1.2 智能金融·个性化推荐
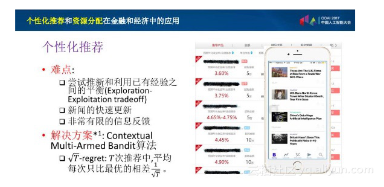
第一类是关于个性化推荐的情况。我们刚才已经看到过的,有理财产品或者是金融类新闻的每天推送的情况。我们知道,对于不同的用户来说,可能关注点是不一样的,甚至有时用户自己都不知道,自己的风险承受能力怎样,自己到底希望要一个怎样的预期年化收益率。但是我们依然希望通过观察用户的点击历史,慢慢地学到用户潜在的一些特性参数。这是一个(像刚才梦迪提到的)增强学习的过程,其中需要处理所谓的Exploration Exploitation Tradeoff:要在推荐一些确定知道适合该用户的,以及推荐一些相对未知但可能更适合一些新的(理财产品)这两者之间找到恰当的平衡。
再有一些其他的场景,比如说金融类的新闻推荐的时候就会遇到一些更麻烦的问题。新闻由于其本身的特性,更新得特别快,推送一个过时的新闻是没有意义的。另外在移动端,推荐显示的一般是一个新闻列表,这样就会有一个反馈非常少的问题。比如说我第1屏推20个,不是这20个所有的反馈我都能拿到。我可能看到的是用户点击了第2个、第6个,但是第6个之后发生了什么事情就完全不知道了,可能第7、8个新闻用户看了标题不感兴趣所以就没点,也可能看完第6个就关掉app了,第7、8个根本连标题都没有看。这种对列表的推荐和反馈信息会跟以前传统的情景很不一样。
有一类办法能够一定程度上解决这种冷启动(cold start),或者是目标的变化非常迅速的情况,就是用强化学习里Contextual Multi-Armed Bandit的算法。我们去年做的一个结果是,如果你做T次这样的推荐,平均来看,每一次你离最优解的只相差1/T;也就是说在对用户隐藏参数和未来信息都不确定的情况下,我们的算法仍然会非常接近于最优推荐。
稍微讲一点这里的细节。我们这里的模型是说,假设你有一个可以执行的Action的集合,在每一轮时这个Action的集合可以比如根据来的用户不同而不一样。这个Action就是一个你要推荐的有序列表(ordered list)。当用户看到这个列表以后,就会从前往下一个一个去检查,然后会在一个地方停止了,而不再检查后面的项目。这里并不知道在哪里停止了,我们能拿到的反馈只是用户在哪里点击过了。

有时在其他场景中有不只点击的反馈,比如App推荐,你会看到用户下载行为;电商的产品推荐,你会看到用户购买行为;不一样的场景会有不同的反馈。但是无论那种反馈,我们看到以后需要根据这些信息,来决定下一步怎样做。我们用后悔度(Regret)来衡量算法的有效性:在整个的T轮推荐里面,我们算法的行为,和如果我们知道所以隐含参数的情况下应该选择的最优行为之间的差别。我们没有办法展开很多的细节,只能说我们的结果是在T轮中,我们的Regret可以控制在T这么大。后来,我们又进行了一系列的延伸,能够处理多个点击的情况,非线性点击率期望的情况和结合用户间相似度的方法等。