执行记录查看
1.登录阿里云 E-MapReduce 控制台执行计划页面。
2.单击相应执行计划条目右侧操作中的运行记录,即可进入执行记录页面。如下图所示:
执行序列 ID: 本次执行记录的执行次数,表明了它在整个执行队列中的顺序位置。比如第一次执行就是1,第n次就是n。
运行状态: 每一次执行记录的运行状态。
开始时间: 执行计划开始运行的时间。
运行时间: 到查看页面当时为止,一共运行的时间。
执行集群: 执行计划运行的集群,可以是按需也可以是一个关联的已有集群。点击可以前往集群的详情页查看。
操作
查看作业列表:单击该按钮,即可进入单次执行计划的作业列表查看每个作业的执行情况。
作业记录查看
在这里可以查看单次执行计划的执行记录中的作业列表,以及每一个作业的具体信息,如下图所示:

作业执行 ID:作业每一次执行都会产生一个对应的 ID,它和作业本身的 ID 是不同的。这个 ID 可以想象成作业每运行一次的一个记录的唯一标示,您可用其在 OSS 上进行日志查询。
作业名称:作业的名称。
状态:作业的运行状态。
作业类型:作业的类型。
开始时间:这个作业开始运行的时间,都已经转换为本地时间。
运行时间:这个作业一共运行了多久,以秒为单位。
操作
停止作业:无论作业在提交中还是在运行中,都可以被停止。如果是提交中,那么停止作业会让这个作业不执行。如果是在运行中,那么这个作业会被 kill 掉。
stdout:记录 master 进程的标准输出(即通道 1)的所有输出内容。如果运行作业的集群没有打开日志保存,不会有此查看功能。
stderr:记录 master 进程的诊断输出(即通道 2)的所有输出内容。如果运行作业的集群没有打开日志保存,不会有此查看功能。
查看作业实例:查看作业的所有 worker 的节点的日志。如果运行作业的集群没有打开日志保存,不会有此查看功能。
作业worker日志查看
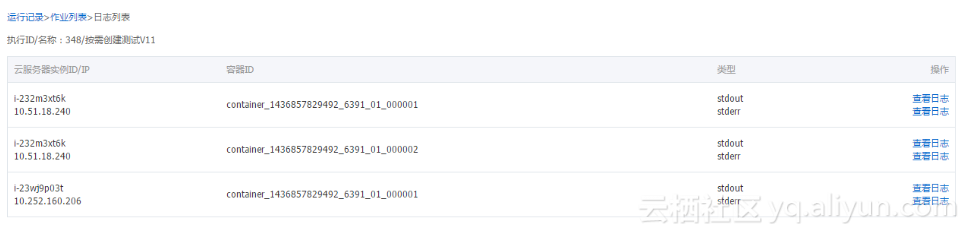
云服务器实例 ID/IP:运行作业的 ECS 实例 ID,以及对应的内网 IP。
容器 ID:Yarn 运行的容器 ID。
类型:日志的不同类型。stdout 与 stderr,来自不同的输出。
操作
查看日志:单击对应的类型,查看对应的日志。