原文出处:http://www.oschina.net/question/267865_48311
很好的一篇思考数据库设计的文章,有些规则在日常设计中有意无意的在违背,从而导致设计出不良的程序。转载,保存,并提醒自己,要做好数据库的设计。
总结:
- 规则 1:弄清楚将要开发的应用程序是什么性质的(OLTP 还是 OPAP)?
- 规则 2:将你的数据按照逻辑意义分成不同的块,让事情做起来更简单
- 规则 3:不要过度使用 “规则 2”
- 规则 4:把重复、不统一的数据当成你最大的敌人来对待
- 规则 5:当心被分隔符分割的数据,它们违反了“字段不可再分”
- 规则 6:当心那些仅仅部分依赖主键的列
- 规则 7:仔细地选择派生列
- 规则 8:如果性能是关键,不要固执地去避免冗余
- 规则 9:多维数据是各种不同数据的聚合
- 规则 10:将那些具有“名值表”特点的表统一起来设计
- 规则 11:无限分级结构的数据,引用自己的主键作为外键
- 简介
在您开始阅读这篇文章之前,我得明确地告诉您,我并不是一个数据库设计领域的大师。以下列出的11点是我对自己在平时项目实践和阅读中学习到的经验总结出来的个人见解。我个人认为它们对我的数据库设计提供了很大的帮助。实属一家之言,欢迎拍砖 : )
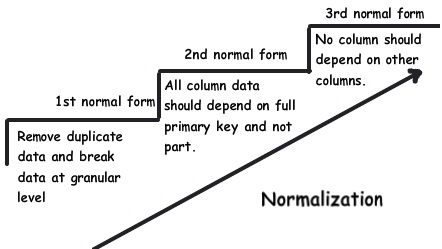
我之所以写下这篇这么完整的文章是因为,很多开发者一参与到数据库设计,就会很自然地把 “三范式” 当作银弹一样来使用。他们往往认为遵循这个规范就是数据库设计的唯一标准。由于这种心态,他们往往尽管一路碰壁也会坚持把项目做下去。
如果你对 “三范式” 不清楚,请点击这里(FQ)一步一步的了解什么是“三范式”。
大家都说标准规范是重要的指导方针并且也这么做着,但是把它当作石头上的一块标记来记着(死记硬背)还是会带来麻烦的。以下11点是我在数据库设计时最优先考虑的规则。
- 规则 1:弄清楚将要开发的应用程序是什么性质的(OLTP 还是 OPAP)?
当你要开始设计一个数据库的时候,你应该首先要分析出你为之设计的应用程序是什么类型的,它是 “事务处理型”(Transactional)
的还是 “分析型” (Analytical)的?你会发现许多开发人员采用标准化做法去设计数据库,而不考虑目标程序是什么类型的,这样做出来的程序很快就会陷入性能、客户定制化的问题当中。正如前面所说的,这里有两种应用程序类型,
“基于事务处理” 和 “基于分析”,下面让我们来了解一下这两种类型究竟说的是什么意思。事务处理型:这种类型的应用程序,你的最终用户更关注数据的增查改删(CRUD,Creating/Reading/Updating/Deleting)。这种类型更加官方的叫法是 “OLTP”
。
分析型:这种类型的应用程序,你的最终用户更关注数据分析、报表、趋势预测等等功能。这一类的数据库的 “插入” 和 “更新” 操作相对来说是比较少的。它们主要的目的是更加快速地查询、分析数据。这种类型更加官方的叫法是
“OLAP” 。
那么换句话说,如果你认为插入、更新、删除数据这些操作在你的程序中更为突出的话,那就设计一个规范化的表否则的话就去创建一个扁平的、不规范化的数据库结构。
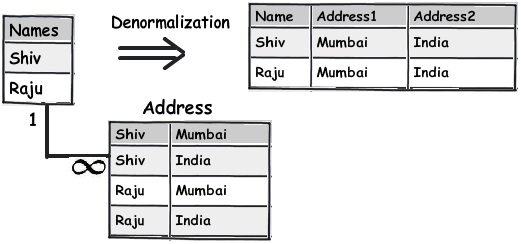
以下这个简单的图表显示了像左边Names和Address这样的简单规范化的表,怎么通过应用不规范化结构来创建一个扁平的表结构。
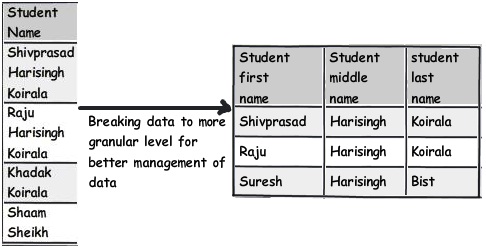
- 规则 2:将你的数据按照逻辑意义分成不同的块,让事情做起来更简单
这个规则其实就是 “三范式” 中的第一范式。违反这条规则的一个标志就是,你的查询使用了很多字符串解析函数
例如 substring、charindex等等。若真如此,那就需要应用这条规则了。比如你看到的下面图片上有一个有学生名字的表,如果你想要查询学生名字中包含“Koirala”,但不包含“Harisingh”的记录,你可以想象一下你将会得到什么样的结果。
所以更好的做法是将这个字段拆分为更深层次的逻辑分块,以便我们的表数据写起来更干净,以及优化查询。
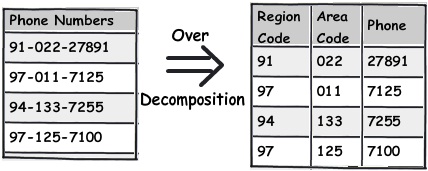
- 规则 3:不要过度使用 “规则 2”
开发者都是一群很可爱的生物。如果你告诉他们这是一条解决问题的正路,他们就会一直这么做下去,做到过了头导致了一些不必要的后果。这也可以应用于我们刚刚在前面提到的规则2。当你考虑字段分解时,先暂停一下,并且问问你自己是否真的需要这么做。正如所说的,分解应该是要符合逻辑的。
例如,你可以看到电话号码这个字段,你很少会把电话号码的ISD代码单独分开来操作(除非你的应用程序要求这么做)。所以一个很明智的决定就是让它保持原样,否则这会带来更多的问题。
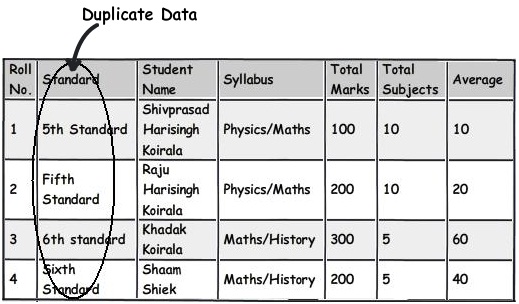
- 规则 4:把重复、不统一的数据当成你最大的敌人来对待
集中那些重复的数据然后重构它们。我个人更加担心的是这些重复数据带来的混乱而不是它们占用了多少磁盘空间。
例如下面这个图表,你可以看到 "5th Standard" 和 "Fifth standard" 是一样的意思,它们是重复数据。现在你可能会说是由于那些录入者录入了这些重复的数据或者是差劲的验证程序没有拦住,让这些重复的数据进入到了你的系统。现在,如果你想导出一份将原本在用户眼里十分困惑的数据显示为不同实体数据的报告,该怎么做呢?
解决方法之一是将这些数据完整地移到另外一个主表,然后通过外键引用过来。在下面这个图表中你可以看到我们是如何创建一个名为 “Standards”(课程级别) 的主表,然后同样地使用简单的外键连接过去。
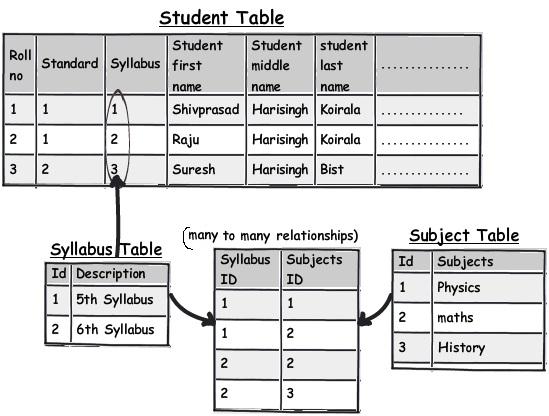
- 规则 5:当心被分隔符分割的数据,它们违反了“字段不可再分”
前面的规则2即“第一范式”说的是避免 “重复组” 。下面这个图表作为其中的一个例子解释了 “重复组”是什么样子的。如果你仔细的观察 syllabus(课程) 这个字段,会发现在这一个字段里实在是填充了太多的数据了。像这些字段就被称为 “重复组” 了。如果我们又得必须使用这些数据,那么这些查询将会十分复杂并且我也怀疑这些查询会有性能问题。
这些被塞满了分隔符的数据列需要特别注意,并且一个较好的办法是将这些字段移到另外一个表中,使用外键连接过去,同样地以便于更好的管理。那么,让我们现在就应用规则2(第一范式) “避免重复组” 吧。你可以看到上面这个图表,我创建了一个单独的 syllabus(课程) 表,然后使用 “多对多” 关系将它与 subject(科目) 表关联起来。
通过这个方法,主表(student表)的 syllabus(课程) 字段就不再有重复数据和分隔符了。
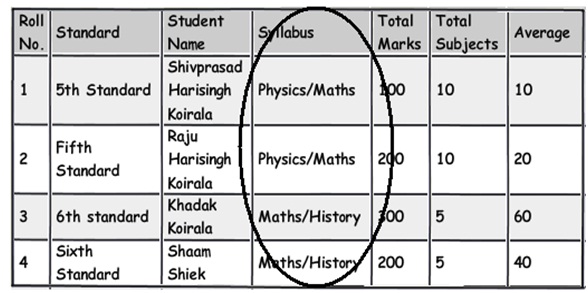
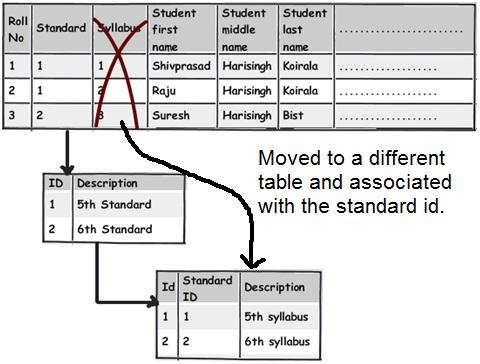
- 规则 6:当心那些仅仅部分依赖主键的列
留心注意那些仅仅部分依赖主键的列。例如上面这个图表,我们可以看到这个表的主键是 Roll No.+Standard
。现在请仔细观察 syllabus 字段,可以看到 syllabus(课程) 字段仅仅关联(依赖) Standard(课程级别) 字段而不是直接地关联(依赖)某个学生(Roll No. 字段)。Syllabus(课程) 字段关联的是学生正在学习的哪个课程级别(Standard字段)而不是直接关联到学生本身。那如果明天我们要更新教学大纲(课程)的话还要痛苦地为每个同学也修改一下,这明显是不符合逻辑的(不正常的做法)。更有意义的做法是将这些字段从这个表移到另外一个表,然后将它们与 Standard(课程级别)表关联起来。
你可以看到我们是如何移动 syllabus(课程)字段并且同样地附上 Standard 表。
这条规则只不过是 “三范式” 里的 “第二范式”:“所有字段都必须完整地依赖主键而不是部分依赖”。
- 规则 7:仔细地选择派生列
如果你正在开发一个 OLTP 型的应用程序,那强制不去使用派生字段会是一个很好的思路,除非有迫切的性能要求,比如经常需要求和、计算的 OLAP 程序,为了性能,这些派生字段就有必要存在了。
通过上面的这个图表,你可以看到 Average 字段是如何依赖 Marks 和 Subjects 字段的。这也是冗余的一种形式。因此对于这样的由其他字段得到的字段,需要思考一下它们是否真的有必要存在。
这个规则也被称为 “三范式” 里的第三条:“不应该有依赖于非主键的列” 。 我的个人看法是不要盲目地运用这条规则,应该要看实际情况,冗余数据并不总是坏的。如果冗余数据是计算出来的,看看实际情况再来决定是否应用这第三范式。
- 规则 8:如果性能是关键,不要固执地去避免冗余
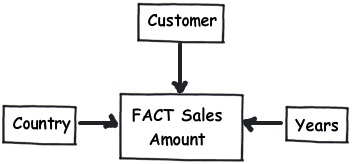
不要把 “避免冗余” 当作是一条绝对的规则去遵循。如果对性能有迫切的需求,考虑一下打破常规。常规情况下你需要做多个表的连接操作,而在非常规的情况下这样的多表连接是会大大地降低性能的。 - 规则 9:多维数据是各种不同数据的聚合
OLAP 项目主要是解决多维数据问题。比如你可以看看下面这个图表,你会想拿到每个国家、每个顾客、每段时期的销售额情况。简单的说你正在看的销售额数据包含了三个维度的交叉。
为这种情况做一个实际的设计是一个更好的办法。简单的说,你可以创建一个简单的主要销售表,它包含了销售额字段,通过外键将其他所有不同维度的表连接起来。
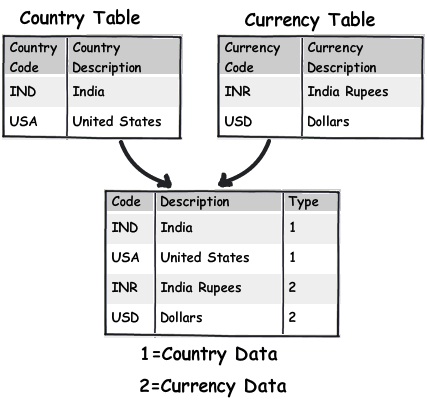
- 规则 10:将那些具有“名值表”特点的表统一起来设计
很多次我都遇到过这种 “名值表” 。 “名值表” 意味着它有一些键,这些键被其他数据关联着。比如下面这个图表,你可以看到我们有 Currency(货币型)和 Country(国家)这两张表。如果你仔细观察你会发现实际上这些表都只有键和值。
对于这种表,创建一个主要的表,通过一个 Type(类型)字段来区分不同的数据将会更有意义。 - 规则 11:无限分级结构的数据,引用自己的主键作为外键
我们会经常碰到一些无限父子分级结构的数据(树形结构?)。例如考虑一个多级销售方案的情况,一个销售人员之下可以有多个销售人员。注意到都是 “销售人员” 。也就是说数据本身都是一种。但是层级不同。这时候我们可以引用自己的主键作为外键来表达这种层级关系,从而达成目的。
这篇文章的用意不是叫大家不要遵循范式,而是叫大家不要盲目地遵循范式。根据你的项目性质和需要处理的数据类型来做出正确的选择。







英文原文,OSChina原创翻译。