2.3 你再也不能往核反应堆多加水了
歧义性语句是指存在不止一种语义的语句。换句话说,歧义性语句中的单词序列能够匹配多种语法结构。本节的标题“你再也不能往核反应堆多加水了”就是我在几年前的《周六夜现场》中看到的一个有歧义的句子。这句话让人不确定,是已经无法往核反应堆多加水了,还是不应该往核反应堆多加水。
![]()
出现在自然语言中的歧义句会显得非常滑稽,但是出现在基于计算机的语言类应用程序中的歧义就会带来很多问题。为了解释或者翻译一个词组,程序必须能够唯一地辨识出它的准确含义。这意味着,我们必须提供没有歧义的语法,使得ANTLR生成的语法分析器能够以单一方式匹配每个输入词组。
迄今为止,我们还没有深入了解ANTLR语法的细节,不过,接下来我们将通过一些有歧义的语法来阐明歧义性的含义。你可以在以后构建语法并遇到歧义问题的时候再来回顾本节。
比如一些语法的歧义是非常明显的:
大多数情况下,歧义的表现更为微妙。在下面的语法中,stat规则包含两个备选分支,二者都可以匹配一个函数调用语句。
下面的图显示了stat规则对输入文本“f();”的两种不同的解释: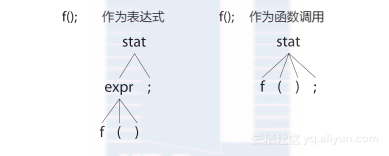
左边的语法分析树展示的是f()匹配expr规则的情况,右边的语法分析树展示的是f()匹配stat规则的第二个备选分支的情况。由于大多数语言的设计者都倾向于将语法设计成无歧义的,一个歧义性语法通常被认为是程序设计上的bug。我们需要重新组织语法,使得对于每个输入的词组,语法分析器都能够选择唯一匹配的备选分支。如果语法分析器检测到该词组存在歧义,它就必须在多个备选分支中做出选择。ANTLR解决歧义问题的方法是:选择所有匹配的备选分支中的第一条。在上面的例子中,ANTLR将会选择左边的语法分析树作为对输入文本“f();”的语义解释。
歧义问题在词法分析器和语法分析器中都会发生,ANTLR的解决方案使得对规则的解析能够正常进行。在词法分析器中,ANTLR解决歧义问题的方法是:匹配在语法定义中最靠前的那条词法规则。我们通过编程语言中常见的一种歧义——关键字和标识符规则的冲突——来说明这套机制是如何工作的。关键字begin同时也是一个标识符,至少从词法意义上来说是这样的。所以词法分析器可以使用以下任一词法规则来匹配字符序列“b-e-g-i-n”:
有关词法分析中歧义性的更多信息,请参阅5.5节中“匹配标识符”部分。要注意的是,词法分析器会匹配可能的最长字符串来生成一个词法符号,这意味着,输入文本beginner只会匹配上例中的ID这条词法规则。ANTLR词法分析器不会把它匹配为关键字BEGIN后跟着标识符ner。
有时候,一门语言的语法本身就存在歧义,无论如何修改语法也不能改变这一点。例如,常见的数学表达式1 + 2*3可以用两种方式解释,一种是自左向右地处理(Smalltalk就是这么做的),另外一种是像绝大多数编程语言一样,按照优先级来处理。我们将在5.4节中学习如何隐式地指定表达式中的运算符优先级。
经典的C语言向我们展示了另外一种歧义,我们可以通过包含标识符定义的上下文信息来解决这样的歧义问题。例如,对于代码片段“i*j;”,从句法角度看,它像是一个表达式,但是实际上它的实际含义,或者说语义,依赖于i是一个类型还是一个变量。如果i是一个类型的名字,那么这段代码就不是一个表达式,而是一个指向类型i的指针变量j的声明。我们将在第11章中解决这样的歧义问题。
语法分析器本身仅仅验证输入语句的合法性并建立一棵语法分析树。这是一项非常重要的工作,接下来,我们将了解一个语言类应用程序如何使用语法分析树来对输入文本进行语义分析和翻译。