2.2 关系赋值
Tutorial D中的关系赋值语法,不是像INSERT或DELETE一样的缩写,而是使用如下的通用格式。
R := rx
在这里“R”是一个关系变量(从语法上来说,其实就是一个关系变量的名字),“rx”是一个关系表达式,表示关系“r”和关系变量“R”是同一类型的。现在显而易见的是(这里要感谢David McGoveran的观察)任何这类赋值都在逻辑上等价于下列格式之一。
R := ( r MINUS d ) UNION i
在这里:
r是R的“原有”值。
d是将要从R中删除的数组的集合(“删除集合”)。
i是将要被插入到R中的数组的集合(“插入集合”)5[5]。
dr,即d是r的一个子集,意味着我们不可能删除任何不存在的数组。
i和r交集为空(意味着我们不可能插入任何已经存在的数组)。
d和i的交集也为空。
d和i是被清晰定义并且唯一的6[6]。
以上几点可以很方便地用文氏图来解释清楚,如图2.2所示。解释说明:在这个图表中r、d和i如上面所述,u则是与它们同类型的全域关系(换句话说,u是由所有与R具有相同关系头的数组所组成的关系,当然也包含那些已经在R之内的数组)。请注意u-r的差集是r的绝对补集(也就是说,u-r是由所有与R具有相同关系头,但不包含在R之内的数组所组成的关系)。
当然,删除集合d有可能为空,在这种情况下,之前的赋值效果就相当于一个纯粹的INSERT操作。或者当插入集合i为空时,赋值效果就相当于一个纯粹的DELETE操作。又或者,d和i都为空,那么赋值操作的效果就会退化为一个“空操作”R := R。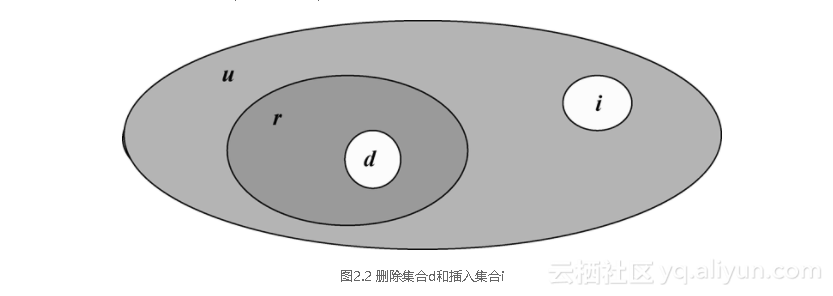
根据以上所说的,原来的赋值R: = rx实际上等价于下面的“多重”赋值(“多重赋值”详见本节后面的详细介绍)7[7]。
DELETE d FROM R , INSERT i INTO R
如此一来,虽然我前面曾经说过这类关系赋值其实是我们唯一需要的更新操作,但是我们还是可以始终把它想成DELETE和INSERT这两个操作(从感觉上来讲,好像还是这样想起来方便一些)。这是因为当我们遇到一个很可能发生的随机的针对关系变量R的多重赋值时,包括前面例子中这种用公式表达的比较清晰的对R的UPDATE操作,我还是建议将赋值转化为一个对R的DELETE操作和一个对R的INSERT操作,毕竟删除集合d和插入集合i是明确定义的、交集为空的,和独一无二的。注意:由于这里已经讲过了比较清晰的UPDATE操作,所以接下来我只有在遇到值得说的地方才会再次讨论这个问题。同样,我也会忽略d和i在实际运算中所碰到的大多数问题。和我其他大多数作品一样,在本书中我首要关注的是先要让大家明白这个理论,而不是首先关注实际执行中出现的问题。当然,我并不是说实际操作当中遇到的问题不重要。Au contraire(法语:恰恰相反),实际上检查实施操作的可行性对确保本理论的正确性是至关重要的。
语法要点
我在这里再次重申,关系赋值R: = rx在逻辑上等价于:
DELETE d FROM R , INSERT i INTO R
请一定注意,正是因为d和i的交集为空,所以无所谓DELETE或者INSERT哪个操作“先进行”。(关于这个问题我一会儿还要再多说一点,即在多重赋值的情况下独立操作的完成情况。)所以,我们等于可以这么说:原始赋值逻辑上与下面任意一个关系表达式等价。
WITH ( R := R MINUS d ) : INSERT i INTO R
WITH ( R := R UNION i ) : DELETE d FROM R
我们甚至可以说它也和下面任意一个关系表达式等价。
WITH ( DELETE d FROM R ) : INSERT i INTO R
WITH ( INSERT i INTO R ) : DELETE d FROM R
```
如果你不熟悉上面所使用的WITH操作的话,我推荐你看看《SQL and Relational Theory》。
其实还有更棒的。Tutorial D还额外支持DELETE和INSERT的变体,分别叫作IDELETE(“既有值DELETE”)和D_INSERT(“无交集INSERT”)。使用I_DELETE,会在你试图删除一个不存在的数组(也就是最开始没有出现的数组)时报错;类似的,使用D_INSERT会在你试图插入一个已经存在的数组(也就是已经出现的数组)时报错。因此,我们可以说原赋值_R: = rx逻辑上等价于以下任意关系表达式。
```javascript
I_DELETE d FROM R , D_INSERT i INTO R
D_INSERT i INTO R , I_DELETE d FROM R
为了简化问题让大家易于理解,在本书之后的部分我还是会以传统的DELETE和INSERT操作作为例子进行讲解,并且我还会在全文中应用下面这个假设,请一定注意!尝试删除不存在的数组不是错误,尝试插入存在的数组也不是错误。
多重赋值
“第三宣言”需要的,也是我们已经提过的Tutorial D肯定支持的,是一种多重赋值的方式,这种方式允许许多彼此独立的赋值操作“同时进行”。例如:
DELETE ( S WHERE SNO = ‘S1’ ) FROM S ,
DELETE ( SP WHERE SNO = ‘S1’ ) FROM SP ;
解释:首先,请注意第一行末尾的逗号,它意味着两个DELETE都是同一个整体声明的一部分。第二,如我们所知,DELETE其实就是赋值,所以上面这个“双DELETE”其实就是下面这个双赋值的缩写。
S := ... , SP := ... ;
这个声明分别给关系变量S和SP各赋了一个值,它们都是同一个操作的一部分。我们概括来讲,多重赋值的语义有下面2条。
首先,在等式右侧的独立赋值的源表达式进行计算。
然后,那些独立赋值操作被执行。8[8]
我们来观察一下,正是因为所有的源表达式都要先进行计算,然后独立赋值再执行,所以那些独立赋值都不会被其他运算结果影响,也因此它们被执行的顺序也跟运算结果无关(如果愿意,你甚至可以把它们的执行想象成平行发生的,或“同时进行”的)。另外,多重赋值从语义上来讲被当作“原子级”操作,也就是说在这类赋值发生的“过程中”不会进行任何一致性检查(这也正是为什么“宣言”从开始就要求对操作的支持)。注意:一致性约束在本章后面会有详细讨论。
语义不是语法
我前面已经说过,任何一个关系赋值都可以等价为一个DELETE操作加上一个INSERT操作,当删除集合d和插入集合i是被准确定义,交集为空,并且独一无二时。但是请注意下面这个重点,两个不同的赋值可以使用完全不同的语法,但却对应相同的删除集合和插入集合,下面我为大家详细说明(在这里要感谢Hugh Darwen提供了这个例子)。
假设一个关系变量R只有两个属性,K和A。我们令{K}为单键,然后,令K与A的类型都是INTEGER,并令R只包含两个数组,(1,2)和(3,−2)。9[9]现在我们来看下面两个显式的UPDATE操作。
UPDATE R : { K := K + A } ;
UPDATE R : { A := -A } ;
请注意,具体来说第一个操作是“键UPDATE”,而第2个则不是,因此,如果一个格式,如ON UPDATE K…的补偿操作已经被定义(在SQL环境下很可能发生),那么我们可以预测这个操作会与第一个UPDATE有关,而与第2个无关。但是很容易看出,如果我们给R设定具体的初始值,那么这两个UPDATE的效果完全等价。实际上,它们都等价于下面这个赋值。10[10]
R := RELATION { TUPLE { K 1 , A -2 } , TUPLE { K 3 , A 2 } } ;
换句话说,删除集合d对这两个UPDATE而言是完全一样的,而插入集合i也是如此。(练习:这两个集合它们到底是什么?)因此很明显,我们想要的是对于补偿操作而言,它应当是由相应的删除集合和插入集合适时地调用,而不是由碰巧列出更新表达式的语法武断地选择。