) 从右到左的顺序对于 compose(..) 一样的操作来说更自然。那么,让我们使用 reduceRight(..) 来重温 compose(..):
function compose(...fns) {
return function composed(result){
return fns.reduceRight( function reducer(result,fn){
return fn( result );
}, result );
};
}
现在我们不需要 fns.reverse() 了;我们只要从另一个方向递减即可!
Map 作为 Reduce
map(..) 操作天生就是迭代性的,所以它也可以表达为一种递减(reduce(..))。这其中的技巧是要理解 reduce(..) 的 initialValue 本身可以是一个(空)数组,这样递减的结果就可以是另一个列表!
var double = v => v * 2;
[1,2,3,4,5].map( double );
// [2,4,6,8,10]
[1,2,3,4,5].reduce(
(list,v) => (
list.push( double( v ) ),
list
), []
);
// [2,4,6,8,10]
注意: 我们在欺骗这个递减函数,并通过 list.push(..) 改变被传入的列表而引入了副作用。一般来说,这不是个好主意,但是因为我们知道 [] 是被新建并传入的,所以这没那么危险。你可以更正式一些 —— 性能也差一些!—— 将值 concat(..) 在一个新列表的末尾。我们将在附录A中再次回到这个问题上。
使用 reduce(..) 实现 map(..) 在表面上看来不是显而易见的,它甚至不是一种改进。然而,对于我们将在附录A中讲解的 “转导(Transducing)” 这样的更高级的技术来说,这种能力将是一种识别它的关键方法。
Filter 作为 Reduce
就像 map(..) 可以用 reduce(..) 完成一样,filter(..) 也能:
var isOdd = v => v % 2 == 1;
[1,2,3,4,5].filter( isOdd );
// [1,3,5]
[1,2,3,4,5].reduce(
(list,v) => (
isOdd( v ) ? list.push( v ) : undefined,
list
), []
);
// [1,3,5]
注意: 这里使用了更不纯粹的递减函数。我们本可以用 list.concat(..) 并返回一个新列表来取代 list.push(..)。我们将在附录A中回到这个问题。
高级列表操作
现在我们对基础的列表操作 map(..)、filter(..)、和 reduce(..) 有些熟悉了,让我们看几个你可能会在各种情景下觉得很有用的更加精巧的操作。它们通常都是你可以在各种 FP 库中找到的工具。
Unique
基于 indexOf(..) 搜索(它使用 === 严格等价比较),过滤一个列表使之仅包含唯一的值:
var unique =
arr =>
arr.filter(
(v,idx) =>
arr.indexOf( v ) == idx
);
这种技术的工作方式是,仅将第一次出现在 arr 中的项目加入到新的列表中;当从左到右运行时,这仅在项目的 idx 位置与 indexOf(..) 找到的位置相同时成立。
另一种实现 unique(..) 的方式是遍历 arr,如果一个项目没有在新的列表中(初始为空)找到就将它加入这个新的列表。我们为这样的处理使用 reduce(..):
var unique =
arr =>
arr.reduce(
(list,v) =>
list.indexOf( v ) == -1 ?
( list.push( v ), list ) : list
, [] );
注意: 使用诸如循环之类的更具指令式的方式,有许多种其他不同的方法可以实现这个算法,而且其中很多在性能方面可能看起来 “更高效”。然而,上面展示的这两种方式有一个优势是它们都使用了既存的列表操作,这使它们与其他列表操作链接/组合起来更容易。我们将会在本章稍后更多地谈到这些问题。
unique(..) 可以出色地产生一个没有重复的新列表:
unique( [1,4,7,1,3,1,7,9,2,6,4,0,5,3] );
// [1, 4, 7, 3, 9, 2, 6, 0, 5]
Flatten
时不时地,你会得到(或者从一些其他操作中得到)一个这样的数组:它不只是一个值的扁平的列表,而是一个嵌套的数组,例如:
[ [1, 2, 3], 4, 5, [6, [7, 8]] ]
要是你想要将它变形为这样呢?
[ 1, 2, 3, 4, 5, 6, 7, 8 ]
我们在寻求的操作通常称为 flatten(..),它可以使用我们的瑞士军刀 reduce(..) 像这样实现:
var flatten =
arr =>
arr.reduce(
(list,v) =>
list.concat( Array.isArray( v ) ? flatten( v ) : v )
, [] );
注意: 这种实现依赖于使用递归处理嵌套的列表。后面的章节中有关于递归的更多内容。
要对一个(嵌套多层的)数组的数组使用 flatten(..):
flatten( [[0,1],2,3,[4,[5,6,7],[8,[9,[10,[11,12],13]]]]] );
// [0,1,2,3,4,5,6,7,8,9,10,11,12,13]
你可能想要将递归平整限制在一个特定的深度上。我们可以通过为这种实现添加一个可选的 depth 限制参数来处理:
var flatten =
(arr,depth = Infinity) =>
arr.reduce(
(list,v) =>
list.concat(
depth > 0 ?
(depth > 1 && Array.isArray( v ) ?
flatten( v, depth - 1 ) :
v
) :
[v]
)
, [] );
这是不同平整深度的结果:
flatten( [[0,1],2,3,[4,[5,6,7],[8,[9,[10,[11,12],13]]]]], 0 );
// [[0,1],2,3,[4,[5,6,7],[8,[9,[10,[11,12],13]]]]]
flatten( [[0,1],2,3,[4,[5,6,7],[8,[9,[10,[11,12],13]]]]], 1 );
// [0,1,2,3,4,[5,6,7],[8,[9,[10,[11,12],13]]]]
flatten( [[0,1],2,3,[4,[5,6,7],[8,[9,[10,[11,12],13]]]]], 2 );
// [0,1,2,3,4,5,6,7,8,[9,[10,[11,12],13]]]
flatten( [[0,1],2,3,[4,[5,6,7],[8,[9,[10,[11,12],13]]]]], 3 );
// [0,1,2,3,4,5,6,7,8,9,[10,[11,12],13]]
flatten( [[0,1],2,3,[4,[5,6,7],[8,[9,[10,[11,12],13]]]]], 4 );
// [0,1,2,3,4,5,6,7,8,9,10,[11,12],13]
flatten( [[0,1],2,3,[4,[5,6,7],[8,[9,[10,[11,12],13]]]]], 5 );
// [0,1,2,3,4,5,6,7,8,9,10,11,12,13]
Map,之后 Flatten
flatten(..) 行为的最常见用法之一是在你映射一个列表时,每一个从原数组变形而来的元素本身就是一个值的列表。例如:
var firstNames = [
{ name: "Jonathan", variations: [ "John", "Jon", "Jonny" ] },
{ name: "Stephanie", variations: [ "Steph", "Stephy" ] },
{ name: "Frederick", variations: [ "Fred", "Freddy" ] }
];
firstNames
.map( entry => [entry.name].concat( entry.variations ) );
// [ ["Jonathan","John","Jon","Jonny"], ["Stephanie","Steph","Stephy"],
// ["Frederick","Fred","Freddy"] ]
返回值是一个数组的数组,这使用起来可能很尴尬。如果我们要的是一个所有名字的一维数组,那么就可以 flatten(..) 这个结果:
flatten(
firstNames
.map( entry => [entry.name].concat( entry.variations ) )
);
// ["Jonathan","John","Jon","Jonny","Stephanie","Steph","Stephy","Frederick",
// "Fred","Freddy"]
除了稍稍繁冗之外,将 map(..) 和 flatten(..) 作为两个步骤分开做的缺点主要关乎性能;这个方式将列表处理了两次。
FP 库中经常定义一个“映射之后平整”组合的 flatMap(..)(也常被称为 chain(..))。为了一致性和易于(通过柯里化)组合,这些 flatMap(..) / chain(..) 工具通常都与我们以前看到的 map(..)、filter(..)、和 reduce(..) 独立工具的 mapperFn, arr 参数顺序相吻合。
flatMap( entry => [entry.name].concat( entry.variations ), firstNames );
// ["Jonathan","John","Jon","Jonny","Stephanie","Steph","Stephy","Frederick",
// "Fred","Freddy"]
将两个步骤分开做的 flatMap(..) 的幼稚的实现是:
var flatMap =
(mapperFn,arr) =>
flatten( arr.map( mapperFn ), 1 );
注意: 我们将 1 用于平整深度是因为 flatMap(..) 的常见定义是仅发生在第一层的浅平整。
因为这种方式依然将列表处理两次而导致差劲的性能,所以我们可以使用 reduce(..) 手动组合这些操作:
var flatMap =
(mapperFn,arr) =>
arr.reduce(
(list,v) =>
list.concat( mapperFn( v ) )
, [] );
虽然 flatMap(..) 工具会带来一些方便与性能上的增益,但有时候你很可能需要混合一些 filter(..) 这样的操作。如果是这样,将 map(..) 与 flatten(..) 分开做可能还是更合适的。
Zip
至此,我们检视过的列表操作都是在一个列表上进行操作的。但是有些情况需要处理多个列表。一个广为人知的操作是从两个输入列表中交替选择值放入子列表中,称为 zip(..):
zip( [1,3,5,7,9], [2,4,6,8,10] );
// [ [1,2], [3,4], [5,6], [7,8], [9,10] ]
值 1 和 2 被选入子列表 [1,2],然后 3 和 4 被选入 [3,4],等等。zip(..) 的定义要求从两个列表中各取一个值。如果这两个列表长度不同,那么值的选择将会进行到较短的那个列表耗尽为止,在另一个列表中额外的值将会被忽略。
一种 zip(..) 的实现:
function zip(arr1,arr2) {
var zipped = [];
arr1 = arr1.slice();
arr2 = arr2.slice();
while (arr1.length > 0 && arr2.length > 0) {
zipped.push( [ arr1.shift(), arr2.shift() ] );
}
return zipped;
}
调用 arr1.slice() 和 arr2.slice() 通过不在收到的数组引用上造成副作用来保证 zip(..) 是纯粹的。
注意: 在这种实现中毫无疑问地发生了一些非 FP 的事情。这里有一个指令式的 while 循环而且使用 shift() 和 push(..) 改变了列表。在本书早先的部分中,我论证过在纯函数内部(通常是为了性能)使用非纯粹的行为是合理的,只要其造成的效果是完全自包含的就行。
Merge
通过将两个列表中的值穿插来融合它们,看起来就像:
mergeLists( [1,3,5,7,9], [2,4,6,8,10] );
// [1,2,3,4,5,6,7,8,9,10]
可能不太明显,但是这个结果看起来很类似于我们将 flatten(..) 和 zip(..) 组合得到的东西:
zip( [1,3,5,7,9], [2,4,6,8,10] );
// [ [1,2], [3,4], [5,6], [7,8], [9,10] ]
flatten( [ [1,2], [3,4], [5,6], [7,8], [9,10] ] );
// [1,2,3,4,5,6,7,8,9,10]
// 组合后:
flatten( zip( [1,3,5,7,9], [2,4,6,8,10] ) );
// [1,2,3,4,5,6,7,8,9,10]
然而,回忆一下, zip(..) 对值的选择仅截止到较短的列表耗尽为止,而且忽略剩下的值;而融合两个列表时保留那些额外的值将是最自然的。另外,flatten(..) 会在嵌套的列表中递归地执行,但你可能希望列表融合仅在浅层工作,保留嵌套的列表。
那么,让我们定义一个如我们所愿的 mergeLists(..):
function mergeLists(arr1,arr2) {
var merged = [];
arr1 = arr1.slice();
arr2 = arr2.slice();
while (arr1.length > 0 || arr2.length > 0) {
if (arr1.length > 0) {
merged.push( arr1.shift() );
}
if (arr2.length > 0) {
merged.push( arr2.shift() );
}
}
return merged;
}
注意: 各种 FP 库不会定义 mergeLists(..),取而代之的是定义了融合两个对象的属性的 merge(..);这样的 merge(..) 的结果将与我们的 mergeLists(..) 的结果不同。
此外,还有许多其他选择可以将列表的融合实现为一个递减函数:
// 由 @rwaldron 编写
var mergeReducer =
(merged,v,idx) =>
(merged.splice( idx * 2, 0, v ), merged);
// 由 @WebReflection 编写
var mergeReducer =
(merged,v,idx) =>
merged
.slice( 0, idx * 2 )
.concat( v, merged.slice( idx * 2 ) );
使用 mergeReducer(..):
[1,3,5,7,9]
.reduce( mergeReducer, [2,4,6,8,10] );
// [1,2,3,4,5,6,7,8,9,10]
提示: 我们将在本章稍后使用这个 mergeReducer(..) 技巧。
方法 vs. 独立函数
在 JavaScript 中一个令 FP 程序员们沮丧的根源是,当一些工具作为独立函数被提供 —— 考虑一下我们在前一章中衍生出来的各种工具 —— 而另一些是数组原型的方法时 —— 就像我们在本章中看到的 —— 如何为使用这些工具来统一他们的策略。
当你考虑组合多个操作时,这个问题使人头疼的地方就变得更加明显:
[1,2,3,4,5]
.filter( isOdd )
.map( double )
.reduce( sum, 0 ); // 18
// vs.
reduce(
map(
filter( [1,2,3,4,5], isOdd ),
double
),
sum,
0
); // 18
这两种 API 风格都完成相同的任务,但它们在人体工程学上十分的不同。相较于前者许多 FP 程序员偏好后者,但前者毫无疑问地在 JavaScript 中更常见。后者一个特别令人厌恶的东西就是调用的嵌套。方法链风格招人喜欢的地方 —— 常被称为流利的 API 风格,就像在 jQuery 和其他工具中那样 —— 在于其紧凑/简洁,以及它读起来是声明式的从上到下顺序。
对于独立函数风格的手动组合来说,它的视觉顺序既不是从左到右(从上到下)也不是从右到左(从下到上);而是由内而外,这损害了可读性。
自动组合将两种风格的阅读顺序规范化为从右到左(从下到上)。那么为了探索不同风格可能造成的影响,让我们专门讲解一下组合;这看起来应当很直接,但是实际上在两种情况下都有些尴尬。
组合方法链
数组方法接收隐含的 this 参数,所以尽管它们没有出现,这些方法也不能被视为一元的;这使得组合更加尴尬。为了应付它,首先我们需要一个 this 敏感版本的 partial(..):
var partialThis =
(fn,...presetArgs) =>
// 有意地制造一个允许 `this` 绑定的 `function`
function partiallyApplied(...laterArgs){
return fn.apply( this, [...presetArgs, ...laterArgs] );
};
我们还需要另一个版本的 compose(..),它在这个链条的上下文环境中调用每一个被部分应用的方法 —— 从上一个步骤中(通过隐含的 this)被 “传递” 过来的输入值:
var composeChainedMethods =
(...fns) =>
result =>
fns.reduceRight(
(result,fn) =>
fn.call( result )
, result
);
一起使用这两个 this 敏感的工具:
composeChainedMethods(
partialThis( Array.prototype.reduce, sum, 0 ),
partialThis( Array.prototype.map, double ),
partialThis( Array.prototype.filter, isOdd )
)
( [1,2,3,4,5] ); // 18
注意: 三个 Array.prototype.XXX 风格的引用抓住了内建的 Array.prototype.* 方法的引用,这样我们就可以对自己的数组复用它们了。
组合独立函数工具
这些工具的独立 compose(..) 风格组合不需要所有这些扭曲 this 的操作,这是它最为人称道的地方。例如,我们可以这样定义独立函数:
var filter = (arr,predicateFn) => arr.filter( predicateFn );
var map = (arr,mapperFn) => arr.map( mapperFn );
var reduce = (arr,reducerFn,initialValue) =>
arr.reduce( reducerFn, initialValue );
但是这种特别的独立风格有它自己的尴尬之处;层层传递的数组上下文是第一个参数而非最后一个,于是我们不得不使用右侧局部应用来组合它们:
compose(
partialRight( reduce, sum, 0 )
partialRight( map, double )
partialRight( filter, isOdd )
)
( [1,2,3,4,5] ); // 18
这就是为什么 FP 库通常将 filter(..)、map(..)、和 reduce(..) 定义为最后接收数组而不是最先接收。它们还经常自动地柯里化这些工具:
var filter = curry(
(predicateFn,arr) =>
arr.filter( predicateFn )
);
var map = curry(
(mapperFn,arr) =>
arr.map( mapperFn )
);
var reduce = curry(
(reducerFn,initialValue,arr) =>
arr.reduce( reducerFn, initialValue );
使用这样定义的工具,组合的流程变得好了一些:
compose(
reduce( sum )( 0 ),
map( double ),
filter( isOdd )
)
( [1,2,3,4,5] ); // 18
这种方式的清晰性在某种程度上就是为什么 FP 程序员喜欢独立的工具风格而不是实例方法。但你的感觉可能会不同。
将方法适配为独立函数
在前面 filter(..) / map(..) / reduce(..) 的定义中,你可能发现了这三者的共同模式:它们都被分发到相应的原生数组方法上。那么,我们能否使用一个工具来生成这些独立适配函数呢?是的!让我们为此制造一个称为 unboundMethod(..) 的工具:
var unboundMethod =
(methodName,argCount = 2) =>
curry(
(...args) => {
var obj = args.pop();
return obj[methodName]( ...args );
},
argCount
);
要使用这个工具:
var filter = unboundMethod( "filter", 2 );
var map = unboundMethod( "map", 2 );
var reduce = unboundMethod( "reduce", 3 );
compose(
reduce( sum )( 0 ),
map( double ),
filter( isOdd )
)
( [1,2,3,4,5] ); // 18
注意: unboundMethod(..) 在 Ramda 中称为 invoker(..)。
将独立函数适配为方法
如果你喜欢只使用数组方法(流利的链式风格),你有两个选择。你可以:
- 使用额外的方法扩展内建的
Array.prototype。 - 适配一个用于递减函数的独立工具,并将它传入
reduce(..)实例方法。
不要选择(1)。 扩展 Array.prototype 这样的原生类型从来都不是一个好主意 —— 除非你定义一个 Array 的子类,但这超出了我们在此的讨论范围。为了不鼓励不好的实践,我们不会在这种方式上再前进了。
让我们 集中于(2)。为了展示其中的要点,我们将转换之前递归的 flatten(..) 独立工具:
var flatten =
arr =>
arr.reduce(
(list,v) =>
list.concat( Array.isArray( v ) ? flatten( v ) : v )
, [] );
让我们将内部的 reducer(..) 函数抽离为一个独立工具(并将它适配为可以脱离外部 flatten(..) 工作):
// 有意地定义一个允许通过名称进行递归的函数
function flattenReducer(list,v) {
return list.concat(
Array.isArray( v ) ? v.reduce( flattenReducer, [] ) : v
);
}
现在,我们可以在一个数组方法链中通过 reduce(..) 来使用这个工具了:
[ [1, 2, 3], 4, 5, [6, [7, 8]] ]
.reduce( flattenReducer, [] )
// ..
寻找列表
目前为止,绝大多数例子都很琐碎,它们基于简单的数字或字符串列表。现在让我们谈谈列表操作可以闪光的地方:对一系列指令式的语句进行声明式的建模。
考虑这个基本的例子:
var getSessionId = partial( prop, "sessId" );
var getUserId = partial( prop, "uId" );
var session, sessionId, user, userId, orders;
session = getCurrentSession();
if (session != null) sessionId = getSessionId( sessionId );
if (sessionId != null) user = lookupUser( sessionId );
if (user != null) userId = getUserId( user );
if (userId != null) orders = lookupOrders( userId );
if (orders != null) processOrders( orders );
首先,我们观察到那五个变量声明和守护着函数调用的一系列 if 条件实质上是这六个调用的一个大组合:getCurrentSession()、getSessionId(..)、lookupUser(..)、getUserId(..)、lookupOrders(..)、和 processOrders(..)。理想上,我们想要摆脱所有这些变量声明和指令式条件。
不幸的是,我们在第四章中探索过的 compose(..) / pipe(..) 工具自身不会在组合中提供一种表达 != null 条件的简便方法。让我们定义一个工具来提供帮助:
var guard =
fn =>
arg =>
arg != null ? fn( arg ) : arg;
这个 guard(..) 工具让我们映射出那五个条件守护着的函数:
[ getSessionId, lookupUser, getUserId, lookupOrders, processOrders ]
.map( guard )
这个映射的结果是准备好组合的函数的数组(实际上是 pipe,以这个列表的顺序来说)。我们可以将这个数组扩散到 pipe(..),但因为我们已经在做列表操作了,让我们使用一个 reduce(..),将 getCurrentSession() 中的 session 值作为初始值:
.reduce(
(result,nextFn) => nextFn( result )
, getCurrentSession()
)
接下来,我们观察到 getSessionId(..) 和 getUserId(..) 可以被分别表达为值 "sessId" 和 "uId" 的映射:
[ "sessId", "uId" ].map( propName => partial( prop, propName ) )
但为了使用它们,我们需要将它们穿插在其他三个函数中(lookupUser(..)、lookupOrders(..)、和 processOrders(..)),来让这五个函数的数组像上面的讨论中那样守护/组合。
为了进行穿插,我们可以将此模型化为列表融合。回想一下本章早先的 mergeReducer:
var mergeReducer =
(merged,v,idx) =>
(merged.splice( idx * 2, 0, v ), merged);
我们可以使用 reduce(..)(记得到我们的瑞士军刀吗!?)通过融合两个列表,来将 lookupUser(..) “插入” 到数组的 getSessionId(..) 和 getUserId(..) 函数之间:
.reduce( mergeReducer, [ lookupUser ] )
然后我们把 lookupOrders(..) 和 processOrders(..) 连接到运行中的函数数组的末尾:
.concat( lookupOrders, processOrders )
检查一下,生成的五个函数的列表被表达为:
[ "sessId", "uId" ].map( propName => partial( prop, propName ) )
.reduce( mergeReducer, [ lookupUser ] )
.concat( lookupOrders, processOrders )
最后,把所有东西放在一起,将函数的列表向前面讨论过的那样添加守护功能并组合:
[ "sessId", "uId" ].map( propName => partial( prop, propName ) )
.reduce( mergeReducer, [ lookupUser ] )
.concat( lookupOrders, processOrders )
.map( guard )
.reduce(
(result,nextFn) => nextFn( result )
, getCurrentSession()
);
所有的指令式变量声明和条件都不见了,取而代之的是链接在一起的干净且是声明式的列表操作。
如果对你来说这个版本比原来的版本读起来更困难,不要担心。原来的版本无疑是你可能更加熟悉的指令式形式。你向函数式程序员演变过程的一部分就是发展出能够识别 FP 模式的能力,比如像这样的列表操作。久而久之,随着你对代码可读性的感觉转换为声明式风格,这些东西将会更容易地从代码中跳出来。
在我们结束这个话题之前,让我们看一下现实:这里的例子都是严重造作的。不是所有的代码段都可以简单地模型化为列表操作。务实的要点是,要开发寻找这些可以进行优化的机会,但不要过于沉迷在代码的杂耍中;有些改进是聊胜于无的。总是退一步并问问你自己,你是 改善了还是损害了 代码的可读性。
融合(Fusion)
随着你将 FP 列表操作更多地带入到你对代码的思考中,你很可能很快就会看到像这样组合行为的链条:
..
.filter(..)
.map(..)
.reduce(..);
而且你还可能往往会得到每种操作有多个相邻实例的链条,就像:
someList
.filter(..)
.filter(..)
.map(..)
.map(..)
.map(..)
.reduce(..);
好消息是这种链式风格是声明式的,而且很容易按顺序读懂将要发生的具体步骤。它的缺点是这些操作的每一个都循环遍历整个列表,这意味着性能可能会有不必要的消耗,特别是在列表很长的时候。
用另一种独立风格,你可能会看到这样的代码:
map(
fn3,
map(
fn2,
map( fn1, someList )
)
);
这种风格中,操作由下至上地罗列,而且我们依然循环遍历列表三遍。
融合通过组合相邻的操作来减少列表被循环遍历的次数。我们在这里将集中于将相邻的 map(..) 压缩在一起,因为它是讲解起来最直接的。
想象这种场景:
var removeInvalidChars = str => str.replace( /[^\w]*/g, "" );
var upper = str => str.toUpperCase();
var elide = str =>
str.length > 10 ?
str.substr( 0, 7 ) + "..." :
str;
var words = "Mr. Jones isn't responsible for this disaster!"
.split( /\s/ );
words;
// ["Mr.","Jones","isn't","responsible","for","this","disaster!"]
words
.map( removeInvalidChars )
.map( upper )
.map( elide );
// ["MR","JONES","ISNT","RESPONS...","FOR","THIS","DISASTER"]
考虑一下通过这个变形流程的每一个值。在 words 列表中的第一个值从 "Mr." 开始,变成 "Mr",然后变成 "MR",然后原封不动地通过 elide(..)。另一个数据流是:"responsible" -> "responsible" -> "RESPONSIBLE" -> "RESPONS..."。
换言之,你可以这样考虑这些数据变形:
elide( upper( removeInvalidChars( "Mr." ) ) );
// "MR"
elide( upper( removeInvalidChars( "responsible" ) ) );
// "RESPONS..."
你抓住要点了吗?我们可以将这三个相邻的 map(..) 调用的分离步骤表达为一个变形函数的组合,因为它们都是一元函数而且每一个的返回值都适合作为下一个的输入。我们可以使用 compose(..) 将映射函数融合,然后将组合好的函数传递给一个 map(..) 调用:
words
.map(
compose( elide, upper, removeInvalidChars )
);
// ["MR","JONES","ISNT","RESPONS...","FOR","THIS","DISASTER"]
这是另一个 pipe(..) 可以作为一种更方便的组合形式的例子,由于它在顺序上的可读性:
words
.map(
pipe( removeInvalidChars, upper, elide )
);
// ["MR","JONES","ISNT","RESPONS...","FOR","THIS","DISASTER"]
要是融合两个或更多的 filter(..) 判定函数呢?它们经常被视为一元函数,看起来很适于组合。但别扭的地方是它们每一个都返回 boolean 种类的值,而这与下一个所期望的输入值不同。融合相邻的 reduce(..) 调用也是可能的,但递减函数不是一元的所以更具挑战性;我们需要更精巧的方法来抽离这种融合。我们会在附录A “转导” 中讲解这些高级技术。
列表以外
目前为止我们一直在列表(数组)数据结构的语境中讨论各种操作;这无疑是你遇到它们的最常见的场景。但在更一般的意义上,这些操作可以对各种值的集合执行。
正如我们早先说过的,数组的 map(..) 将一个单值操作适配为对它所有值的操作,任何能够提供 map(..) 的数据结构都可以做到相同的事情。类似地,它可以实现 filter(..),reduce(..),或者任何其他对于使用这种数据结构的值来说有意义的操作。
从 FP 的精神上讲,需要维护的最重要的部分是这些操作必须根据值的不可变性进行动作,这意味着它们必须返回一个新的数据结构而非改变既存的。
让我们通过一个广为人知的数据结构 —— 二叉树 —— 来展示一下。一个二叉树是一个节点(就是一个对象),它拥有指向其他节点(本身也是二叉树)的两个引用,通常称为 左 和 右 子树。树上的每一个节点都持有整个数据结构中的一个值。

为了便于展示,我们使我们的二叉树变为一个二叉检索树(BST)。但是我们将要看到的操作对任何非 BST 二叉树来说工作起来都一样。
注意: 二叉检索树是一种一般的二叉树,它对树上每一个值之间的关系有一种特殊的限制。在一个树左侧的每一个节点的值都要小于树根节点的值,而树根节点的值要小于树右侧每一个节点的值。“小于” 的概念是相对于被存储的数据的种类的;对于数字它可以是数值上的,对于字符串可以是字典顺序,等等。BST 很有用,因为使用递归的二元检索算法时,它们使在树上检索一个值变得很直接而且更高效。
为了制造一个二叉树节点对象,让我们使用这个工厂函数:
var BinaryTree =
(value,parent,left,right) => ({ value, parent, left, right });
为了方便起见,我们使每个节点都存储 left 和 right 子树以及一个指向它自己 parent 节点的引用。
现在让我们定义一个常见作物(水果,蔬菜)名称的 BST:
var banana = BinaryTree( "banana" );
var apple = banana.left = BinaryTree( "apple", banana );
var cherry = banana.right = BinaryTree( "cherry", banana );
var apricot = apple.right = BinaryTree( "apricot", apple );
var avocado = apricot.right = BinaryTree( "avocado", apricot );
var cantelope = cherry.left = BinaryTree( "cantelope", cherry );
var cucumber = cherry.right = BinaryTree( "cucumber", cherry );
var grape = cucumber.right = BinaryTree( "grape", cucumber );
在这个特别的二叉树中,banana 是根节点;这棵树可以使用在不同位置的节点建立,但依然是一个拥有相同遍历过程的 BST。
我们的树看起来像这样:
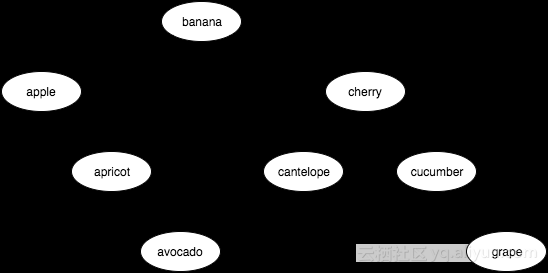
遍历一个二叉树来处理它的值有多种方法。如果它是一个 BST(我们的就是!)而且我们进行 按顺序 的遍历 —— 总是先访问左侧子树,然后是节点自身,最后是右侧子树 —— 那么我们将会按升序(排序过的顺序)访问所有值。
因为你不能像对一个数组那样简单地 console.log(..) 一个二叉树,所以我们先来定义一个主要为了进行打印而生的便利方法。forEach(..) 将会像访问一个数组那样访问一个二叉树的节点:
// 按顺序遍历
BinaryTree.forEach = function forEach(visitFn,node){
if (node) {
if (node.left) {
forEach( visitFn, node.left );
}
visitFn( node );
if (node.right) {
forEach( visitFn, node.right );
}
}
};
注意: 递归处理对于使用二叉树来说再自然不过了。我们的 forEach(..) 工具递归地调用它自己来处理左右子树。我们将在后面的章节中详细讲解递归,就是我们将在关于递归的那一章中讲解递归的那一章。
回忆一下本章开头,forEach(..) 被描述为仅对副作用有用处,而在 FP 中这通常不理想。在这个例子中,我们仅将 forEach(..) 用于 I/O 副作用,所以它作为一个帮助函数还是很合理的。
使用 forEach(..) 来打印树的值:
BinaryTree.forEach( node => console.log( node.value ), banana );
// apple apricot avocado banana cantelope cherry cucumber grape
// 访问 `cherry` 作为根的子树
BinaryTree.forEach( node => console.log( node.value ), cherry );
// cantelope cherry cucumber grape
为了使用 FP 的模式来操作我们的二叉树结构,让我们从定义一个 map(..) 开始:
BinaryTree.map = function map(mapperFn,node){
if (node) {
let newNode = mapperFn( node );
newNode.parent = node.parent;
newNode.left = node.left ?
map( mapperFn, node.left ) : undefined;
newNode.right = node.right ?
map( mapperFn, node.right ): undefined;
if (newNode.left) {
newNode.left.parent = newNode;
}
if (newNode.right) {
newNode.right.parent = newNode;
}
return newNode;
}
};
你可能会猜测我们将会仅仅 map(..) 节点的 value 属性,但一般来说我们可能实际上想要映射树节点本身。所以,整个被访问的节点被传入了 mapperFn(..) 函数,而且它期待取回一个带有变形后的值的新 BinaryTree(..)。如果你只是返回相同的节点,那么这个操作将会改变你的树而且很可能造成意外的结果!
让我们将作物的树映射为所有名称大写的列表:
var BANANA = BinaryTree.map(
node => BinaryTree( node.value.toUpperCase() ),
banana
);
BinaryTree.forEach( node => console.log( node.value ), BANANA );
// APPLE APRICOT AVOCADO BANANA CANTELOPE CHERRY CUCUMBER GRAPE
BANANA 是一个与 banana 不同的树(所有节点都不同),就像在一个数组上调用 map(..) 会返回一个新数组一样。正如其他对象/数组的数组一样,如果 node.value 本身引用了一些对象/数组,那么如果你想要更深层的不可变性的话,你还需要在映射函数中手动拷贝它。
那么 reduce(..) 呢?相同的基本处理:对树的节点进行按顺序的遍历。一种用法是将我们的树 reduce(..) 到一个它的值的数组中,这对将来适配其他常用的列表操作会很有用。或者我们可以将我们的树 reduce(..) 为一个所有作物名称的字符串连接。
我们将模仿数组 reduce(..) 的行为,这使得参数 initialValue 的传递是可选的。这个算法有些复杂,但依然是可控的:
BinaryTree.reduce = function reduce(reducerFn,initialValue,node){
if (arguments.length < 3) {
// 更换参数,因为 `initialValue` 被省略了
node = initialValue;
}
if (node) {
let result;
if (arguments.length < 3) {
if (node.left) {
result = reduce( reducerFn, node.left );
}
else {
return node.right ?
reduce( reducerFn, node, node.right ) :
node;
}
}
else {
result = node.left ?
reduce( reducerFn, initialValue, node.left ) :
initialValue;
}
result = reducerFn( result, node );
result = node.right ?
reduce( reducerFn, result, node.right ) : result;
return result;
}
return initialValue;
};
让我们使用 reduce(..) 来制造我们的购物单(一个数组):
BinaryTree.reduce(
(result,node) => result.concat( node.value ),
[],
banana
);
// ["apple","apricot","avocado","banana","cantelope"
// "cherry","cucumber","grape"]
最后,让我们来为我们的树考虑一下 filter(..)。这是目前为止最复杂的算法,因为它实质上(不是实际上)引入了对树上节点的删除,这要求处理几种极端情况。但不要被它的实现吓到。如果你乐意的话可以先跳过它,而关注与我们如何使用它。
BinaryTree.filter = function filter(predicateFn,node){
if (node) {
let newNode;
let newLeft = node.left ?
filter( predicateFn, node.left ) : undefined;
let newRight = node.right ?
filter( predicateFn, node.right ) : undefined;
if (predicateFn( node )) {
newNode = BinaryTree(
node.value,
node.parent,
newLeft,
newRight
);
if (newLeft) {
newLeft.parent = newNode;
}
if (newRight) {
newRight.parent = newNode;
}
}
else {
if (newLeft) {
if (newRight) {
newNode = BinaryTree(
undefined,
node.parent,
newLeft,
newRight
);
newLeft.parent = newRight.parent = newNode;
if (newRight.left) {
let minRightNode = newRight;
while (minRightNode.left) {
minRightNode = minRightNode.left;
}
newNode.value = minRightNode.value;
if (minRightNode.right) {
minRightNode.parent.left =
minRightNode.right;
minRightNode.right.parent =
minRightNode.parent;
}
else {
minRightNode.parent.left = undefined;
}
minRightNode.right =
minRightNode.parent = undefined;
}
else {
newNode.value = newRight.value;
newNode.right = newRight.right;
if (newRight.right) {
newRight.right.parent = newNode;
}
}
}
else {
return newLeft;
}
}
else {
return newRight;
}
}
return newNode;
}
};
这个代码段的绝大部分都用来处理当一个节点从树结构的复本中“被移除”(滤除)时,其父/子引用的移动。
为了展示 filter(..) 使用的例子,让我们将作物树收窄为仅含蔬菜:
var vegetables = [ "asparagus", "avocado", "brocolli", "carrot",
"celery", "corn", "cucumber", "lettuce", "potato", "squash",
"zucchini" ];
var whatToBuy = BinaryTree.filter(
// 过滤作物的列表,使之仅含蔬菜
node => vegetables.indexOf( node.value ) != -1,
banana
);
// 购物单
BinaryTree.reduce(
(result,node) => result.concat( node.value ),
[],
whatToBuy
);
// ["avocado","cucumber"]
你很可能在简单的数组上下文环境中使用本章中提到的大多数列表操作。但我们已经看到了,这其中的概念可以应用于任何你可能需要的数据结构和操作中。这是 FP 如何可以广泛地应用于许多不同应用程序场景的有力证明!
总结
三个常见而且强大的列表操作:
map(..):将值投射到新列表中时将其变形。filter(..):将值投射到新列表中时选择或排除它。reduce(..):将一个列表中的值结合为另一个值(通常但不总是数组)。
其他几个可能在列表处理中非常有用的高级操作:unique(..)、flatten(..)、和 merge(..)。
融合使用函数组合技术将多个相邻的 map(..) 调用合并。这很大程度上是一种性能优化,但也改善了你的列表操作的声明式性质。
列表通常在视觉上表现为数组,但也可以被一般化为任何可以表现/产生一个有序的值的序列的集合数据结构。因此,所有这些“列表操作”实际上是“数据结构操作”。