
愿不愿开放、能不能开放属于政策层面的问题;能力够不够、体制机制如何保障,组织文化是否支撑属于管理层面问题;数据好不好、数据质量控制、平台体验属于技术层面的问题。这些都是中国开放数据的“一些经典问题”。
第17届国际数字政府研究会议之“开放数据在中国”讨论会在复旦大学举办。会上,复旦大学国际关系与公共事务学院副教授、数字与移动治理实验室主任郑磊作了主题为“中国开放政府数据的现状和问题”的分享。
开放数据强调利用和再利用
郑磊提出,所谓开放数据,具体而言就是要把开放进行到数据层,而不仅仅是经过加工分析后的信息层。
他指出,“开放”包含技术性开放和法律性开放,前者是指数据可以被机读,可以被导入、下载和读取,再被充分的利用和再利用,后者是指数据能够不受限制地被明确允许商业、非商业的利用、再利用。“在技术和法律层面我们都满足这个条件,才是开放。”他说。
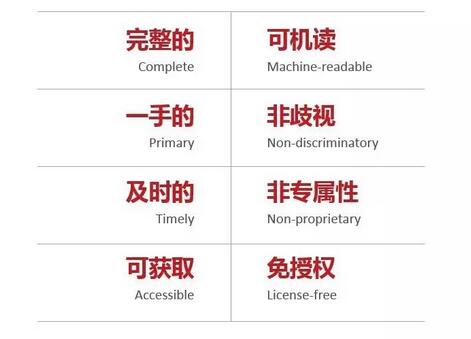
开放数据的特点
针对当下人们对开放数据与信息公开的混淆,郑磊指出,首先,开放数据需要开放到数据层,而不仅限于信息层;其次,开放数据不仅为了保证公民的知情权,还希望数据可被利用和再利用,从而创造社会和经济价值。
目前,上海、北京、无锡等地相继建立开放数据平台,它们究竟做得如何?在梳理全球约10种评估指标体系后,郑磊团队建立了一个中国开放数据的评估指标,希望借此评估这些开放数据平台。
郑磊介绍,这种从政府端进行的评估包括三部分:在基础层,包括经济、社会、组织、管理、人员能力等方面的准备;在平台层,包括平台做得如何、用户体验如何,获取数据是否容易等;在基础层、平台层之上的数据层,是真正开放出来的“干货”,包括开放数据的数量、格式、标准等。
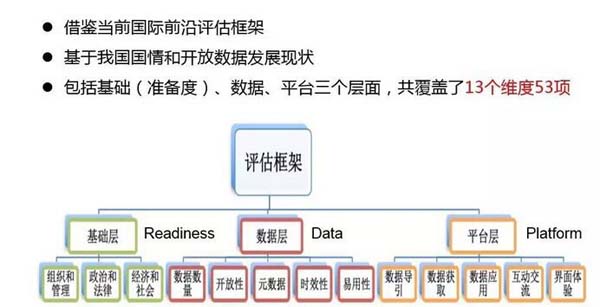
评价开放数据的三个层面
郑磊补充道,国外的评估指标会评估供给端和需求端,但现在中国供给端才刚刚起步,需求端还没有得到真正有价值的数据进行利用和产生结果,对需求端的评估也不容易开展,因此目前的这个评估框架还“不一定最完美”,但能适用于当下的情况,它会随着实践的变化而变化。
真正的动态数据的比例仅为2%
中国开放数据做得如何?郑磊团队去年选取了北京、上海、武汉、无锡、湛江、宁波海曙、佛山南海、贵州等8个地方做了评估,今年正在对更多城市的开放数据平台展开评估。
他们发现,各地的开放数总量和可机读数据量相去甚远。例如,截至今年1月,上海的开放数据总量达705个、可机读数据量达691个,均列全国第一,而很多城市虽然开放数据总量较高,但可机读数据量却只占很小比例。
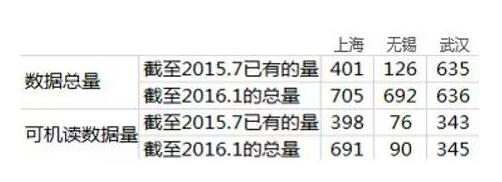
部分城市的开放数据数量
而在数据更新方面,这些平台平均只有13.25%的数据被标注为动态数据,但实际更新频率却更低。2015年,这些被标明为动态的13.25%的数据中真正按承诺实现更新的比例仅为17.2%,所以实际上真正的动态数据只有2%。
郑磊总结,目前中国开放数据的总体情况是:开放数据总量低、可机读率低、少动态数据、未严格符合开放授权。
他介绍,目前开放数据的协议并没有明确的保证,有的平台只说现阶段免费,以后是否免费并未明确。
数据是权力和利益
为什么中国开放数据现状的不理想,郑磊认为有六大原因。
第一,愿不愿意开放?数据是权力和利益,各部门可能因此而不愿意开放。还有部门则认为没有必要开放,觉得自己是专家,“数据分析自己最强大,你们能玩出什么东西,你们不懂”。
第二,能不能开放?政府在开放数据的过程中会遇到的一个难题是,数据是否涉及国家秘密、商业秘密、个人隐私?这些原则都有,但没有明确界定。
第三,能力够不够?着手开放数据工作后,能不能真正做出来?能否有体制、机制、人员能力、资金的保证?“这些部门愿不愿意把数据开放出来,用什么机制保证?包括激励机制、更新机制、人员能力建设等,都非常难”。
第四,多一事不如少一事。郑磊指出,这是风险规避性的政府组织文化问题,“能不做就不做,让别人先去做,别人做得差不多自己再拷贝,而不是积主动探索和创新”。

“多一事不如少一事”是组织文化问题
第五,数据在哪里?郑磊认为,这是个政府内部数据的碎片化问题。很多时候,人力、财力都投入了,但数据因政府内部的碎片化而分散,散落在各个部门,政府既不知道自己有什么数据,也经常找不到这个数据,也没有数据清单,这就很难开放。
第六,数据好不好?有数据了,但是政府还不能确定数据的好坏。如果数据不好,那也不敢开放,开放后产生了负面的结果,政府是否需要承担责任?这个是很现实的问题。郑磊指出,政府当初采集这些数据是为了满足内部需求,并非为了开放而采集,现在要开放出来还要花很多精力,更重要的是还不一定能保证数据质量。
郑磊总结,上述六大原因之中,愿不愿开放、能不能开放属于政策层面的问题;能力够不够、体制机制如何保障、组织文化是否支撑属于管理层面问题;数据好不好、数据质量控制、平台体验属于技术层面的问题。这些都是中国开放数据的“一些经典问题”。
本文作者:毕马威大数据挖掘
来源:51CTO