title: SQLServer · CASE分析 · CPU瓶颈问题的判定和解决
author: 天铭
发现问题
告警
数据库出现无法登陆的告警
定位原因
监控
活跃连接堆积
实例CPU持续99%+
实例总连接数超过规格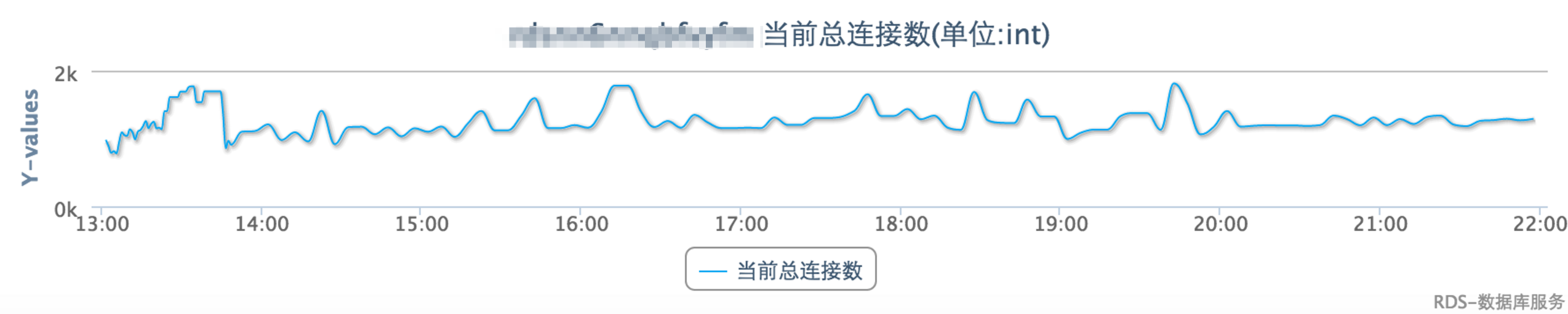
活跃链接堆积是结果,能堆积到500+可想对业务的影响已经非常严重了
连接数超过的原因跟业务上的限制策略有关
现场
实例正常连接已经无法建立,只能利用DAC协助诊断
使用DAC
实例等待
select lastwaittype,COUNT(*) from sys.sysprocesses
where spid>50
and lastwaittype!='MISCELLANEOUS'
group by lastwaittype
![]()
WITH [Waits] AS
(SELECT
[wait_type],
[wait_time_ms] / 1000.0 AS [WaitS],
([wait_time_ms] - [signal_wait_time_ms] ) / 1000.0 AS [ResourceS],
[signal_wait_time_ms] / 1000.0 AS [SignalS],
[waiting_tasks_count] AS [WaitCount],
100.0 * [wait_time_ms] / SUM ( [wait_time_ms]) OVER() AS [Percentage],
ROW_NUMBER() OVER(ORDER BY [wait_time_ms] DESC ) AS [RowNum]
FROM sys.dm_os_wait_stats
WHERE [wait_type] NOT IN (
N'CLR_SEMAPHORE', N'LAZYWRITER_SLEEP',
N'RESOURCE_QUEUE', N'SQLTRACE_BUFFER_FLUSH',
N'SLEEP_TASK', N'SLEEP_SYSTEMTASK',
N'WAITFOR', N'HADR_FILESTREAM_IOMGR_IOCOMPLETION',
N'CHECKPOINT_QUEUE', N'REQUEST_FOR_DEADLOCK_SEARCH',
N'XE_TIMER_EVENT', N'XE_DISPATCHER_JOIN',
N'LOGMGR_QUEUE', N'FT_IFTS_SCHEDULER_IDLE_WAIT',
N'BROKER_TASK_STOP', N'CLR_MANUAL_EVENT',
N'CLR_AUTO_EVENT', N'DISPATCHER_QUEUE_SEMAPHORE',
N'TRACEWRITE', N'XE_DISPATCHER_WAIT',
N'BROKER_TO_FLUSH', N'BROKER_EVENTHANDLER',
N'FT_IFTSHC_MUTEX', N'SQLTRACE_INCREMENTAL_FLUSH_SLEEP',
N'DIRTY_PAGE_POLL', N'SP_SERVER_DIAGNOSTICS_SLEEP')
)
SELECT
[W1]. [wait_type] AS [WaitType],
CAST ([W1]. [WaitS] AS DECIMAL( 14, 2 )) AS [Wait_S],
CAST ([W1]. [ResourceS] AS DECIMAL( 14, 2 )) AS [Resource_S],
CAST ([W1]. [SignalS] AS DECIMAL( 14, 2 )) AS [Signal_S],
[W1]. [WaitCount] AS [WaitCount],
CAST ([W1]. [Percentage] AS DECIMAL( 4, 2 )) AS [Percentage],
CAST (([W1]. [WaitS] / [W1]. [WaitCount]) AS DECIMAL (14, 4)) AS [AvgWait_S],
CAST (([W1]. [ResourceS] / [W1]. [WaitCount]) AS DECIMAL (14, 4)) AS [AvgRes_S],
CAST (([W1]. [SignalS] / [W1]. [WaitCount]) AS DECIMAL (14, 4)) AS [AvgSig_S]
FROM [Waits] AS [W1]
INNER JOIN [Waits] AS [W2]
ON [W2].[RowNum] <= [W1].[RowNum]
GROUP BY [W1]. [RowNum], [W1].[wait_type] , [W1] .[WaitS],
[W1]. [ResourceS], [W1].[SignalS] , [W1] .[WaitCount], [W1].[Percentage]
HAVING SUM ([W2] .[Percentage]) - [W1].[Percentage] < 95 ;
GO
![]()
CPU 开销大的SQL
诊断报告
实例在无法连接前的一个诊断报告也和我们的检查结果一致
实例CPU使用率![]()
等待信息![]()
活跃连接都在等CPU调度,spid已经复用到1.6K+
处理方式
临时
为了让实例快速恢复,首先要做的是适当放大调整CPU affinity mask,并且让用户应用做适当降级不要再次压垮实例
ALTER SERVER CONFIGURATION SET PROCESS AFFINITY CPU = 1 TO 2,6,9 TO 10,14 TO 16,19 TO 23
长期
长期需要优化SQL逐步从根本上解决问题,当然也有的时候SQL的执行计划已经很好,只是业务的并发和RT达不到用户要求,这就需要考虑升级或做业务调整
这个CASE通过类似几个SQL优化达到了不错的效果
set statistics profile on
set statistics io on
set statistics time on
select top 50 from where ='' order by id desc
set statistics profile off
set statistics io off
set statistics time off
![]()
![]()
执行计划的Bookmark可以进一步优化
优化建议
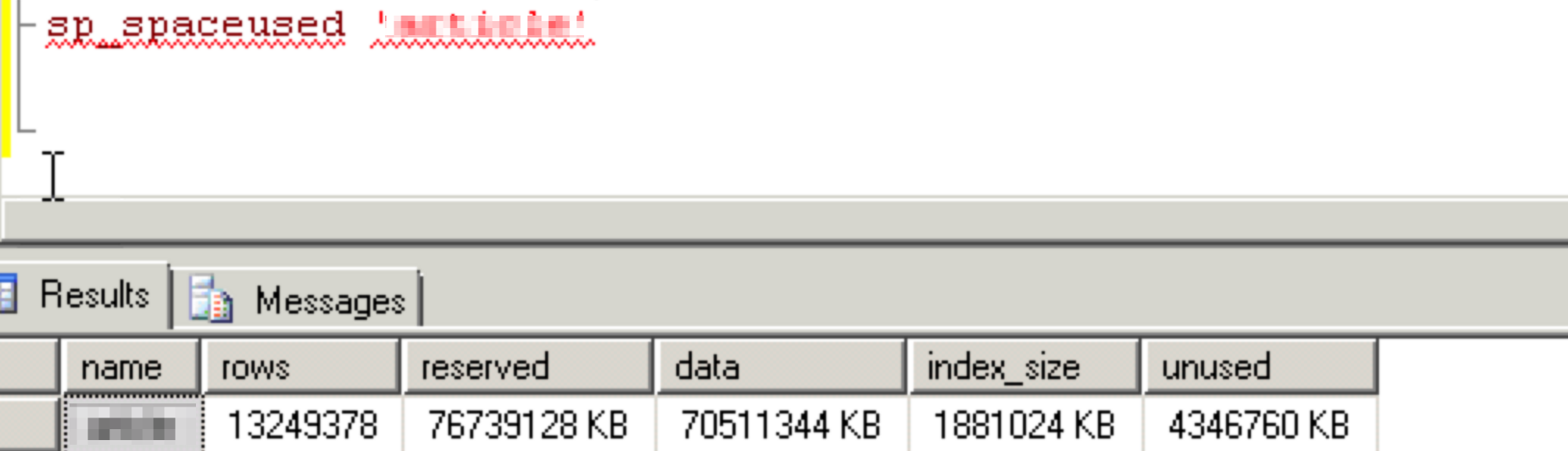
注意一般的情况下都要加online参数避免锁表时间过长,尤其是这个CASE中1kw+的大表;但也要清楚相应代价,具体可以看下这篇SQLServer 在线添加索引
处理结果
优化后的 SQL开销
set statistics profile on
set statistics io on
set statistics time on
select top 50 from where ='' order by id desc
set statistics profile off
set statistics io off
set statistics time off
![]()
优化后的SQL执行计划![]()
逻辑读从5k降到6,CPU从31降到0 ms,且从执行计划来看已经最优
实例整体优化后CPU开销变化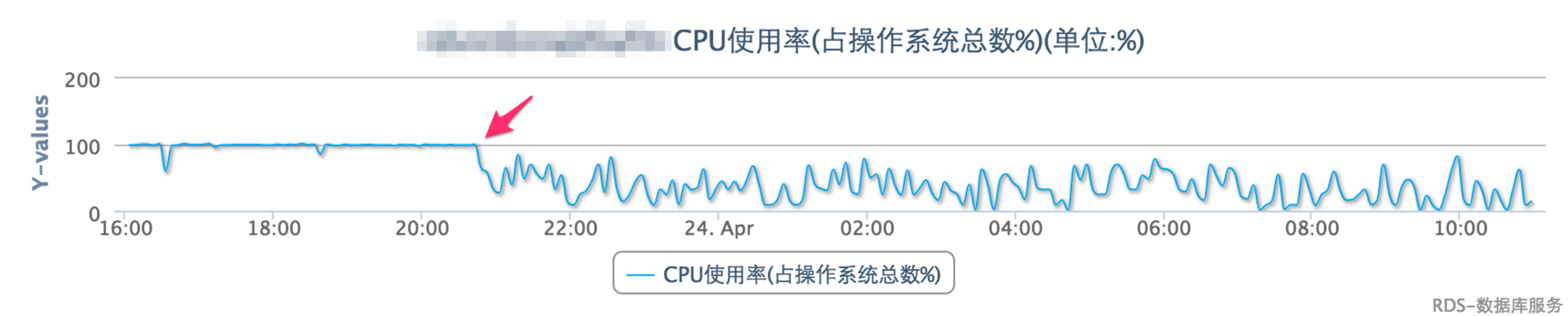
CPU开销明显已经下降
时间: 2024-12-31 09:11:05