E-MapReduce集群sqoop组件可以同步数据库的数据到集群里,不同的数据库源网络配置有一些差异网络配置。最常用的场景是从rds mysql同步数据,最近也有用户询问如何同步云外专有Oracle数据库数据到hive。云外专有数据库需要集群所有节点通过公网访问,要创建VPC网络,使用VPC网络创建集群,给集群各节点绑定动态ip,检查网络链路,Oracle数据库还上传oracle jdbc jar。本文会详细介绍具体的操作步骤。
创建vpc专有网络集群
如果没创建过VPC专有网络和子网交换机,需要先创建。如果已创建可以跳过下面的创建章节。
创建专有网络
进入VPC控制台 ,选择一个地区地区,点击创建专有网络。目前E-MapReduce支持华东1(杭州)和 华北2(北京)两个地区,所以专有网络也只能创建在这两个地区,根据您专有数据库和其他应用的网络情况选择一个。
图1. 专有网络列表
图2. 配置专有网络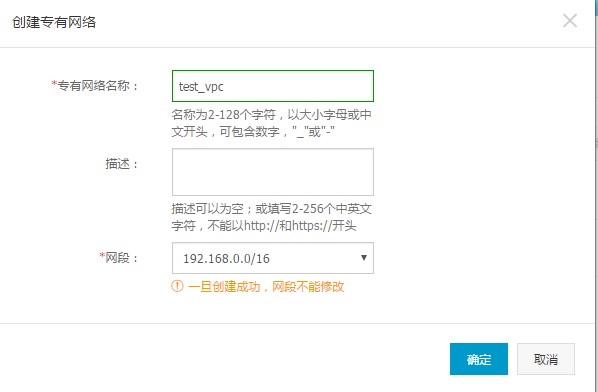
创建交换机
创建专有网络成功后,点击管理交换机,创建一个交换机。交换机有可用区属性,这个要和EMR的集群可用区保持一致。
图3. 创建专有网络成功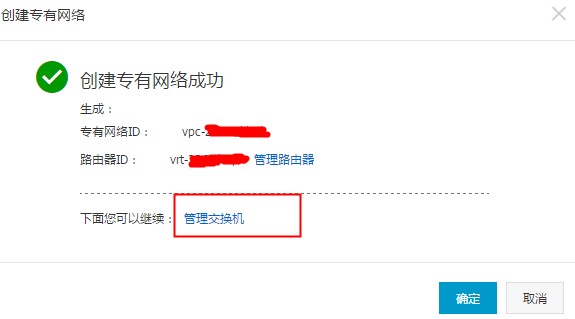
图4. 配置交换机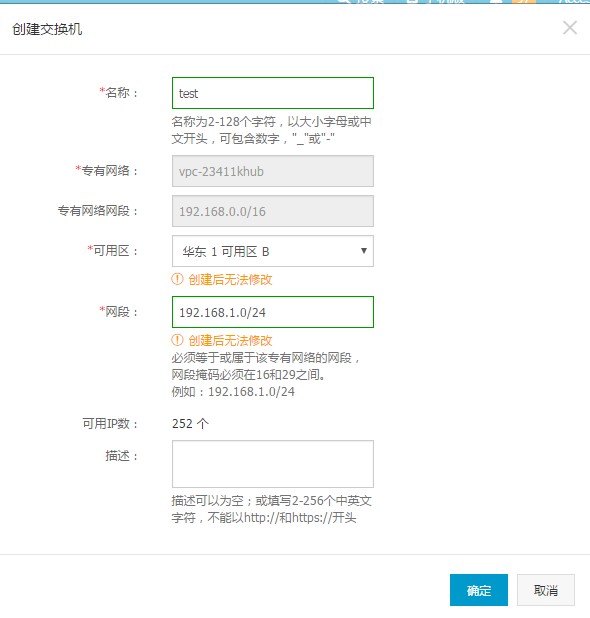
创建VPC集群
创建VPC集群可以参考用户手册创建专有网络集群
绑定动态IP
VPC网络的EMR集群,默认只有master绑定了动态ip可以访问外网,需要给其他节点也绑定动态ip以便map任务访问专有数据库。先创建动态ip,再给各个节点绑定
创建动态IP
点击 IP管理控制台,点击右上角申请弹性公网IP。
图5. 弹性公网Ip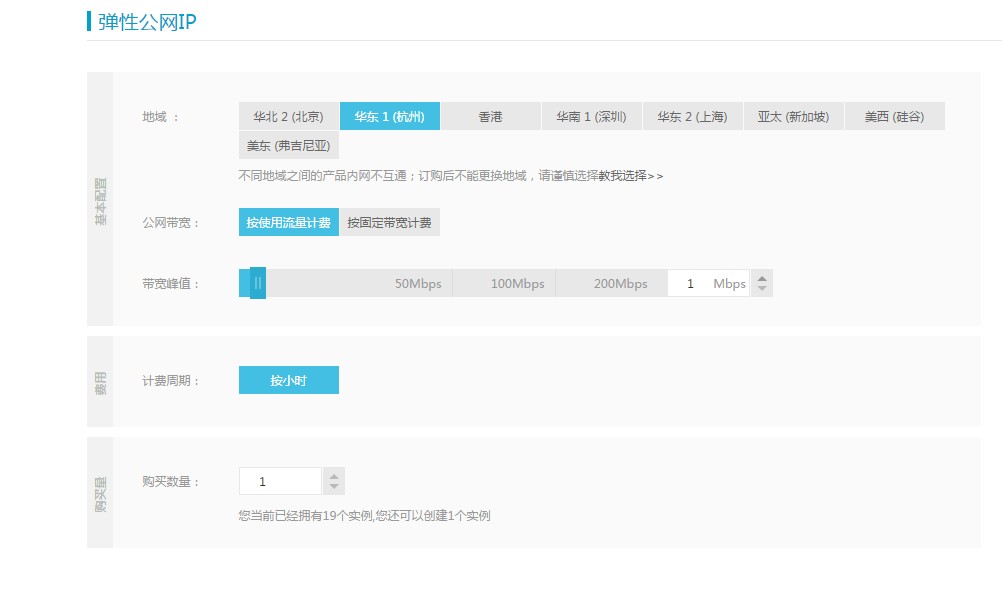
选择和VPC集群一致的地域,根据需要同步数据的实际情况选择按量计费或固定带宽,带宽峰值,购买数量设置为您master以外的节点数量。点击立即购买,等待开通
绑定Ip
成功后在ecs控制台给集群的每个ecs实例绑定一个EIP,就可以访问私有数据库的公网地址了。绑定的操作方式在ecs控制台-ecs实例后的管理-配置信息-更多-里面选择绑定弹性IP.
图6. 绑定弹性Ip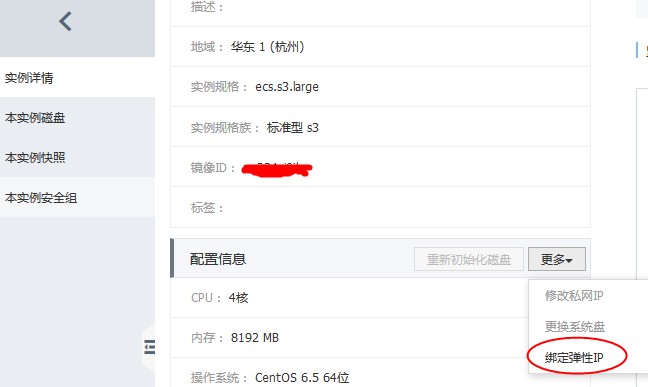
集群配置
放置 oracle jdbc jar
集群集成了常用的mysql jdbc jar,Oracle的jdbc jar需要去Oracle官网下载数据库可用的ojdbc jar,比如ojdbc14.jar,放在master节点的$SQOOP_HOME/lib目录下
检查网络
在master节点上连接Oracle数据库的访问地址,telnet ip port,如果无法连接,可能是因为你的数据库设置了防火墙访问规则限制,需要联系您数据库的运维人员设置集群所有节点的公网Ip允许访问。
选择Oracle连接
sqoop官方手册, oracle连接有三种写法
--connect jdbc:oracle:thin:@OracleServer:OraclePort:OracleSID
--connect jdbc:oracle:thin:@//OracleServer:OraclePort/OracleService
--connect jdbc:oracle:thin:@TNSName
选择适合您的连接方式。
测试连接
可以使用 sqoop eval执行一条查询语句确定连接是否正常. [eval 语法](http://sqoop.apache.org/docs/1.4.6/SqoopUserGuide.html?spm=5176.doc28133.2.7.K0HsDL#_literal_sqoop_eval_literal),如果提示用户名密码无法访问,可能是密码错误或者该账户没有访问的权限。
map任务提示网络不通
如果map任务报错提示The Network Adapter could not establish the connection,可能是数据库防火墙的访问规则没加上集群其他节点,需要全部节点都允许访问。