表格存储在8月份推出了容量型实例,直接支持了表级别最大版本号和生命周期,高性能实例也将会在9月中旬支持这两个特性。那么, 最大版本号 和 生命周期 以及特有的 有效版本偏差 该如何理解呢,在实际的使用上对我们又有什么帮助呢? 让我们来详细了解下吧!
数据多版本
想了解这三个概念都需要从数据多版本说起。当一行数据在写入后被多次更新,那么之前的每次更新其实都是一个历史版本,在很多场景下,历史更新的值是都需要能够查询的。比如大家都熟悉的物流快递,包裹从一个站点到下一个站点,一直到我们手中,中间的所有中转流程都是需要记录查询的,每到一个站点,实际上就是对快递状态的更新。
表格存储的数据模型(官方文档)如下:
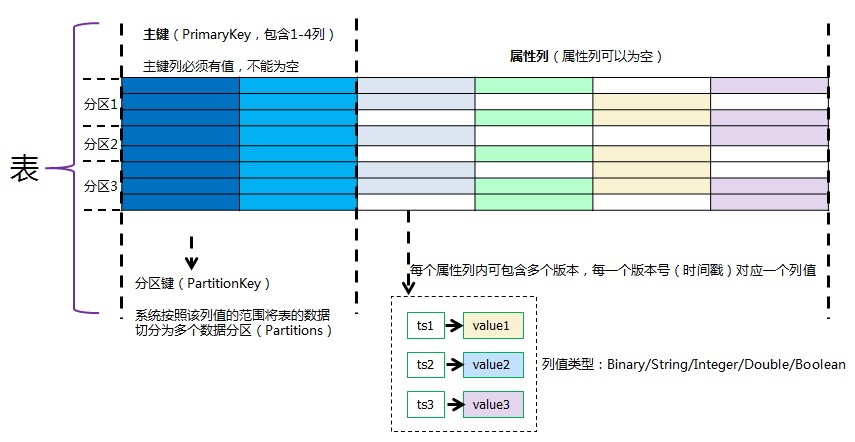
从图中我们可以看到表格存储支持的多版本是到属性列级别的,也就是每条记录中的不用列可以有不同的版本号。
多个版本有了,那么该怎么标识这些不同版本的数据呢?
最简单的方式就是每个版本的数据设定一个版本号,然后递增,比如第一次写入版本号为1,更新一次为2,再更新一次就是3,一次累加,在查询的时候我们就可以根据版本号来查询,比如查询当前值,或者第二次更新的值(即版本号等于3的数据)。
那么,问题又来了,有些场景是需要记录数据更新的时间的,这种情况下是不是有更好的方法呢?
答案当然是肯定的,不光是1、2、3...是递增的,计算机里面的时间戳也是递增的,时间戳也就是 1970-1-1 00:00:00 UTC 时间到当前写入时间的秒数,那么使用时间戳来作为数据的版本号既能起到标识各个版本数据的作用,还能够说明这个版本的数据的更新时间是什么时候,岂不是一举两得?
表格存储允许我们在写入数据时给每一个属性列指定版本号,如果不指定,那么在写入时服务端会根据当前时间的 毫秒单位 时间戳(从1970-1-1 00:00:00 UTC计算起的毫秒数)为属性列生成版本号。我们指定的版本号系统也会按照毫秒换成时间戳来作为该条数据的诞生时间。
一定要注意,系统指定的版本号是毫秒哦!
一定要注意,系统指定的版本号是毫秒哦!
一定要注意,系统指定的版本号是毫秒哦!
多版本使用示例之快递状态查询
我们以上面提到的快递查询为例,为了支持快递状态的查询,一般情况下表的设计和数据是这样的:
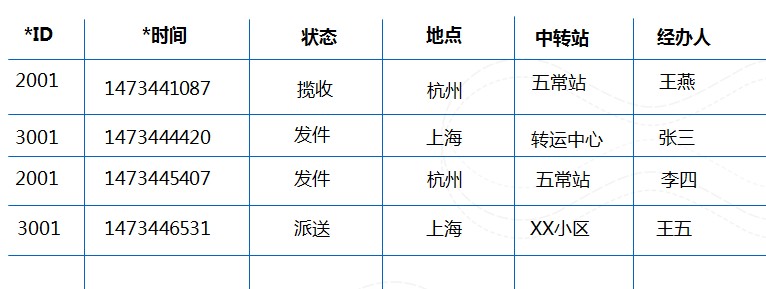
使用多版本之后是这样的:

PS:上述的时间使用的是时间戳值,表格存储中是以毫秒为单位,换算成对应的时间为:
- 1473441087:2016/09/10 01:11:27
- 1473445407:2016/09/10 02:23:27
- 1473444420:2016/09/10 02:07:00
- 1473446531:2016/09/10 02:42:11
查询的时候可以可以指定查询所有的版本:
// 读一行
SingleRowQueryCriteria criteria = new SingleRowQueryCriteria(TABLE_NAME, primaryKey);
// 设置读取所有版本
criteria.setTimeRange(new TimeRange(0, System.currentTimeMillis()));
GetRowResponse getRowResponse = client.getRow(new GetRowRequest(criteria));
Row row = getRowResponse.getRow();
或者查询版本号在最近一天范围的数据:
criteria.setTimeRange(new TimeRange(System.currentTimeMillis() - 86400000, System.currentTimeMillis()));
代码参考,使用起来是不是很方便呢?
最大版本数
数据版本多了之后,很多情况下只需要保留最近的若干个版本,而不需要保存全部版本,最大版本数就应孕而生。
用户可以设置一个数据表中给每个属性列最多保存的版本个数,用户将不能读到超过最大版本数的数据版本,系统也会在后台对这些版本的数据进行清理。
这样,最大版本数一方面可以自动清除不需要版本数据,另外一方面,可以在很多场景下简化使用方式,比如:
某互联网公司推出一款具有支付功能的APP,为了降低盗刷的风险,在每次支付时就需要运行一系列的风控计算架构设计。这些风控计算中,最基础的就是登录地址验证,保存用户最近10次的登录ip信息,对这10次ip进行校验,如果不是常用的ip或者区域差异太大,就需要用户重新解锁或者输入密码等。
那么在常规的使用方式上,一方面在读取时需要设置Top 10的参数,另一方面就需要记录所有的登录ip信息,定期删除最近10次以外的数据,使用最大版本数后:
int timeToLive = -1; // 数据永不过期
int maxVersions = 10; //更新最大版本数为10.
TableOptions tableOptions = new TableOptions(timeToLive, maxVersions);
UpdateTableRequest request = new UpdateTableRequest(TABLE_NAME);// 更新表的最大版本数
//查询时设置一次查询出来的版本号
criteria.setMaxVersions(10);
GetRowResponse getRowResponse = client.getRow(new GetRowRequest(criteria));
代码参考
数据生命周期
数据多版本介绍完了,那么就会来带另外个问题,某个版本的数据我可以调用DeleteRow来删除,但是6个月之前的数据呢,总不能一条一条的删除吧?所以数据生命周期就登场了!
数据生命周期也就是表里面数据的存活时间,过时的数据就会被系统自动删掉,是不是既省钱又省事呢?
在工业监控、IoT设备数据、车联网、日志数据等时间序列的应用场景下,由于数据量巨大,只需要为应用或者设备保存最近3个月或者是半年的数据提供在线访问,更早的数据基本没有实时访问的需求,在这些数据的管理上数据生命周期就排上用场了!
接下来我们来看看数据过期的规则吧!
数据的诞生时间
表格存储会把每个属性列的版本号换算成毫秒后计算成距离1970-1-1 00:00:00 UTC的时间,并将该时间作为该个版本数据的诞生时间,比如:
- 版本号为1468944000000,该版本的数据诞生时间就为2016-07-20 00:00:00
- 版本号为1468944000,该版本的数据诞生时间就为1970-01-18 08:02:24
进行计算时,会先除以1000哦,原因是版本号是以毫秒为单位的。
数据的过期时间
当数据的诞生时间距离当前时间超过了TTL,那么这个版本的数据就过期了。
换句话说就是当前的时间换算成毫秒后减去该数据的版本号大于数据生命周期时,该数据就被认为是过期数据,继续举例说明:
数据生命周期为86400(一天),也就是数据只保留一天,写入的数据版本为: 1468944000000 即2016-07-20 00:00:00 。
过了 2016-07-21 00:00:00 之后,该数据就是过期数据了,我们将不再能读出这个版本的数据,并且表格系统后台将会启动清理任务,对过期数据进行清理。
计算逻辑:
1. 当前时间2016-07-21 00:00:01 换算为毫秒的时间戳为x,x=1469030401000
2. 数据的版本号y, y=1468944000000
3. ttl = 86400,换算成毫秒z,z=86400000
4. x-y = 86401000 > 86400000 ,该版本数据过期。
数据生命周期的注意事项
数据写入版本号要求
TTL为86400时,在2016-07-21 00:00:00之后写入版本号为1468944000000的数据,将会写入失败。原因是该条数据即使写成功,由于已经过期我们也无法读到这一个版本的数据,所以表格存储对过期的数据写入将会直接拒绝。因为:
- 写入时间t1 = 2016/07/21 00:00:01 (毫秒时间戳为:1469030401000)
- 写入的版本号为t2 = 1468944000000
- 数据生命周期 ttl = 86400 * 1000 = 86400000 (换算为毫秒)
- t1 - t2 = 86401000 > ttl,数据写入失败
调整TTL的数据读取行为
在使用过程汇总,我们会发现以下比较"奇怪"的行为:
TTL=172800, 查看时间:2016-09-10 15:43:19 一个属性列原始数据:
- ts=1473332944000(2016/09/08 19:09:04),value=a
- ts=1473339339000(2016/09/08 20:55:39),value=b
- ts=1473408233000(2016/09/09 16:03:53),value=c
- ts=1473452389000(2016/09/10 04:19:49),value=d
为了方便阅读,括号内为根据时间戳换算的字符串格式时间。
当我们将该张表TTL调整为86400时,读取所有的数据发现:
- ts=1473408233000(2016/09/09 16:03:53),value=c
- ts=1473452389000(2016/09/10 04:19:49),value=d
只能读到两个版本的数据,4个版本的数据中只有这两个版本号是在一天以内的,符合预期。
随后我们将该张表TTL调整回172800时,读取所有的数据发现:
- ts=1473339339000(2016/09/08 20:55:39),value=b
- ts=1473408233000(2016/09/09 16:03:53),value=c
- ts=1473452389000(2016/09/10 04:19:49),value=d
只读到了3个版本的数据,并不是最初4个版本数据,说明版本数据 ts=1473332944000,value=a已经被系统回收。
有效版本偏差(MaxTimeDeviation)
经过了上面对多版本、最大版本数和数据生命周期的说明,是不是已经理解了他们的作用,但是有效版本偏差是有什么作用呢?
服务端在处理写请求时会对属性列的版本号进行检查,当版本号小于当前写入时间减去MaxTimeDeviation或者大于等于当前写入时间加上MaxTimeDeviation的值时,该行数据写入失败,换句话说就是在我们写入自定义的版本号时,我们写入的版本号需要在一个范围内才能写入成功。
这个有效范围就是:[数据写入时间-有效版本偏差,数据写入时间+有效版本偏差)
假设有效版本偏差为86400,在2016-07-21 00:00:00(毫秒时间戳为t0=1469030400000)写入数据时,数据的版本号就需要在下面的范围:[t1, t2)
- t1 = t0 - 86400000 = 1468944000000,即2016/07/20 00:00:00
- t2 = t0 + 86400000 = 1469116800000,即2016/07/22 00:00:00
也就是说写入的数据版本号需要在当前时间前后86400秒以内。
有效版本偏差作用
有效版本偏差的意义清楚了,但是这个功能的作用是什么呢? 且听我慢慢道来。
用户小A将数据表的属性设置为TTL=-1(数据永不过期),MaxVersions=100,在更新数据时,数据的版本号由程序从1开始累加,某个属性列更新了1000个版本,系统会保留最近的100个,版本号为[901,902,...999]。
但某天小A发现生命周期也挺不错的,想试试看,于是就使用UpdateTable接口将TTL设置成了86400,然后就惊讶的发现 所有的数据都读不出来了 ,于是想起来数据的过期规则,连忙将TTL设置回 -1 ,但是发现本应该存在的 100个版本 的数据只剩下了零散的 20个 ,这个时候,其他80个数据已经被系统回收删除了。
假如小A设置了MaxTimeDeviation为86400,版本号过小的数据写入都会失败,这样就避免了将TTL从-1设置为非0值而带来的大批数据过期情况的发生。
因为MaxTimeDeviation是一个非0值,所以如果需要写入诸如1、2这样的版本号,将MaxTimeDeviation设置为一个非常大的正值就可以啦,比如设置为1788856773(2026/09/08 16:39:33),在2026/09/08 16:39:33之前都可以成功的写入版本号为1的数据,当然,需要在TTL=-1的情况下,否者会因为ttl对数据版本号的要求,写入仍然会被系统拒绝哦~
关于更多表格存储的应用文章赶快戳这里吧!