最近几年,移动设备已经非常普及,对GPS的使用也越来越常见,比如快车专车产品中的实时位置和历史轨迹图,运动App中的跑步,骑行轨迹等,很多研发人都遇到了如何设计系统架构来高效存储和查询GPS数据的问题。
对于一个互联网产品,要面对大流量,突发大压力,要保证低延时,高稳定性,还要考虑以后的实时扩展性,作为负责人的话,还需要考虑成本。这样,设计一个满足这些需求的系统就不怎么简单了,比如下面这些应用。
在这篇文章中,我们将通过设计一个骑行类App的GPS功能来说明多种使用场景及其区别。
产品功能
我们先明确这款骑行产品需要具备的基础功能:
- 用户骑行过程中,App记录GPS轨迹
- 用户在骑行过程中可以在手机App中看到自己当前的位置,历史骑行轨迹以及最大时速,平均时速,骑行时间等统计值
- 用户在骑行完成后,可以查看自己历史的骑行记录
- 给好友、家人或恋人实时共享当前轨迹
- 运营需要分析用户轨迹某个维度的特征
存储系统
首先,我们来看一下此类产品的特点:
- 用户数大,比较有名的产品可能会有百万,甚至更多的用户。
- 有明确的高峰低谷,比如早晨,傍晚是高峰期,凌晨是低峰期。
- 存储的数据量比较大,数据量和场景,用户量极度相关。
- 产品可能会有爆发发展期,系统需要有非常快速的扩展能力。
- 跟时间相关,需要按时间查询范围,或者需要在不知道起始时间和结束时间情况下查询轨迹点。
- 成本低。
- 稳定性高,尤其是写。
总结下就是:
- 高并发写入,尤其是写:具有每秒处理千万请求的能力,且性能不能随着数据增大而下降。
- 按量付费。
- 单表大容量存储,最好不限表大小:PB级别。
- 实时水平扩展能力。
- 支持范围查询。
- 低成本。
- 高稳定性:SLA保障。
表格存储(Tablestore)是由阿里云自主研发的基于共享存储的NoSQL数据库,是一款专为海量数据高性能存取而设计的存储系统,10G以下免费。
表格存储可以完全满足上述所有要求,另外,还提供多版本,TTL,递增ID,增量通道等功能。
确定了存储系统后,我们再来看方案。
方案
表结构设计
表格存储最多支持四个主键,每个主键都支持三种类型,字符串,二进制和长整型,属性列是schema free的,可以自由修改。
在当前方案中,表格存储的表格可以这么设计:
| 主键顺序 | 名称 | 类型 | 值 | 备注 |
|---|---|---|---|---|
| 1 | partition_key | string | md5(user_id)前四位 | 为了负载均衡 |
| 2 | user_id | string/int | 用户id | 可以是字符串也可以是长整型数字 |
| 3 | task_id | string/int | 此次轨迹图的id | 可以使字符串也可以是长整型数字 |
| 4 | timestamp | int | 时间戳 | 使用长整型,64位,足够保存毫秒级别的时间戳 |
如何存
设计好了表结构后,我们可以看一下轨迹数据如何存:
比如原始数据是:
2017/5/20 10:10:10的时候小王在杭州西湖断桥上骑自行车,速度5m/s,当时风速2m/s,温度20度,已经骑行了8公里。
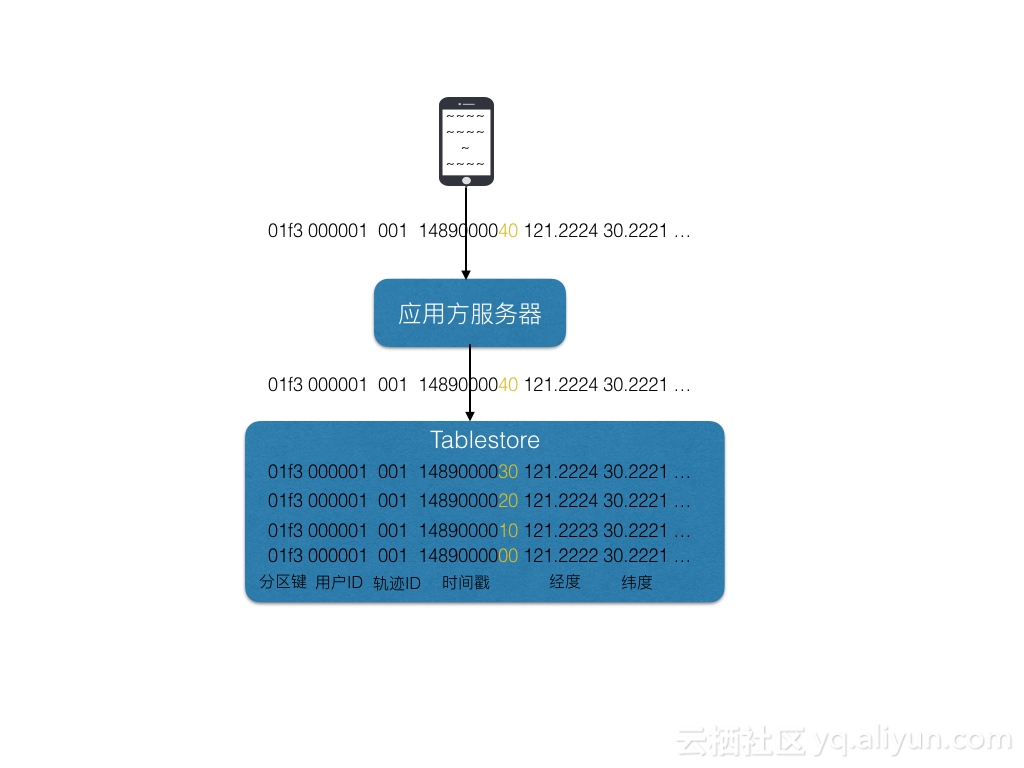
在表格存储中存储的是(10列);
| part_key | user_id | task_id | timestamp | longitude | latitude | speed | wind_speed | temperature | distance |
|---|---|---|---|---|---|---|---|---|---|
| 01f3 | 000001 | 001 | 1495246210 | 120.1516525097 | 30.2583277934 | 5 | 2 | 20 | 8000 |
主键
- part_key:第一个主键,分区建,主要是为了负载均衡,保证数据可以均匀分布在所有机器上,提高并发度和性能。如果业务主键user_id可以保证均匀分布,那么可以不需要这个主键。
- user_id:第二个主键,用户ID,可以是字符串也可以是数字,唯一标识一个用户。
- task_id:第三个主键,任务ID,也就是轨迹ID,表示某一次骑行任务的轨迹图,可以是字符串也可以是数字。
- timestamp:第四个主键,时间戳,表示某一个时刻,单位可以是秒,如果是每隔10秒记录一个GPS地址,那么相邻行的timestamp就相差10。时间戳1495246210等价于2017/5/20 10:10:10。
- 至此,上述四个主键可以唯一确定
某一个用户的某一次骑行在某一个时间点的数据。
属性列
- longitude:经度值。
- latitude:纬度值。这个(120.1516525097,30.2583277934)经纬度值表示的就是杭州西湖的断桥上。
- speed:骑行速度,可以是当前的瞬时值,也可以是过去10秒的平均值,也可以都记录。
- wind_speed:当前风速,这个值无法通过手机采集,需要特定的自行车车载模块。
- temperature:当前温度,可以直接取当前城市的温度值,也可以使用特定的温度传感器。
- distance:骑行距离,由于骑行的速度不会太快,可以用米为单位。
- 上面只是举了几个简单的例子,由于表格存储的属性列是schema-free的,任何时候都可以增删属性列,每一行可以有不同的属性列。甚至可以异步处理后,再回写挖掘出来的一些特征值。
下面我们来看一下各个场景:
GPS轨迹存储
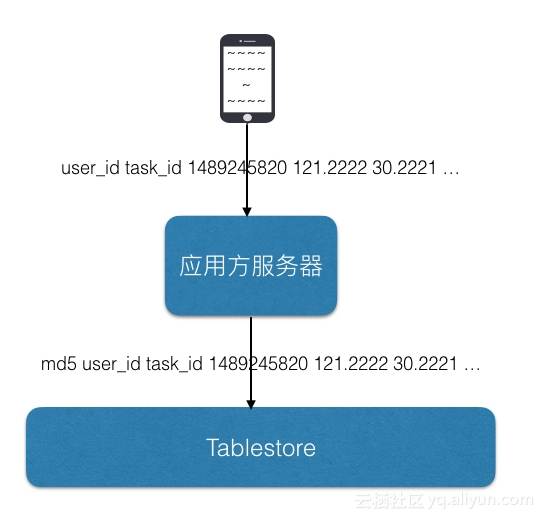
关键点:
- 使用表格的形式保存用户骑行过程中的meta数据
- 表格存储单表数据量无上限,支持万亿级在容量,性能上没任何问题。
手机端:
- 用户启动后,手机每隔10秒钟,发送一条数据给应用服务器,这条消息包括当前GPS数据和meta值(经度,纬度,速度,距离等)
服务器端
- 应用服务器收到客户端发送的消息后,先对其中的GPS数据做纠正,然后将消息保存到表格存储中的GPS轨迹表中,主键保存用户id,任务id,时间戳,属性列保存经度,纬度,耗费时间,距离等。某一个时刻的数据保存在一行中。
- 【补充】用户数据发送给用户的应用服务器后,应用服务器可以先做数据订正,订正好后再写到表格存储,但是有时候需要考虑到写流程是关键路径,清洗订正是非关键路径,需要写入和订正流程是异步流程,这时候可以直接使用表格存储Stream功能。数据直接写表格存储,然后用户应用服务器通过表格存储stream功能实时读取到新增数据,订正、清洗等完成后将结果写回表格存储,因为表格存储会在stream中保存12小时,所以,就算订正清洗功能短时间不可用,也不影响用户的使用。
GPS轨迹查询
通过表格存储GetRange接口可以查询到完整历史轨迹图。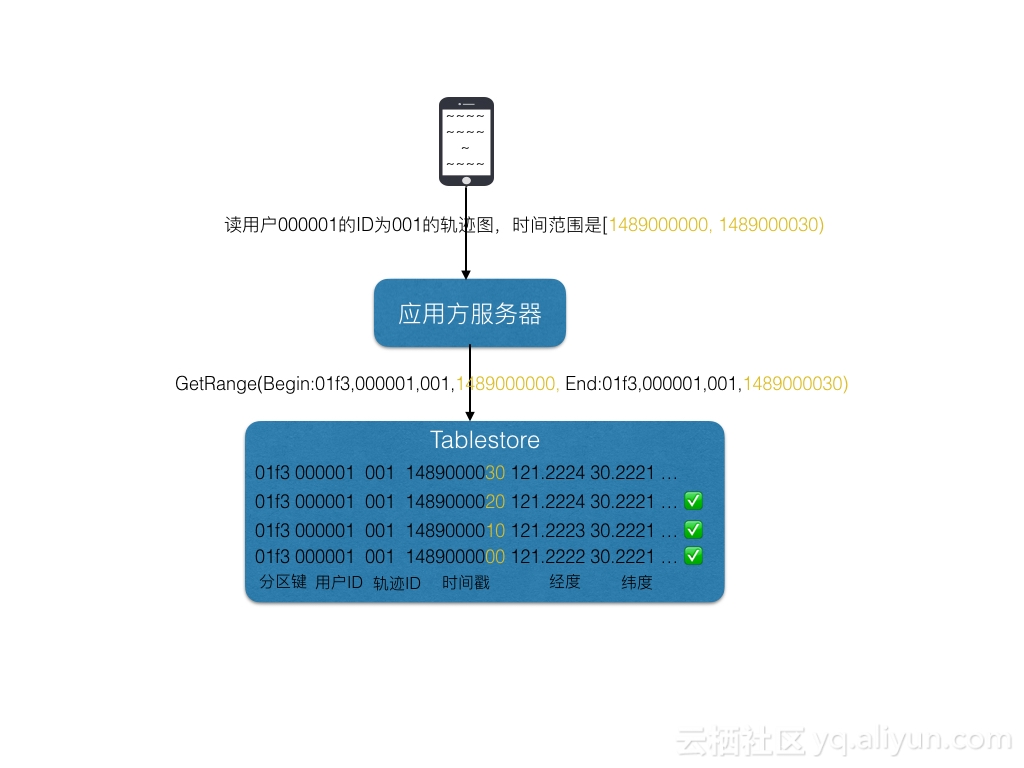
手机端:
- 当要查询自己这次骑行的历史轨迹和当前位置时,只需要通过一个范围查询(GetRange)就可以查到此次骑行的位置轨迹图。也就是查询这次任务从最早时间到当前时间内的GPS数据,对应于范围查询,首次查询时起始键可以是(md5(user_id).sub(0,4), user_id, task_id, MIN),结束键是(md5(user_id).sub(0,4), user_id, task_id, NOW),首次查询完后可以将NOW值保存下来,下次查询的时候起始键就可以是上一次查询的结束键,一直到此次骑行结束
服务器端
- 接收到手机端的查询请求后,将其转换成表格存储的范围查询(GetRange),就可以查询到此次骑行的历史轨迹图。
- 对于之前的历史轨迹图,也可以使用范围查询获取到历史轨迹。
其他人的GPS轨迹查询
关键点:
- 读扩散:自己的GPS轨迹数据只保存在自己的user id下,其他用户过来读取。
- 新表:share_gps_table,记录分享的user id,task id等信息。
- 加密:对于分享过程中涉及的ID等值加密,防止恶意用户冒充。
手机端:
- A用户启动后,可以分享当前骑行给自己的朋友B,也就是只需要把A的user_id和此次的task_id分享给朋友B。
- 朋友B的客户端获取到用户A的user_id和task_id后,就可以使用范围查询获取用户A在此次骑行中的实时位置和轨迹图了。
服务器端:
- 如果是分享者A通过二维码,链接等分享给用户B,这时候用户B的手机端可以获取到用户A的user id和此次task id(可以使用加密,防止被人篡改id),用户B可以去服务器端获取这次的用户A的骑行实时轨迹图。通过这种方式的分享记录可以持久化到表shard_gps_table中,也可以不持久化。
- 在App内部用户A分享给用户B,用户A将分享记录发送给服务器后,服务器记录在shard_gps_table表中,然后给用户B发送一个通知,包含一个特殊的ID值(可以是用户A的user id和task id加密后的一个值,这个值不能允许反向解析出user id和task id)。
- 用户B收到通知后,通过这个特殊的ID值到服务器端来查看表shard_gps_table中是否有对应的分享记录,如果有,则将对应的用户A的user id和task id发送给用户B,用户B再通过这些来读取用户A的轨迹图。
组团GPS轨迹查询
有时候,用户会组团去骑行,这时候,团员都希望可以在一张地图里面看到大家所有人的实时位置和历史轨迹图,团长也希望能通过这些值作为参考,安排大家休息地点和时间。对于这种场景,可以按下面方式实现:
关键点:
- 所有团员都使用同一个任务ID
- 读扩散(写的时候写到自己的user id下面,读的时候读其他成员的同任务id的数据)
- 使用新表:group_user_table,记录每个组的当前用户和历史用户(使用表格存储多版本功能可以保存用户的多次加入和离开时间)
手机端:
- 团长发起队伍,创建一个task id,其他成员加入,获取task id
- 每个成员骑行过程中,将自己的gps轨迹数据记录在自己的数据中(前两个主键为:user_id, task_id)
- 如果有成员先退出,后加入,仍然使用同task id,前后两段gps轨迹仍然有关联。
服务器端:
- 使用新表(group_user_table)记录每个task id下对应的成员id。这里可以使用多版本记录成员的多次退出加入事件。
- 查看整个队伍gps轨迹时,先通过task id查看所有成员ID,然后使用表格存储的BatchGetRow或者GetRange获取所有成员的轨迹数据。
团员异常路线报警
组团骑行或者组织的大型比赛中,有可能某些成员掉队或者骑错路线,这时候就需要让组织者知道,使用表格存储的stream功能就可以很容易对于异常骑行者做出报警。
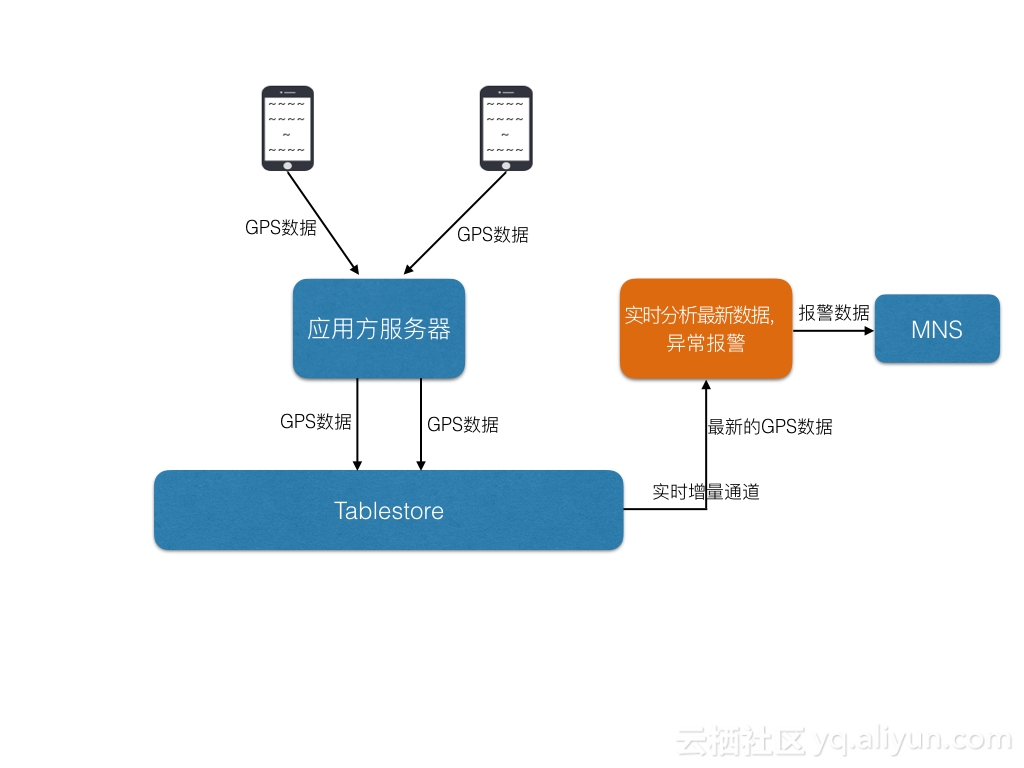
关键点:
- 使用表格存储的增量通道(Stream)功能。
- 读扩散:App中有可能会搞全国运动,这样同时参加用户可能数十万或者百万,这时候读扩散的优势就比较明显了。
服务器端:
- 每个组员的GPS轨迹数据发给表格存储后,表格存储会持久化数据后,然后新数据和更新数据会实时进入stream通道,用户可以实时或者周期性的使用SDK提供的接口读取到这些新进来的GPS数据,然后在自己的应用服务器中计算这些GPS数据和安全区域做比较,如果出了安全区域或者掉队太远,发送一条报警短信给组织者或者组织机构。这里可以使用阿里云存储团队的消息服务(MNS)
- 如果不想使用Stream功能,也可以直接通过GetRange接口从表中读取,由于不知道哪些用户有更新,需要读取所有用户的最近一段时间的数据,当用户量很大的时候,这个复杂度和开销都会很大,远远没有stream功能易用和性能好。
手机端:
- 组织者收到团员掉队或者走出安全区域的报警后,可以立即查看这名成员的历史轨迹和当前位置,然后安排人员联系异常团员,防止危险事件发生。
粉丝围观大V骑行
有社区后就有可能会有大V,大V可以在App中搞骑行直播,旁边可以展示GPS轨迹,几十万,甚至几百万粉丝围观,打赏等
关键点:
- 读扩散:这时候就只能使用读扩散了。由于前面的功能都使用了读扩散,那这里处理就非常简单。
手机端:
服务器端:
- 和前面处理逻辑差不多,这里就省略了。
运营分析
全量分析:
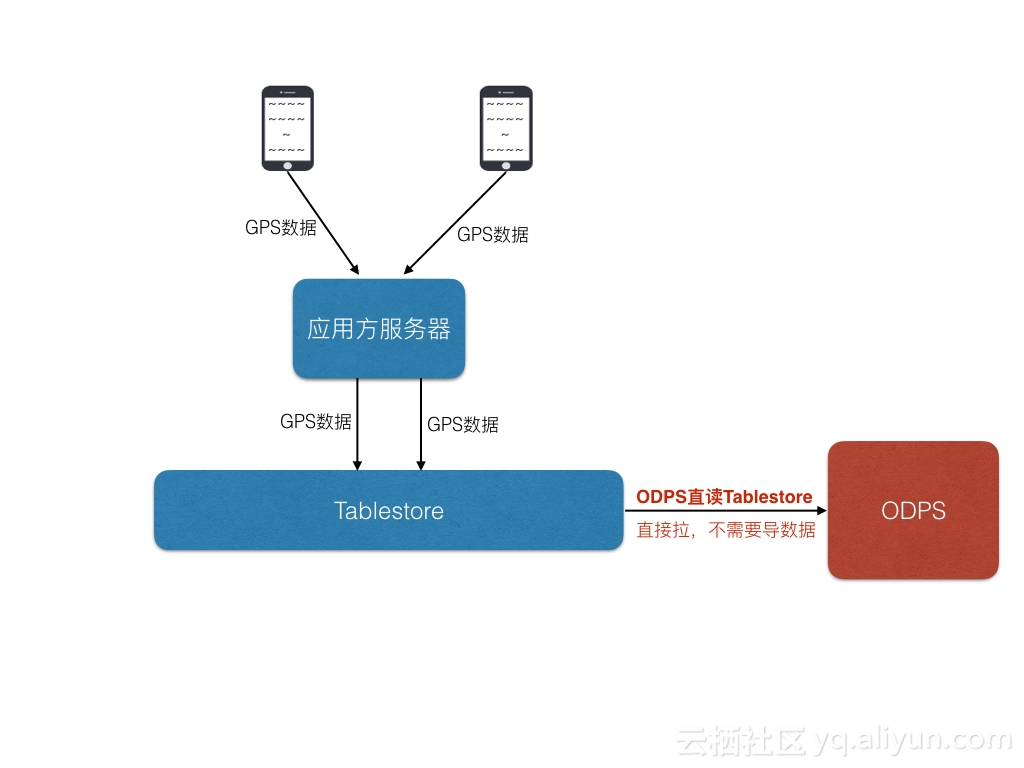
- SQL:使用Max Computer 2.0 (原ODPS)的SQL功能,可以直接读取表格存储中的数据,无需导出,节省了导出时间,更快地计算出结果。
- 自有job:使用dataX可以全量高并发的导出到Max Computer中去做分析处理,处理完后继续可以用dataX写会表格存储。
- 适用于批处理方式。
增量分析:
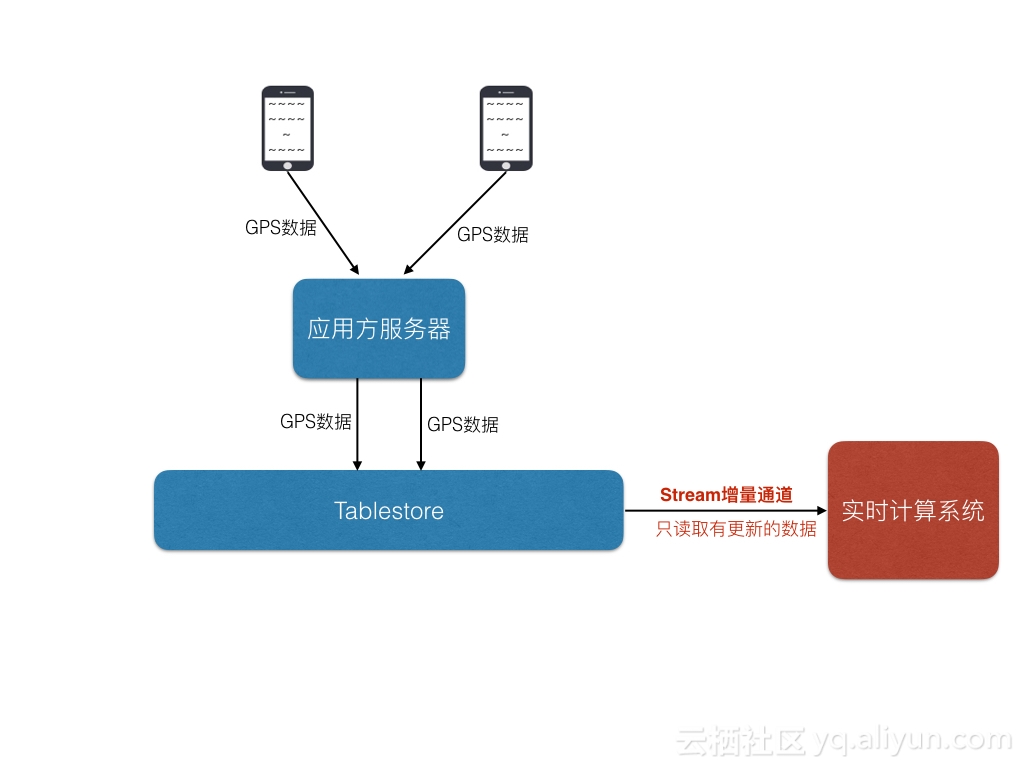
- 使用表格存储的stream功能可以获取最近十二小时的用户新增,更新,删除事件涉及的数据,即可以获取到数据的实时变化情况后做分析处理。
- 适用于实时处理方式。
直写方案
上述方案已经可以完全满足高并发,低延迟的需求了,那么这个技术架构是否是还可以继续优化呢?当然是可以。上述方案中,手机App其实可以直接将数据存储到表格存储,不需要经过应用服务器中转,减少对应用服务器的压力。
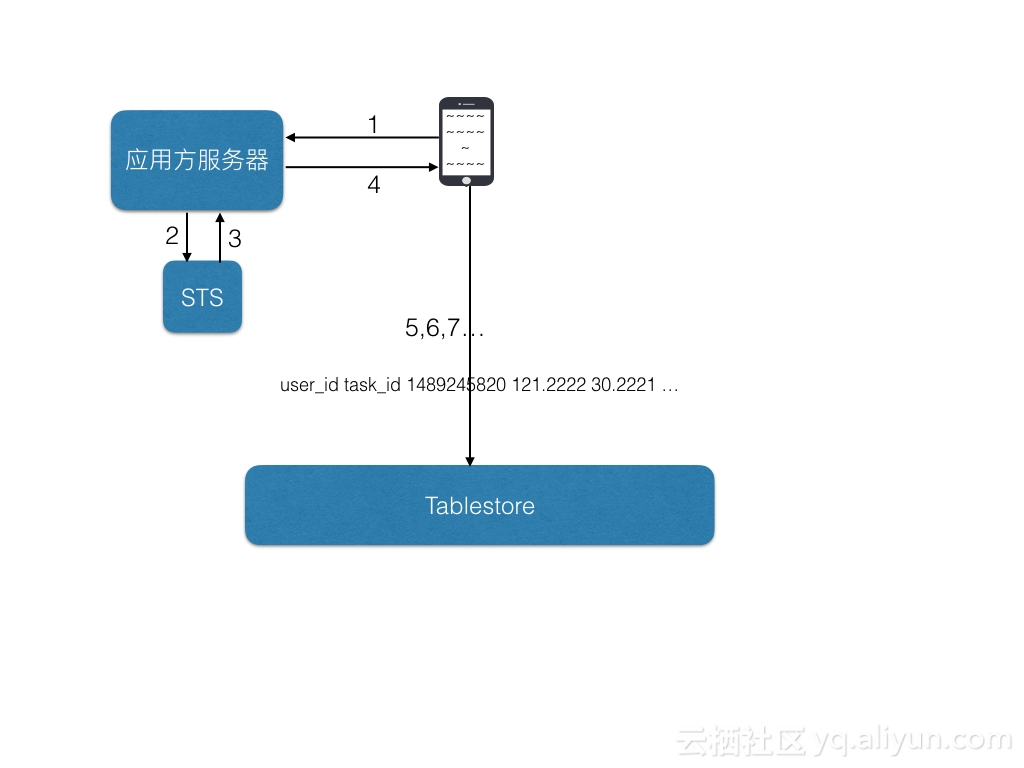
上述5个步骤分别是:
- 用户启动后,手机向应用服务器请求写表格存储的写权限。
- 应用服务器审批后,如果认为可以给予这个用户写权限,那么可以继续向阿里云的STS服务申请表格存储的临时写权限和授权时间。
- STS服务接收到请求后,生成一个临时的令牌,包括临时AccessKeyId,临时AccessKeySecret和临时token,将其返回给应用服务器。
- 应用服务器接收到STS的结果后,将其返回给手机端的APP。
- 手机端的App接收到临时令牌后,可以向表格存储开始持续写数据。等持续写了一定时间后,临时令牌会失效(失效时间用户可自定义),如果到时候还需要写入,可以继续申请新的令牌。
上述直写方案相对于原有方案,有如下一些优势:
- 可以减少应用服务器压力。
- 手机端直接写TableStore,不用经过应用服务器,路径更短,性能更佳。
- 将最关键的GPS写流程和应用服务器解耦合,旁路化,关键路径独立出来,就算应用服务器出现故障,不可服务了,但仍然不影响用户的GPS写入流程。
总结
前面讲了如何用表格存储(Tablestore)存储骑行类APP的GPS数据,以及stream功能在各个重要场景中的使用。虽然讲的是骑行类APP,但是其他场景也同样适用,比如跑步类、专车类、车联网等等。这里由于篇幅问题,每个部分都还比较简单,如果大家有兴趣,针对上述的每个点后续都可以继续展开再详细讲讲。
也欢迎大家加入表格存储技术交流钉钉群讨论: