mysql中分页查询有两种方式, 一种是使用COUNT(*)的方式,具体代码如下
|
1 2 3 |
|
|
1 |
|
另外一种是使用SQL_CALC_FOUND_ROWS
|
1 2 |
|
第二种方式调用SQL_CALC_FOUND_ROWS之后会将WHERE语句查询的行数放在FOUND_ROWS()之中,第二次只需要查询FOUND_ROWS()就可以查出有多少行了。
讨论这两种方法的优缺点:
首先原子性讲,第二种肯定比第一种好。第二种能保证查询语句的原子性,第一种当两个请求之间有额外的操作修改了表的时候,结果就自然是不准确的了。而第二种则不会。但是非常可惜,一般页面需要进行分页显示的时候,往往并不要求分页的结果非常准确。即分页返回的total总数大1或者小1都是无所谓的。所以其实原子性不是我们分页关注的重点。
下面看效率。这个非常重要,分页操作在每个网站上的使用都是非常大的,查询量自然也很大。由于无论哪种,分页操作必然会有两次sql查询,于是就有很多很多关于两种查询性能的比较:
SQL_CALC_FOUND_ROWS真的很慢么?
http://hi.baidu.com/thinkinginlamp/item/b122fdaea5ba23f614329b14
To SQL_CALC_FOUND_ROWS or not to SQL_CALC_FOUND_ROWS?
http://www.mysqlperformanceblog.com/2007/08/28/to-sql_calc_found_rows-or-not-to-sql_calc_found_rows/
老王这篇文章里面有提到一个covering index的概念,简单来说就是怎样才能只让查询根据索引返回结果,而不进行表查询
具体看他的另外一篇文章:
MySQL之Covering Index
http://hi.baidu.com/thinkinginlamp/item/1b9aaf09014acce0f45ba6d3
实验
结合这几篇文章,做的实验:
表:
|
1 2 3 4 5 6 7 |
|
注意下这里是使用b,a做了一个索引,所以查询select * 的时候是不会用到covering index的,select a才会使用到covering index
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 |
|
返回的结果:
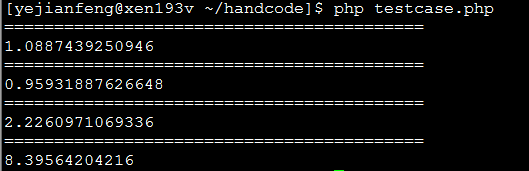
和老王里面文章说的是一样的。第四次查询SQL_CALC_FOUND_ROWS由于不仅是没有使用到covering index,也需要进行全表查询,而第三次查询COUNT(*),且select * 有使用到index,并没进行全表查询,所以有这么大的差别。
总结
PS: 另外提醒下,这里是使用MyISAM会出现三和四的查询差别这么大,但是如果是使用InnoDB的话,就不会有这么大差别了。
所以我得出的结论是如果数据库是InnoDB的话,我还是倾向于使用SQL_CALC_FOUND_ROWS
结论:SQL_CALC_FOUND_ROWS和COUNT(*)的性能在都使用covering index的情况下前者高,在没使用covering index情况下后者性能高。所以使用的时候要注意这个。