目的
统计业务日志中关键字的数量,并在统计数量达到一定条件时报警是业务日志的常见需求之一。本教程的目的是通过一个具体案例介绍如何对存储在日志服务产品中的数据进行关键字统计和报警。参照本教程的介绍,您可以快速走通日志的关键字统计、查询图表可视化和设置报警流程。
实战案例
使用前提
- 首先需要您将本地日志收集到日志服务(Log Service)中,如果您未使用过阿里云日志服务产品,可查看日志服务快速入门了解产品。
- 需要确保主账号的AccessKey是激活状态。AccessKey保持激活状态后您才能授权云监控读取您的日志数据。
- 激活方法:登录阿里云控制台,将鼠标移至页面右上角您的用户名上方,在显示的菜单中单击 "AccessKeys" 。在弹出的确认对话框中单击“继续使用AccessKey”以进入 AccessKey管理页面 。创建密钥对(Access Key),确认状态已设置为“启用”。

统计日志关键字
在使用日志监控前,需要您确保收集到日志服务中的日志已经被切分为Key-Valve格式。参考常见日志格式的处理方法。
- 激活方法:登录阿里云控制台,将鼠标移至页面右上角您的用户名上方,在显示的菜单中单击 "AccessKeys" 。在弹出的确认对话框中单击“继续使用AccessKey”以进入 AccessKey管理页面 。创建密钥对(Access Key),确认状态已设置为“启用”。

日志样例
2017-06-21 14:38:05 [INFO] [impl.FavServiceImpl] execute_fail and run time is 100msuserid=
2017-06-21 14:38:05 [WARN] [impl.ShopServiceImpl] execute_fail, wait moment 200ms
2017-06-21 14:38:05 [INFO] [impl.ShopServiceImpl] execute_fail and run time is 100ms,reason:user_id invalid
2017-06-21 14:38:05 [INFO] [impl.FavServiceImpl] execute_success, wait moment ,reason:user_id invalid
2017-06-21 14:38:05 [WARN] [impl.UserServiceImpl] execute_fail and run time is 100msuserid=
2017-06-21 14:38:06 [WARN] [impl.FavServiceImpl] execute_fail, wait moment userid=
2017-06-21 14:38:06 [ERROR] [impl.UserServiceImpl] userid=, action=, test=, wait moment ,reason:user_id invalid
切分成如下字段
| Key | Value |
|---|---|
| content | 2017-06-21 14:38:05 [INFO] [impl.FavServiceImpl] execute_fail and run time is 100msuserid= |
| content | 2017-06-21 14:38:05 [WARN] [impl.ShopServiceImpl] execute_fail, wait moment 200ms |
| content | 2017-06-21 14:38:06 [ERROR] [impl.ShopServiceImpl] execute_success:send msg,200ms |
| content | ... ... |
1. 授权云监控只读权限。
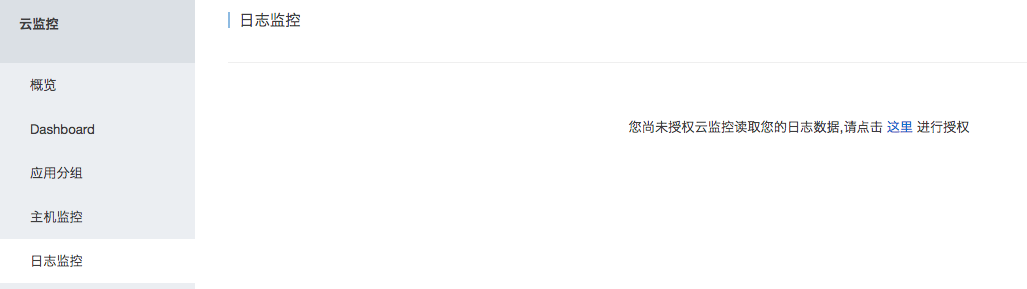
- 进入云监控首页,选择日志监控功能。
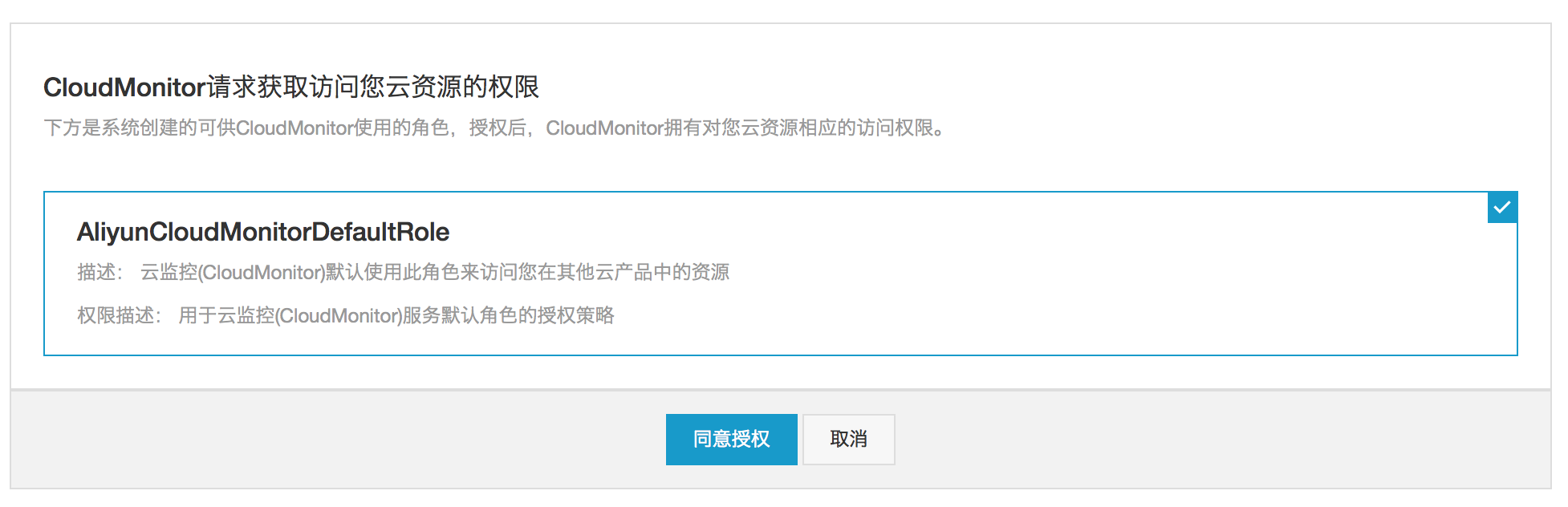
- 按照页面提示,点击“这里”进行授权。初次使用日志监控功能时需要授权,后续不再需要授权。授权后云监控会获得读取您日志数据的权限,并且仅用于按照您配置的处理规则进行日志数据处理的用途。
- 按照页面提示,点击“这里”进行授权。初次使用日志监控功能时需要授权,后续不再需要授权。授权后云监控会获得读取您日志数据的权限,并且仅用于按照您配置的处理规则进行日志数据处理的用途。
2. 配置统计方式
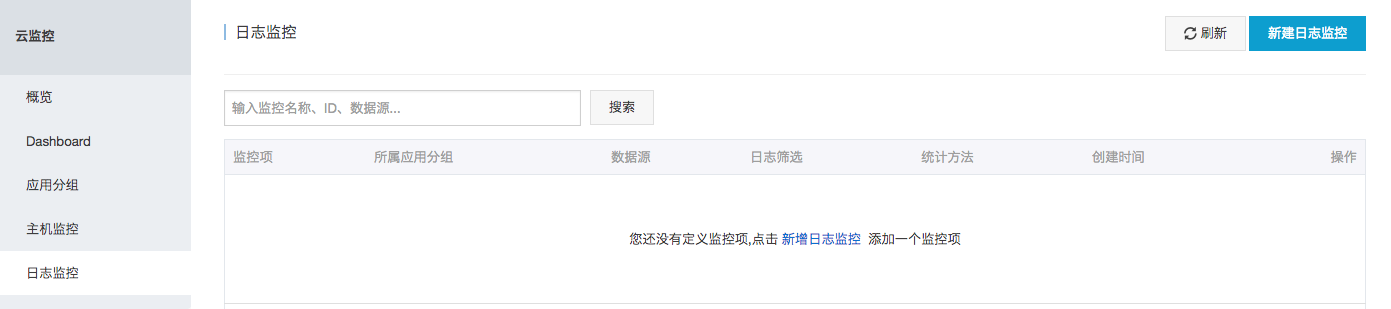
- 授权后可进入如下日志监控列表页面。
- 点击“新建日志监控”,进入创建页面。
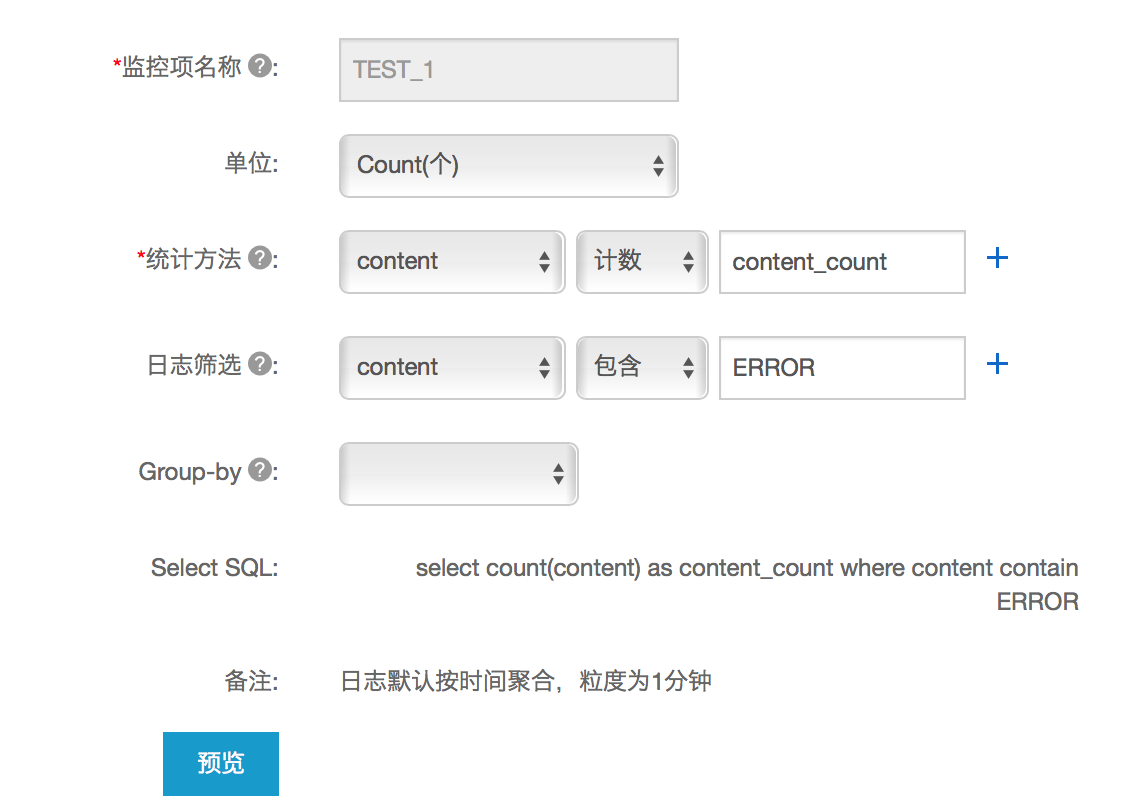
- 关联资源,选择您需要进行关键字统计的日志服务资源。
- 预览数据:如果您选择的日志服务中已经写入数据,可以在第二步分析日志的预览框中查看到原始的日志数据。
- 分析日志,本步骤用于定义如何处理日志数据。不支持日志的字段名称为中文。这里以统计ERROR关键字数量为例,统计日志每分钟出现的ERROR关键字数量。通过“日志筛选”过滤出content中包含“ERROR”关键字的日志记录,并通过“统计方法”中的计数(Count)方法计算筛选后的记录数。
- 点击“确定”按钮后保存配置。
- 关联资源,选择您需要进行关键字统计的日志服务资源。

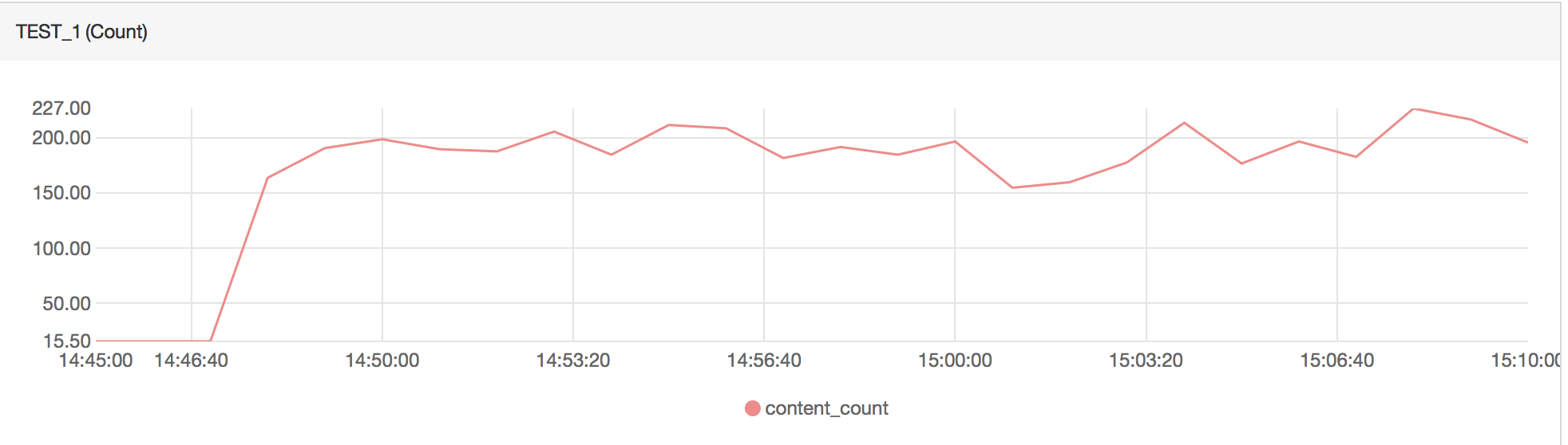
3. 查看统计数据
创建完日志监控以后,等待3-5分钟即可查看统计数据。查看方法是进入日志监控的指标列表页面,点击“操作”中的“监控图表”查看监控图。
4. 设置报警规则
- 设置方法是进入日志监控的指标列表页面,点击“操作”中的“报警规则”进入报警规则列表页面。
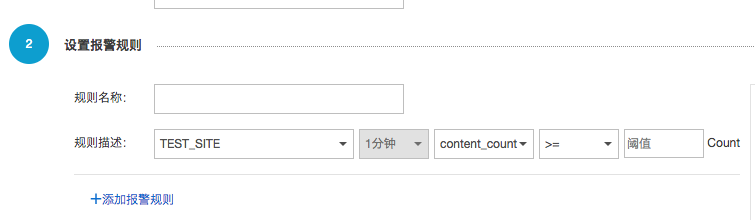
- 然后点击页面右上角的“新建报警规则”按钮,进入创建报警规则页面。
- 为报警规则命名,并在规则描述中配置需要报警的情况。
- 选择需要报警的联系人组和通知方式并确认保存,便完成了报警规则的设置。
时间: 2025-01-20 20:10:23